-
JAVA集合概述
集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类。所有的集合类的都在java.util包下。
集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量);而集合只能保存对象。
Java的集合类主要由Collections和Map,Collections和Map是Java集合框架的根接口,Java中集合的继承关系如下:
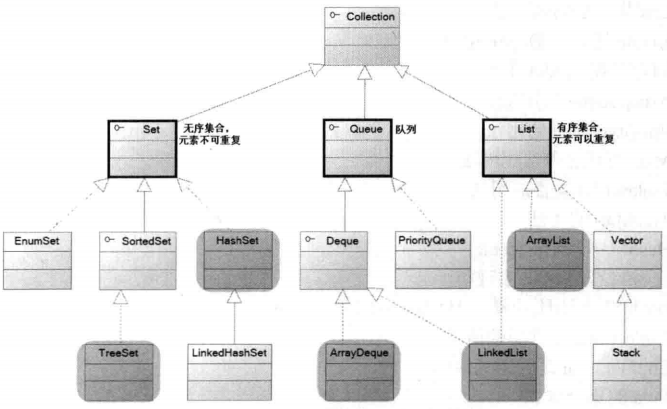
Collection集合列的继承关系
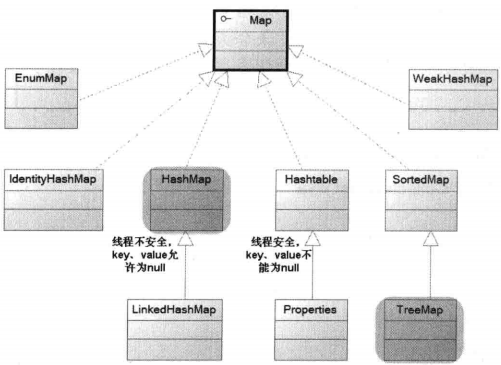
Map接口的继承关系
2、Collection接口和Iterator接口
一、Collection接口
collection接口是List、set和Queue接口的父接口,该接口里定义的方法可用于操作Set集合。并且所有的Collection实现类都重写了toString()方法.
遍历集合的两种方法:
- 使用lamdba遍历
1 public class CollectionEach{ 2 public static void main(String[] args){ 3 Collection readBooks=new HashSet(); 4 readBooks.add("Java 多线程边编程的艺术"); 5 readBooks.add("Java编程思想"); 6 readBooks.add("简洁之道"); 7 readBooks.add("Effective Java"); 8 readBooks.add("程序员职业素养"); 9 readBooks.foreach(ele->System.out.println("迭代集合元素:"+ele)); 10 } 11 }
在java8中Iterable接口新增了一个forEach(Consumser action)方法,而Iterable接口是Collection接口的父接口,因此Collection集合也可直接调用该方法。
2.使用Java8增强Iterator遍历集合
package com.ynu.java.learn.base.MutilThread;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
/**
* @author root
*
*/
public class IteratorTest
{
/**
* @param args
*/
public static void main(String[] args)
{
// TODO Auto-generated method stub
Collection<String> books = new HashSet<>();
books.add("明朝那些事");
books.add("三国演义!");
books.add("水浒传!");
books.add("Java编程思想");
Iterator<String> it = books.iterator();
while (it.hasNext())
{
// it.next()方法返回的数据类型是Object类型,因此需要强制类型转换
String book = it.next();
System.out.println(book);
if (book.equals("三国演义!"))
{
it.remove();
}
// 对book变量赋值,不会改变集合元素本身
book = "测试字符串";
}
System.out.println(books);
}
}
当使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,因此修改迭代变量的值对集合元素本身没有任何影响。
当使用Iterator迭代访问Collection集合元素时,不能使用Collection对象修改Collection集合里的元素,但是可以使用Iterator的remove()方法删除上一次next()方法返回集合元素,否则将会引发java.util.Concurrent.ModificationException异常。
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
/**
* @author root
*
*/
public class IteratorTest
{
/**
* @param args
*/
public static void main(String[] args)
{
// TODO Auto-generated method stub
Collection<String> books = new HashSet<>();
books.add("明朝那些事");
books.add("三国演义!");
books.add("水浒传!");
books.add("Java编程思想");
Iterator<String> it = books.iterator();
while (it.hasNext())
{
// it.next()方法返回的数据类型是Object类型,因此需要强制类型转换
String book = it.next();
System.out.println(book);
if (book.equals("三国演义!"))
{
books.remove("三国演义!");
}
// 对book变量赋值,不会改变集合元素本身
book = "测试字符串";
}
System.out.println(books);
}
}
使用Java8新增的Predicate操作集合
Java 8为Collection集合新增了removeIf(Predicate filter)方法,该方法将会批量删除符合条件的filter条件的所有元素。示例如下:
import java.util.Collection;
import java.util.HashSet;
/**
* @author root
*
*/
public class PredicateTest
{
/**
* @param args
*/
public static void main(String[] args)
{
// TODO Auto-generated method stub
Collection<String> books = new HashSet<>();
books.add(new String("轻量级Java EE企业应用实战"));
books.add(new String("疯狂Java讲义"));
books.add(new String("疯狂iOS讲义"));
books.add(new String("疯狂Ajax讲义"));
books.add(new String("疯狂Android讲义"));
System.out.println(books);
// 使用lambda表达式(目标类型是Predicate)过滤集合
books.removeIf(ele -> ele.length() < 10);
System.out.println(books);
}
}
Predicate使用示例2:
import java.util.Collection;
import java.util.HashSet;
import java.util.function.Predicate;
/**
* @author root
*
*/
public class PredicateTest2
{
/**
* @param args
*/
public static void main(String[] args)
{
// TODO Auto-generated method stub
Collection<String> books = new HashSet<>();
books.add("Java编程思想");
books.add("Java疯狂讲义");
books.add("代码整洁之道_程序员的职业素养");
books.add("java并发编程的艺术");
books.add("TensorFlow 实战深度学习框架");
books.add("人际关系与沟通");
books.add("Effective java");
books.add("代码整洁之道");
books.add("TensorFlow实战");
// 统计书名包含"Java"子串的图书数量
System.out.println(calAll(books, ele -> ((String) ele).contains("Java")));
// 统计书名包含"疯狂"子串的图书数量
System.out.println(calAll(books, ele -> ((String) ele).contains("疯狂")));
// 统计书名字符长度大于10的图书数量
System.out.println(calAll(books, ele -> ((String) ele).length() > 10));
}
/**
* @param books
* @param object
* @return
*/
private static int calAll(Collection<String> books, Predicate p)
{
// TODO Auto-generated method stub
int total = 0;
for (Object obj : books)
{
if (p.test(obj))
{
total++;
}
}
return total;
}
}
使用java 8 新增的Stream操作集合
Java8新增了Stream、IntStream、LongStream、DoubleStream等流式API,这些API代表了多个支持串行和并行聚集操作的元素,其中Stream是一个通用的流接口,而IntStream、LongStream、DoubleStream则代表了类型为int,long,double的流。
独立使用Stream的步骤如下:
1、使用Stream或XxxStream的builder()类方法创建该Stream对应的Builder。
2、重复调用Builder的add()方法向该流中的添加多个元素
3、调用Builder的build()方法获取对应的Stream
4、调用Stream的聚集方法。
package com.edu.ynu.java.learn.collection;
import java.util.stream.IntStream;
public class IntStreamTest
{
public static void main(String[] args)
{
IntStream is = IntStream.builder().add(12).add(23).add(-2).add(4).build();
//下面调用聚集方法的代码每次只能执行一次
/* System.out.println("is所有元素的最大值:" + is.max().getAsInt());
System.out.println("is所有元素的最小值:" + is.min().getAsInt());
System.out.println("is所有元素的总和:" + is.sum());
System.out.println("is所有元素的总数:" + is.count());
System.out.println("is所有元素的平均值:" + is.average());
System.out.println("is所有元素的平方是否都大于20:" + is.allMatch(ele -> ele * ele > 20));
System.out.println("is是否包含任何元素的平法大于20:" + is.anyMatch(ele -> ele * ele > 20));*/
//将is映射成一个新的Stream,新Stream的每个元素是原Stream元素的2倍+1
IntStream newIs = is.map(ele -> ele * 2 + 1);
//使用方法引用的方式来遍历集合元素
newIs.forEach(System.out::println);
}
}
在Stream中方法分为两类中间方法和末端方法
- 中间方法:中间操作允许流保持打开状态,并允许直接调用后续方法。上面程序中的map()方法就是中间方法。
- 末端方法:末端方法是对流的最终操作。当对某个Stream执行末端方法后,该流将会被"消耗"且不再可用。上面程序中的sum()、count()、average()等方法都是末端方法。
除此之外,关于流的方法还有如下特征:
- 有状态的方法:这种方法会给你流增加一些新的属性,比如元素的唯一性、元素的最大数量、保证元素的排序的方式被处理等。有状态的方法往往需要更大的性能开销
短路方法:短路方法可以尽早结束对流的操作,不必检查所有的元素。
import java.util.Collection; import java.util.HashSet; public class CollectionStream { public static void main(String[] args) { Collection books = new HashSet(); books.add("Java并发编程的艺术"); books.add("Effective java 中文版"); books.add("代码整洁之道"); books.add("深度学习、优化与识别"); books.add("代码整洁之道_程序员的职业素养"); books.add("人际关系与沟通"); books.add("TensorFlow实战"); books.add("TensorFlow实战Google深度学习框架"); books.add("明朝那些事"); //统计书名包含"码"子串的图书数量 System.out.println(books.stream().filter(ele -> ((String) ele).contains("码")).count()); //统计书名包含"java"子串的图书数量 System.out.println(books.stream().filter(ele -> ((String) ele).contains("Java")).count()); //统计书名字符串长度大于10的图书数量 System.out.println(books.stream().filter(ele -> ((String) ele).length() > 10).count()); //先调用Collection对象的stream()方法将集合转换为Stream //再调用Stream的mapToInt()方法获取原有的Stream对应的IntStream books.stream().mapToInt(ele -> ((String) ele).length()).forEach(System.out::println); } }
Set集合
HashSet
HashSet是Set接口的典型的实现。HashSet按Hash算法来存储集合中的元素。在存取和查找上有很好的性能。
HashSet具有以下特点:
1、不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
2、HashSet不是同步的,必须通过代码来保证其同步。
3、集合元素可以是null.
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该hashCode值决定该对象在HashSet中存储的位置。
如果有两个元素通过equals()方法比较返回true,但它们的hashCode()方法返回值不相等,hashSet将会把它们存储在不同位置,依然可以添加成功。如果两个对象的hashCode()方法返回的hashCode值相同,当它们的equals()方法返回false时,会在hashCode所在位置采用链式结构保存多个对象。这样会降低hashSet的查询性能。
综上所述:HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个hashCode()方法的返回值也相等。
在使用HashSet中重写hashCode()方法的基本原则
1、在程序运行过过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
2、当两个对象的equals()方法比较返回true时,这个两个对象的hashCode()方法返回相同的值。
3、对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值。
- 把对象内的每个意义的实例变量(即每个参与equals()方法比较标准的实例变量)计算出一个int类型的hashCode值。
| 实例变量类型 | 计算方式 |
| boolean | hashCode=(f?0:1); |
| 整数类型(byte、short、char、int) | hashCode=(int)f; |
| long | hashCode=(int)(f^(f>>>32)); |
| float | hashCode=Float.floattoIntBits(f); |
| double | long l=Double.doubleToLongBits(f); hashCode=(int)(I^(I>>>32)); |
| 引用类型 |
2.用第1步计算出来的多个hashCode值组合计算出一个hashCode值返回
1 return f1.hashCode()+(int)f2;
为了避免直接相加产生的偶然相等(两个对象的f1、f2实例变量并不相等,但他们的hashCode的和恰好相等),可以通过为各个实例变量的hashCode值乘以一个质数后再相加
1 return f1.hashCode()*19+f2.hashCode()*37;
如果向HashSet中添加一个可变的对象后,后面的程序修改了该可变对想的实例变量,则可能导致它与集合中的其他元素的相同(即两个对象的equals()方法比较返回true,两个对象的hashCode值也相等),这就有可能导致HashSet中包含两个相同的对象。

1 import java.util.HashSet;
2 import java.util.Iterator;
3
4 public class HashTest2
5 {
6 public static void main(String[] args)
7 {
8 HashSet hs = new HashSet();
9 hs.add(new R(5));
10 hs.add(new R(-3));
11 hs.add(new R(-9));
12 hs.add(new R(15));
13 //打印HashSet集合,集合 元素没有重复
14 System.out.println(hs);
15 //取出第一个元素
16 Iterator it = hs.iterator();
17 R first = (R) it.next();
18 System.out.println(first.count);
19 // 为第一个元素的count实例变量赋值
20 first.count = -3;
21 System.out.println(hs);
22 //删除count为-3的R对象
23 hs.remove(new R(-3));
24 //可以看到被删除了一个R元素
25 System.out.println(hs);
26 System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-3))); //输出false
27 System.out.println("hs是否包含count为-2的R对象?" + hs.contains(new R(-2))); //输出false
28 }
29 }
30
31 class R
32 {
33 int count;
34
35 public R(int count)
36 {
37 this.count = count;
38 }
39
40 public String toString()
41 {
42 return "R[count:" + count + "]";
43 }
44
45 public boolean equals(Object obj)
46 {
47 if (this == obj)
48 {
49 return true;
50 }
51 if (obj != null && obj.getClass() == R.class)
52 {
53 R r = (R) obj;
54 return this.count == r.count;
55 }
56 return false;
57 }
58
59 public int hashCode()
60 {
61 return this.count;
62 }
63 }

程序运行的结果
[R[count:-3], R[count:5], R[count:-9], R[count:15]] -3 [R[count:-3], R[count:5], R[count:-9], R[count:15]] [R[count:5], R[count:-9], R[count:15]] hs是否包含count为-3的R对象?false hs是否包含count为-2的R对象?false
对于上述代码的解释,在执行
System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-3)));
时,首先去查找HashSet中通过-3计算得出的元素的位置,这里元素为-3已经删除了,所以找不到数值为-3的元素的值
对于执行
System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-2)));
时,因为通过后面的修改的已经将z值为-2的元素对应的hashCode的元素的值改为-3,也就是说找到了对应的HashCode对应位置的上的元素,但是元素对应的值与-2不相等,所以返回也为false
LinkedHashSet
LinkedHashSet集合也是根据hashCode值据决定元素的存储位置的,但它同时使用链表维护元素的次序,存储的顺序是元素插入的顺序。
LinkedHashSet需要维护元素的插入的顺序,因此性能略低于HashSet的性能,但在迭代方位Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
1 import java.util.LinkedHashSet; 2 3 public class LinkedHashSetTest 4 { 5 public static void main(String[] args) 6 { 7 LinkedHashSet books = new LinkedHashSet(); 8 books.add("疯狂Java讲义"); 9 books.add("轻量级Java EE企业应用实战"); 10 books.add("Java并发编程的艺术"); 11 String a = null; 12 books.add(a); 13 System.out.println(books); 14 15 // 删除 疯狂Java讲义 16 books.remove("疯狂Java讲义"); 17 // 重新添加 疯狂Java 讲义 18 books.add("疯狂Java讲义"); 19 System.out.println(books); 20 } 21 }
TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以保证集合元素处于排序状态
1 package com.edu.ynu.java.learn.collection; 2 3 import java.util.TreeSet; 4 5 public class TreeSetTest 6 { 7 public static void main(String[] args) 8 { 9 TreeSet nums = new TreeSet(); 10 nums.add(15); 11 nums.add(20); 12 nums.add(-1); 13 nums.add(-19); 14 // 输出集合元素,看到集合元素已经处于排序状态 15 System.out.println(nums); 16 // 输出集合中的第一个元素 17 System.out.println(nums.first()); 18 // 输出集合中最后一个元素 19 System.out.println(nums.last()); 20 // 返回小于4的子集,不包含4 21 System.out.println(nums.headSet(2)); 22 // 返回大于5的子集 23 System.out.println(nums.tailSet(3)); 24 // 返回大于等于-6,小于4的子集 25 System.out.println(nums.subSet(-6, 4)); 26 } 27 }
TreeSet采用红黑树的数据结构来存储集合元素
TreeSet支持两种的排序方法:自然排序和定制排序,在默认的情况下,TreeSet采用自然排序
1、自然排序
TreeSet会调用集合元素的compareTo(Oject obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列
如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable接口,否则程序将会抛出异常
1 class Err{} 2 public class TreeSetErrorTest 3 { 4 public static void main(String[] args){ 5 TreeSet ts=new TreeSet(); 6 ts.add(new Err()); 7 ts.add(new Err()); 8 } 9 }
上述代码没有实现的Comparable接口,则会引发ClassCastException异常。
向TreeSet中添加的应该是同一类的对象否则也会引发ClassCastException异常。
对于TreeSet集合而言,它判断两个对象的是否相等的唯一标准是:两个对象的通过compareTo(Object obj)方法比较是否返回0--如果通过compareTo(Object obj)方法比较返回0,TreeSet则会认为它们相等,否则认为它们不相等。