前言:终于到了疯狂学习数据结构的时候,换个好看的题图,开始吧..
数组
什么是数组?
数组简单来说就是将所有的数据排成一排存放在系统分配的一个内存块上,通过使用特定元素的索引作为数组的下标,可以在常数时间内访问数组元素的这么一个结构;

为什么能在常数时间内访问数组元素?
为了访问一个数组元素,该元素的内存地址需要计算其距离数组基地址的偏移量。需要用一个乘法计算偏移量,再加上基地址,就可以获得某个元素的内存地址。首先计算元素数据类型的存储大小,然后将它乘以元素在数组中的索引,最后加上基地址,就可以计算出该索引位置元素的地址了;整个过程可以看到需要一次乘法和一次加法就完成了,而这两个运算的执行时间都是常数时间,所以可以认为数组访问操作能在常数时间内完成;
数组的优点
- 简单且易用;
- 访问元素快(常数时间);
数组的缺点
- 大小固定:数组的大小是静态的(在使用前必须制定数组的大小);
- 分配一个连续空间块:数组初始分配空间时,有时候无法分配能存储整个数组的内存空间(当数组规模太大时);
- 基于位置的插入操作实现复杂:如果要在数组中的给定位置插入元素,那么可能就会需要移动存储在数组中的其他元素,这样才能腾出指定的位置来放插入的新元素;而如果在数组的开始位置插入元素,那么这样的移动操作开销就会很大。
关于数组的一些问题思考
1)在索引没有语义的情况下如何表示没有的元素?
我们创建的数组的索引可以有语义也可以没有语义,比如我现在只是单纯的想存放100,98,96这三个数字,那么它们保存在索引为0,1,2的这几个地方或者其他地方都可以,无论它们之间的顺序怎样我都不关心,因为它们的索引是没有语义的我只是想把它们存起来而已;但是如果它们变成了学号为1,2,3这几个同学对应的成绩,那么它们的索引就有了语义,索引0对应了学号为1的同学的成绩,索引1对应了学号2的同学,索引2对应了学号3的同学,因为数组的最大的优点是访问元素是在常数时间,所以我们使用数组最好就是在索引有语义的情况下;
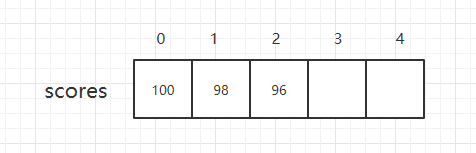
好了,那么如果在索引没有语义的情况下,我们如何表示没有的元素呢?例如上图中,对于用户而言,访问索引为3和4的数组元素是违法的,因为它们根本就不存在,我们如何表示没有的元素呢?
表示为0或者-1?
2)如何添加元素和删除元素呢?
我们知道,数组的明显缺点是在创建之前需要提前声明好要使用的空间,那么当我们空间满了该如何处理呢?又该如何删除元素呢?在Java中提供给我们的默认数组是不支持这些功能的,我们需要开发属于自己的数组类才行;
使用泛型封装自己的数组类
我们需要自己创建一个Array类,并实现一些增删改查的功能,大体的结构如下:
public class Array<E>{
private E[] data;
private int size;
/* 一些成员方法 */
}我们需要一个成员变量来保存我们的数据,这里是data,然后需要一个int类型来存放我们的有效元素的个数,在这里我们没有必要再多定义一个表示数组空间的变量,因为这里的空间大小就是data.length;
默认的构造函数
我们需要创建一些方法来初始化我们的数组,那肯定是需要传一个capacity来表示数组的容量嘛:
// 构造函数,传入数组的容量capacity构造Array
public Array(int capacity) {
data = (E[]) new Object[capacity];
size = 0;
}当然我们也需要创建一个默认的构造函数来为不知道初始该定义多少的用户一个默认大小的数组:
// 无参数的构造函数,默认数组的容量capacity=10
public Array() {
this(10);
}这里演示的话给个10差不多了,实际可能会更复杂一些...
成员方法
就是增删改查嘛,不过这里需要注意的是,为了实现我们自己的动态数组,在增加和删除中,我们对临界值进行了判断,动态的增加或者缩小数组的大小,而且提供了一些常用友好的方法给用户;
// 获取数组的容量
public int getCapacity() {
return data.length;
}
// 获取数组中的元素个数
public int getSize() {
return size;
}
// 返回数组是否为空
public boolean isEmpty() {
return size == 0;
}
// 在index索引的位置插入一个新元素e
public void add(int index, E e) {
if (index < 0 || index > size)
throw new IllegalArgumentException("Add failed. Require index >= 0 and index <= size.");
if (size == data.length)
resize(2 * data.length);
for (int i = size - 1; i >= index; i--)
data[i + 1] = data[i];
data[index] = e;
size++;
}
// 向所有元素后添加一个新元素
public void addLast(E e) {
add(size, e);
}
// 在所有元素前添加一个新元素
public void addFirst(E e) {
add(0, e);
}
// 获取index索引位置的元素
public E get(int index) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Get failed. Index is illegal.");
return data[index];
}
// 修改index索引位置的元素为e
public void set(int index, E e) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Set failed. Index is illegal.");
data[index] = e;
}
// 查找数组中是否有元素e
public boolean contains(E e) {
for (int i = 0; i < size; i++) {
if (data[i].equals(e))
return true;
}
return false;
}
// 查找数组中元素e所在的索引,如果不存在元素e,则返回-1
public int find(E e) {
for (int i = 0; i < size; i++) {
if (data[i].equals(e))
return i;
}
return -1;
}
// 从数组中删除index位置的元素, 返回删除的元素
public E remove(int index) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Remove failed. Index is illegal.");
E ret = data[index];
for (int i = index + 1; i < size; i++)
data[i - 1] = data[i];
size--;
data[size] = null; // loitering objects != memory leak
if (size == data.length / 4 && data.length / 2 != 0)
resize(data.length / 2);
return ret;
}
// 从数组中删除第一个元素, 返回删除的元素
public E removeFirst() {
return remove(0);
}
// 从数组中删除最后一个元素, 返回删除的元素
public E removeLast() {
return remove(size - 1);
}
// 从数组中删除元素e
public void removeElement(E e) {
int index = find(e);
if (index != -1)
remove(index);
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append(String.format("Array: size = %d , capacity = %d\n", size, data.length));
res.append('[');
for (int i = 0; i < size; i++) {
res.append(data[i]);
if (i != size - 1)
res.append(", ");
}
res.append(']');
return res.toString();
}
// 将数组空间的容量变成newCapacity大小
private void resize(int newCapacity) {
E[] newData = (E[]) new Object[newCapacity];
for (int i = 0; i < size; i++)
newData[i] = data[i];
data = newData;
}-
注意:为了更好的展示代码而不太浪费空间,所以这里使用
//的风格来注释代码; -
特别注意:在
remove方法中,缩小数组的判断条件为size == data.length / 4 && data.length / 2 != 0,这是为了防止复杂度抖动和安全性;
简单时间复杂度分析
添加操作
在添加操作中,我们可以明显看到,addLast()方法是与n无关的,所以为O(1)复杂度;而addFirst()和add()方法都涉及到挪动数组元素,所以都是O(n)复杂度,包括resize()方法;综合起来添加操作的复杂度就是O(n);
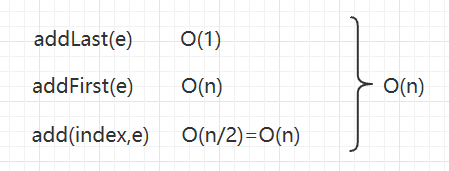
删除操作
在删除操作中,与添加操作同理,综合来看删除操作的复杂度就是O(n);
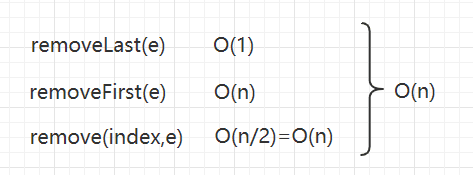
修改操作
在修改操作中,如果我们知道了需要修改元素的索引,那么我们就可以在常数时间内找到元素并进行修改操作,所以很容易的知道这个操作时一个复杂度为O(1)的操作,所以修改操作的复杂度就是O(1);但另外一种情况是我们不知道元素的索引,那么我们就需要先去查询这个元素,我把这归结到查询操作中去;
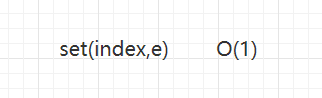
查询操作
在查询操作中,如果我们已知索引,那么复杂度为O(1);如果未知索引,我们需要遍历整个数组,那么复杂度为O(n)级别;

总结
以上我们简单分析了我们自己创建的数组类的复杂度:
- 增加:O(n);
- 删除:O(n);
- 修改:已知索引 O(1);未知索引 O(n);
- 查询:已知索引 O(1);未知索引 O(n);
均摊复杂度
如果细心的同学应该可以注意到,在增加和删除的复杂度分析中,如果我们都只是对最后一个元素进行相应的操作的话,那么对应的O(n)的复杂度显然是不合理的,我们之所以将他们的复杂度定义为O(n),就是因为在我们通常的复杂度分析中我们需要考虑最坏的情况,也就是对应的需要使用resize()方法扩容的情况,但是这样的情况并不是每一次都出现,所以我们需要更加合理的来分析我们的复杂度,这里提出的概念就是:均摊复杂度;
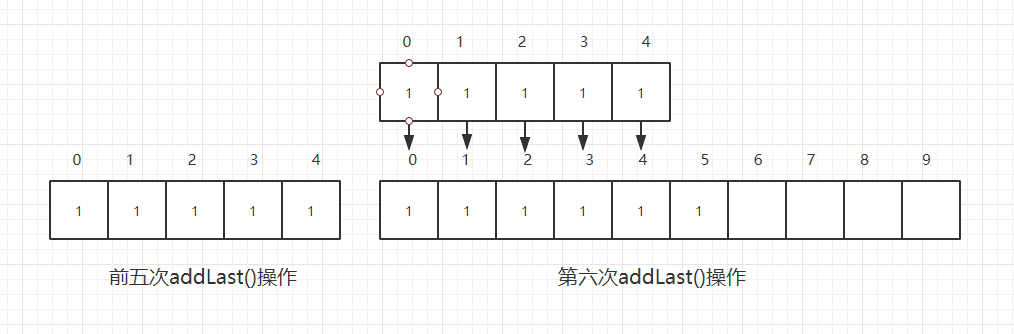
假设我们现在的capacity为5,并且每一次的添加操作都使用addLast()方法,那么我们在使用了五次addLast()方法之后就会触发一次resize()方法,在前五次的addLast()方法中我们总共进行了五次基本操作,也就是给数组的末尾添加上一个元素,在进行第六次addLast()方法的时候,触发resize()方法,就需要进行一次元素的转移,共5次操作(转移五个元素嘛),然后再在末尾加上一个元素,也就是总共进行了11次操作;
也就是说:6次addLast()操作,触发resize()方法,总共进行了11次操作,平均下来,每次addLast()操作,进行了2次基本操作(约等于);那么依照上面的假设我们可以进一步推广为:假设capacity为n,n+1次addLast()操作,触发resize()方法,总共进行了2n+1次基本操作,平均来讲,每次addLast()操作,进行了2次基本操作,这样也就意味着,均摊下来的addLast()方法的复杂度为O(1),而不是之前分析的O(n),这样的均摊复杂度显然比最坏复杂度来得更有意义,因为不是每一次的操作都是最坏的情况!
同理,我们看removeLast()对应的均摊复杂度也为O(1);
复杂度震荡
在我们的remove方法中,我们判断缩小容量的条件为size == data.length / 4 && data.length / 2 != 0,这样是为了防止复杂度震荡和安全性(因为缩小到一定的时候容量可能为1),这又是怎么一回事呢?我们考虑一下将条件改为size == data.length / 2的时候,出现的如下图这样的情况:
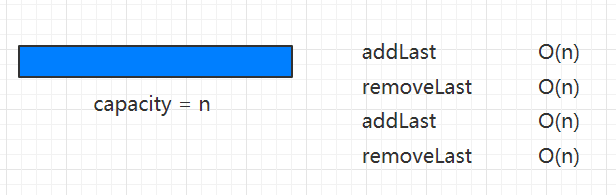
当我们数组已经满元素的情况下,使用一次addLast方法,因为触发resize,数组容量扩容为当前的两倍,所以此时复杂度为O(n);这时候我们立即使用removeLast,因为此时的容量等于n/2,所以会马上产生缩小容量的操作,此时复杂度为O(n);我们之前明明通过均摊复杂度分析出我们的两个操作都为O(1),而此时却产生了震荡,为了避免这样的操作,我们需要懒操作一下,也就是在remove的时候不要立即缩容,而是等到size == capacity / 4的时候再缩小一半,这样就有效的解决了复杂度震荡的问题;
Java中的ArrayList的扩容
上面我们已经实现了自己的数组类,我们也顺便看看Java中的ArrayList是怎么写的,其他的方法可以自己去看看,这里提出来一个grow()的方法,来看看ArrayList是怎么实现动态扩容的:
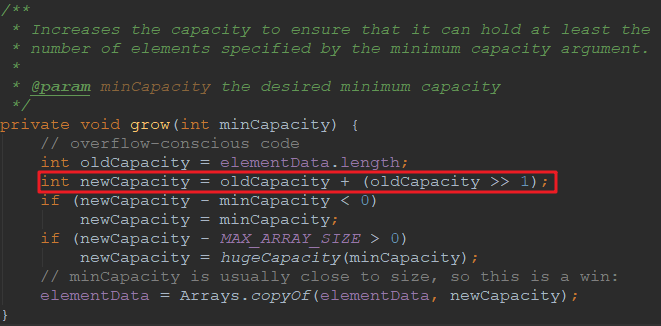
从上面的源码我们可以看到ArrayList默认增容是增加当前容量的0.5倍(>> 1即乘以0.5)
链表
什么是链表
链表是一种用于存储数据集合的数据结构,它是最简单的动态数据结构,我们在上面虽然实现了动态数组,但这仅仅是对于用户而言,其实底层还是维护的一个静态的数组,它之所以是动态的是因为我们在add和remove的时候进行了相应判断动态扩容或缩容而已,而链表则是真正意义上动态的数据结构;
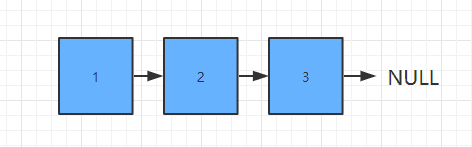
链表的优点
- 真正的动态,不需要处理固定容量的问题;
- 能够在常数时间内扩展容量;
对比我们的数组,当创建数组时,我们必须分配能存储一定数量元素的内存,如果向数组中添加更多的元素,那么必须创建一个新的数组,然后把原数组中的元素复制到新数组中去,这将花费大量的时间;当然也可以通过给数组预先设定一个足够大的空间来防止上述时间的发生,但是这个方法可能会因为分配超过用户需要的空间而造成很大的内存浪费;而对于链表,初始时仅需要分配一个元素的存储空间,并且添加新的元素也很容易,不需要做任何内存复制和重新分配的操作;
链表的缺点
- 丧失了随机访问的能力;
- 链表中的额外指针引用需要浪费内存;
链表有许多不足。链表的主要缺点在于访问单个元素的时间开销问题;数组是随时存取的,即存取数组中任一元素的时间开销为O(1),而链表在最差情况下访问一个元素的开销为O(n);数组在存取时间方面的另一个优点是内存的空间局部性,由于数组定义为连续的内存块,所以任何数组元素与其邻居是物理相邻的,这极大得益于现代CPU的缓存模式;
链表和数组的简单对比
- 数组最好用于索引有语意的情况,最大的优点:支持快速查询;
- 链表不适用于索引有语意的情况,最大的优点:动态;
实现自己的链表类
public class LinkedList<E> {
private class Node {
public E e;
public Node next;
public Node(E e, Node next) {
this.e = e;
this.next = next;
}
public Node(E e) {
this(e, null);
}
public Node() {
this(null, null);
}
@Override
public String toString() {
return e.toString();
}
}
private Node dummyHead;
private int size;
public LinkedList() {
dummyHead = new Node();
size = 0;
}
// 获取链表中的元素个数
public int getSize() {
return size;
}
// 返回链表是否为空
public boolean isEmpty() {
return size == 0;
}
// 在链表的index(0-based)位置添加新的元素e
// 在链表中不是一个常用的操作,练习用:)
public void add(int index, E e) {
if (index < 0 || index > size)
throw new IllegalArgumentException("Add failed. Illegal index.");
Node prev = dummyHead;
for (int i = 0; i < index; i++)
prev = prev.next;
prev.next = new Node(e, prev.next);
size++;
}
// 在链表头添加新的元素e
public void addFirst(E e) {
add(0, e);
}
// 在链表末尾添加新的元素e
public void addLast(E e) {
add(size, e);
}
// 获得链表的第index(0-based)个位置的元素
// 在链表中不是一个常用的操作,练习用:)
public E get(int index) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Get failed. Illegal index.");
Node cur = dummyHead.next;
for (int i = 0; i < index; i++)
cur = cur.next;
return cur.e;
}
// 获得链表的第一个元素
public E getFirst() {
return get(0);
}
// 获得链表的最后一个元素
public E getLast() {
return get(size - 1);
}
// 修改链表的第index(0-based)个位置的元素为e
// 在链表中不是一个常用的操作,练习用:)
public void set(int index, E e) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Update failed. Illegal index.");
Node cur = dummyHead.next;
for (int i = 0; i < index; i++)
cur = cur.next;
cur.e = e;
}
// 查找链表中是否有元素e
public boolean contains(E e) {
Node cur = dummyHead.next;
while (cur != null) {
if (cur.e.equals(e))
return true;
cur = cur.next;
}
return false;
}
// 从链表中删除index(0-based)位置的元素, 返回删除的元素
// 在链表中不是一个常用的操作,练习用:)
public E remove(int index) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Remove failed. Index is illegal.");
// E ret = findNode(index).e; // 两次遍历
Node prev = dummyHead;
for (int i = 0; i < index; i++)
prev = prev.next;
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size--;
return retNode.e;
}
// 从链表中删除第一个元素, 返回删除的元素
public E removeFirst() {
return remove(0);
}
// 从链表中删除最后一个元素, 返回删除的元素
public E removeLast() {
return remove(size - 1);
}
// 从链表中删除元素e
public void removeElement(E e) {
Node prev = dummyHead;
while (prev.next != null) {
if (prev.next.e.equals(e))
break;
prev = prev.next;
}
if (prev.next != null) {
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
}
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
Node cur = dummyHead.next;
while (cur != null) {
res.append(cur + "->");
cur = cur.next;
}
res.append("NULL");
return res.toString();
}
}链表虚拟头结点的作用
- 为了屏蔽掉链表头结点的特殊性;
因为头结点是没有前序结点的,所以我们不管是删除还是增加操作都要对头结点进行单独的判断,为了我们编写逻辑的方便,引入了一个虚拟头结点的概念;
简单复杂度分析
我们从链表的操作中可以很容易的看出,对于增删改查这几个操作的复杂度都是O(n)的,但是如果我们只是对链表头进行增/删/查的操作的话,那么它的复杂度就是O(1)的,这里也可以看出来我们的链表适合干的事情了..
LeetCode相关题目参考
1.两数之和
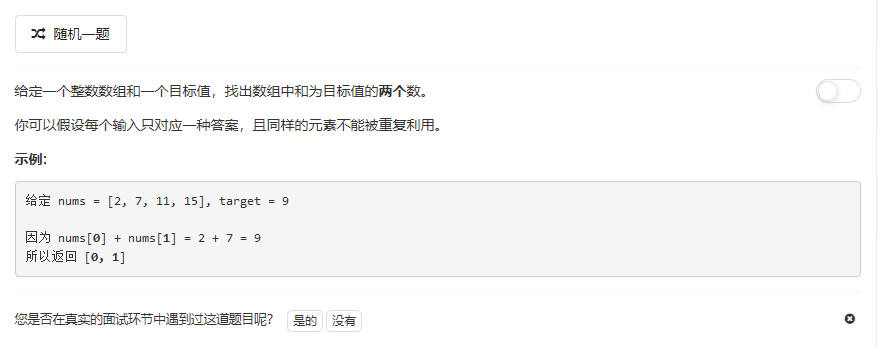
参考答案:
class Solution {
public int[] twoSum(int[] numbers, int target) {
int [] res = new int[2];
if(numbers==null||numbers.length<2)
return res;
HashMap<Integer,Integer> map = new HashMap<Integer,Integer>();
for(int i = 0; i < numbers.length; i++){
if(!map.containsKey(target-numbers[i])){
map.put(numbers[i],i);
}else{
res[0]= map.get(target-numbers[i]);
res[1]= i;
break;
}
}
return res;
}
}2.两数相加
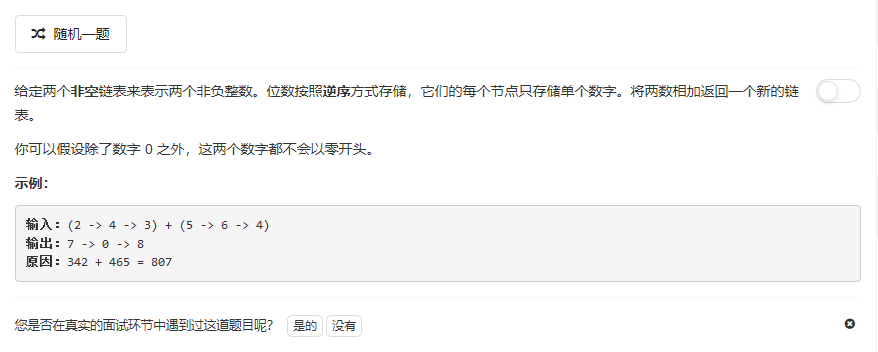
参考答案:
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummyHead = new ListNode(0);
ListNode p = l1, q = l2, curr = dummyHead;
int carry = 0;
while (p != null || q != null) {
int x = (p != null) ? p.val : 0;
int y = (q != null) ? q.val : 0;
int sum = carry + x + y;
carry = sum / 10;
curr.next = new ListNode(sum % 10);
curr = curr.next;
if (p != null) p = p.next;
if (q != null) q = q.next;
}
if (carry > 0) {
curr.next = new ListNode(carry);
}
return dummyHead.next;
}203.删除链表中的节点
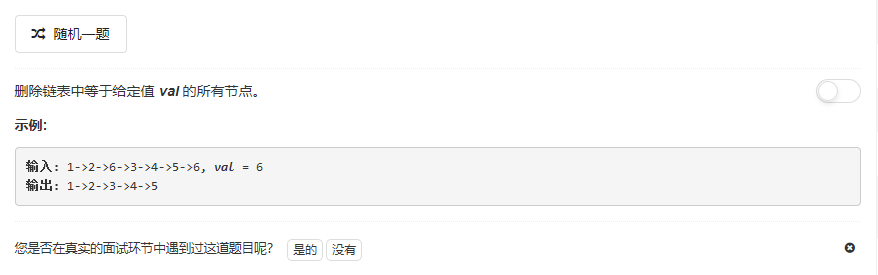
参考答案:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
// 定义一个虚拟头结点
ListNode dummyHead = new ListNode(-1);
dummyHead.next = head;
ListNode prev = dummyHead;
while (prev.next != null) {
if (prev.next.val == val) {
prev.next = prev.next.next;
} else {
prev = prev.next;
}
}
return dummyHead.next;
}
}欢迎转载,转载请注明出处!
简书ID:@我没有三颗心脏
github:wmyskxz
欢迎关注公众微信号:wmyskxz_javaweb
分享自己的Java Web学习之路以及各种Java学习资料