题目:
ArrayList list = new ArrayList(20);中的list扩充几次() A 0 B 1 C 2 D 3
答案:A
大家都知道默认ArrayList的长度是10个,所以如果你要往list里添加20个元素肯定要扩充一次(扩充为原来的1.5倍),但是这里显示指明了需要多少空间,所以就一次性为你分配这么多空间,也就是不需要扩充了。
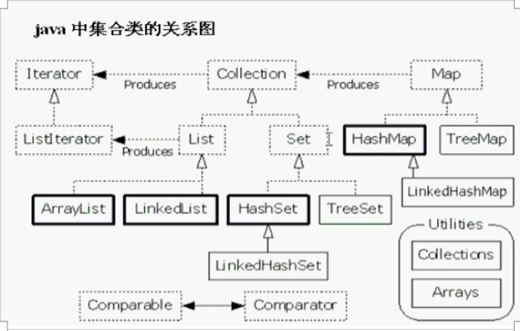
集合和数组的区别:
1.集合的长度是可变的,通过底层的数组拷贝方法,实现不断的增长,只能存储引用数据类型 ,但是可以通过包装类来实现存储数据类型。
2.数组长度是固定的,可以存储基本数据类型,也可以存储引用数据类型。
Iterable接口是Collection的父接口。
例子1:
//迭代器的由来 ArrayList<Person> list=new ArrayList<>(); list.add(new Person("黑人",35)); list.add(new Person("白人",25)); list.add(new Person("黄人",28)); /* Object[] array = list.toArray(); for (int i = 0; i < array.length; i++) { Person p=(Person) array[i]; System.out.println(p.getName()+"..."+p.getAge()); //这种方式的不方便 从而引出了迭代器 }*/ /*Iterator it=list.iterator(); while(it.hasNext()){ Person p=(Person)it.next(); System.out.println(p.getName()+"..."+p.getAge()); //同样的 这种还必须进行强转 也是不方便 于是引出了泛型机制 }*/ Iterator<Person>it=list.iterator(); while(it.hasNext()){ Person p=it.next(); System.out.println(p.getName()+"..."+p.getAge()); }
例子2:
public class Test02 { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("0"); list.add("d"); list.add("9"); list.add("3"); deleteNum(list); Iterator<String> it = list.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } private static void deleteNum(List<String> list) { /*for (int i = 0; i < list.size(); i++) { String s = (String) list.get(i); char[] arr = s.toCharArray(); for (int j = 0; j < arr.length; j++) { if (arr[j] >= '0' && arr[j] <= '9') { list.remove(i); break; // 这里为什么要用break? // 删除集合元素会遇到的问题 当删除元素后 // 集合长度会变短 但是指针还在原来的位置 // 所以会越过一些元素 没有遍历到 所以需要i-- 把指针拨回一格 // 这是集合用for循环删除的弊端 用迭代器就不会 } }*/ Iterator<String> it=list.iterator(); while(it.hasNext()){ String ss=(String)it.next(); for(Integer x=0;x<10;x++){ String s=x.toString(); if(ss.contains(s)){ it.remove();
break; } } } } }
不同遍历方式删除的不同之处:
普通for循环:
可以删除,但是索引要--,因为一旦删除,后面集合元素会向前移动,填补空缺位置。
迭代器:
可以删除,但是必须使用迭代器自身的remove方法,否则会出现并发修改异常。
增强for循环:
不能删除,否则会报并发修改异常,因为其底层依赖的是迭代器。
单列集合:
Collection(有序)—可重复:
1.ArrayList(数组结构):查询快。
2.LinkedList(链表结构):增删快。
相对于ArrayList,LinkedList的插入,添加,删除操作速度更快。
因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
Set(无序)—不可重复:
1.HashSet(哈希算法):哈希算法提高了去重复的效率,降低了使用equals()比较的次数。当你键盘录入字符串的时候,相同的字符串的算法地址值就固定了,所以不要奇怪,排序是按哈希表来排的。
保证唯一性:建议重写hashCode和equals方法。
2.TreeSet(二叉树结构),排序方式分为:
a.自然排序:让元素自身具备比较性,实现Comparable接口,重写compareTo方法。
保证唯一性(compareTo):就是参考比较方法的结果是否为0,如果return 0,视为两个对象重复,不存。返回-1集合会将存储的元素倒序,返回1集合会如何存就如何取。
public int compareTo(Person o){ int num=this.age-o.age; //年龄是比较的主要条件 return num==0?this.name.compareTo(o.name) : num; //姓名是比较的次要条件 }
b.比较器排序:让集合自身具备比较性,实现Comparator接口的比较器,重写compare方法。并将该类对象作为实际参数传递给TreeSet集合的构造函数(即匿名内部类的方式)。
TreeSetts=new TreeSet<>(new Comparator () { @Override public int compare(Employee e1, Employee e2) { int num=e2.getSalary()-e1.getSalary(); //先比较工资 从高到低 int age = num==0?e1.getAge()-e2.getAge():num; //相同就比较年龄 从小到大 int name = age==0?e1.getName().compareTo(e2.getName()):age; //再相同就比较名字 按字典顺序 return name==0?1:name; } });
双列集合:
Map(没有迭代器):
要保证Map集合中键的唯一性。
把map集合转成set的方法:
1.Set keyset(); //获取所有的键。
2.Set entrySet();//取的是键和值的映射关系。
------------------------------------------------------------------------------------------------------------------------------
取出map集合中所有元素的方式一:keySet()方法。
可以将map集合中的键都取出存放到set集合中。对set集合进行迭代。迭代完成,再通过get方法对获取到的键进行值的获取。
Set keySet = map.keySet();
Iterator it = keySet.iterator();
while(it.hasNext()) {
Object key = it.next();
Object value = map.get(key);
System.out.println(key+":"+value);
}
取出map集合中所有元素的方式二:entrySet()方法。
Set entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = (Map.Entry)it.next();
System.out.println(me.getKey()+"::::"+me.getValue());
}
------------------------------------------------------------------------------------------------------------------------------
补充:存储重复键
1.IdentityHashMap(可以存储重复键的集合 用法罕见),在IdentityHashMap中,是判断key是否为同一个对象,而不是普通HashMap的equals方式判断。
IdentityHashMap类利用哈希表实现Map接口,比较键(和值)时使用引用相等性代替对象相等性。该类不是通用 Map 实现!
2.HashMap也可以存储重复建(数字),不过只针对两个键,一个用String类型存入,一个用Integer存入-->局限性很大。
3.TreeMap用比较器,要想直接存入重复的键的话,只能通过entrySet()方法,keySet()方法不行,
因为它的getkey()方法底层依靠的是compareTo来确定如何获取键值的。
例子:
//键唯一性问题 public class Test01 { // 所谓的Map集合中键要保持唯一性 针对的就是keySet()这个方法 // 而entrySet()获取的是键值对对象 绕过了这个限制 public static void main(String[] args) { TreeMap<String, Integer> ts = new TreeMap<>(new Comparator<String>() { @Override public int compare(String s1, String s2) { int num = s1.compareTo(s2); return num == 0 ? 1 : num; } }); ts.put("a", 1); ts.put("b", 2); ts.put("c", 3); ts.put("c", 3); /* * Set<String> keySet = ts.keySet(); Iterator<String>it=keySet.iterator(); * while(it.hasNext()){ String key=it.next(); * System.out.println(key+"="+ts.get(key)); */ // 这里不能用keySet只能用entrySet // 因为keySet里面的getkey()方法底层是根据ComparaTo来确定如何获取键值的 Set<Entry<String, Integer>> entrySet = ts.entrySet(); Iterator<Entry<String, Integer>> it = entrySet.iterator(); while (it.hasNext()) { Entry<String, Integer> en = it.next(); String key = en.getKey(); Integer value = en.getValue(); System.out.println(key + "=" + value); } } }
HashMap和Hashtable有什么区别?
不同点:
1.HashMap允许键和值是null,而Hashtable不允许键或者值是null。
2.Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
3.HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。
java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。
快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。