-
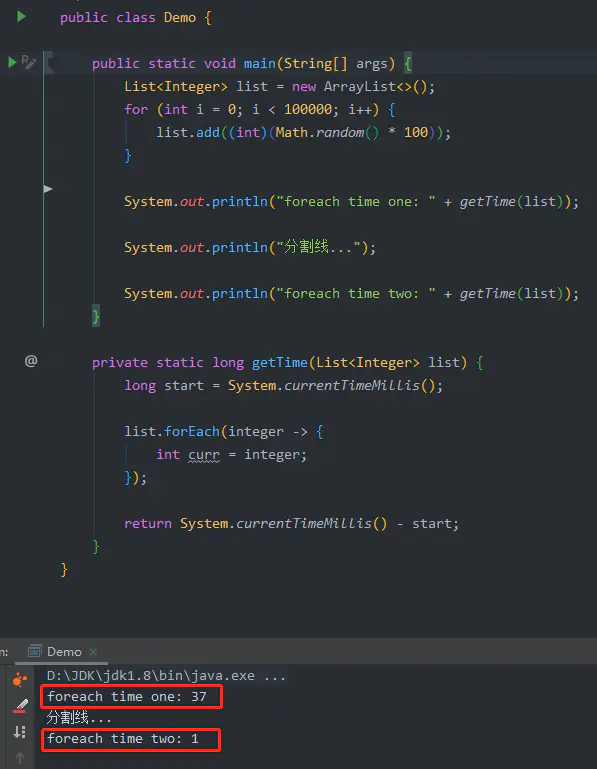
看到输出结果了吗?为什么第一次和第二次的时间相差如此之多?咱们一起琢磨琢磨,也可以先去看看结论再回过头看分析
注:并非仅第二次快,而是除了第一次,之后的每一次都很快
给与猜想
-
是否和操作系统预热有关?
-
是否和JIT(即时编译)有关?
-
是否和ClassLoader类加载有关?
-
是否和
Lambda有关,并非foreach的问题
验证猜想
操作系统预热
操作系统预热这个概念是我咨询一位大佬得到的结论,在百度 / Google 中并未搜索到相应的词汇,但是在模拟测试中,我用 普通遍历 的方式进行测试:
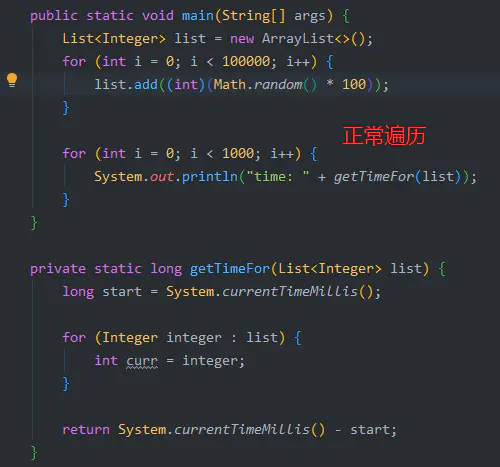
基本上每次都是前几次速度较慢,后面的速度更快,因此 可能 有这个因素影响,但差距并不会很大,因此该结论并不能作为问题的答案。
JIT 即时编译
首先介绍一下什么是JIT即时编译:
当 JVM 的初始化完成后,类在调用执行过程中,执行引擎会把字节码转为机器码,然后在操作系统中才能执行。在字节码转换为机器码的过程中,虚拟机中还存在着一道编译,那就是
即时编译。最初,JVM 中的字节码是由解释器( Interpreter )完成编译的,当虚拟机发现某个方法或代码块的运行特别频繁的时候,就会把这些代码认定为
热点代码。为了提高热点代码的执行效率,在运行时,即时编译器(JIT,Just In Time)会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,然后保存到内存中
再来一个概念,
回边计数器回边计数器用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为 "回边"(Back Edge)
建立回边计数器的主要目的是为了触发 OSR(On StackReplacement)编译,即栈上编译,在一些循环周期比较长的代码段中,当循环达到回边计数器阈值时,
JVM 会认为这段是热点代码,JIT 编译器就会将这段代码编译成机器语言并缓存,在该循环时间段内,会直接将执行代码替换,执行缓存的机器语言从上述的概念中,我们应该可以得到一个结论:第一条所谓的操作系统预热 大概率不正确,因为普通遍历方法执行N次,后续执行的时间占用比较小,很可能是因为JIT导致的。
那 JIT即时编译 是否是最终的答案?我们想办法把 JIT 关掉来测试一下,通过查询资料发现了如下内容:
Procedure
-
Use the -D option on the JVM command line to set the java.compiler property to NONE or the empty string.
Type the following command at a shell or command prompt:
java -Djava.compiler=NONE <class>
注:该段内容来自IBM官方资料,地址见 <收获> ,咱们先不要停止思考
通过配置 IDEA JVM 参数:

执行问题中的代码测试结果如下:
# 禁用前
foreach time one: 38
分割线...
foreach time two: 1
# 禁用后
foreach time one: 40
分割线...
foreach time two: 5我测试了很多次,结果都很相近,因此得到可以得到另一个结论:
JIT并非引发该问题的原因(但是它的确能提高执行效率)难道和类加载有关?
在进行类加载验证时,我依然无法放弃
JIT,因此查阅了很多资料,知道了某个命令可以查看JIT编译的耗时情况,命令如下:java -XX:+CITime com.code.jvm.preheat.Demo >> log.txt解释一下命令的意思
# 执行的目录
C:\Users\Kerwin\Desktop\Codes\Kerwin-Code-Study\target\classes>
# 命令含义:Prints time spent in JIT Compiler. (Introduced in 1.4.0.)
# 打印JIT编译所消耗的时间
-XX:+CITime
# 代表我指定的类
com.code.jvm.preheat.Demo
# 输出至log.txt文件,方便观看
>> log.txt展示一下某一次结果的全部内容:
foreach time one: 35
分割线...
foreach time two: 1
Accumulated compiler times (for compiled methods only)
------------------------------------------------
Total compilation time : 0.044 s
Standard compilation : 0.041 s, Average : 0.000
On stack replacement : 0.003 s, Average : 0.002
Detailed C1 Timings
Setup time: 0.000 s ( 0.0%)
Build IR: 0.010 s (38.8%)
Optimize: 0.001 s ( 2.3%)
RCE: 0.000 s ( 0.7%)
Emit LIR: 0.010 s (40.7%)
LIR Gen: 0.002 s ( 9.3%)
Linear Scan: 0.008 s (31.0%)
LIR Schedule: 0.000 s ( 0.0%)
Code Emission: 0.003 s (12.4%)
Code Installation: 0.002 s ( 8.2%)
Instruction Nodes: 9170 nodes
Total compiled methods : 162 methods
Standard compilation : 160 methods
On stack replacement : 2 methods
Total compiled bytecodes : 13885 bytes
Standard compilation : 13539 bytes
On stack replacement : 346 bytes
Average compilation speed: 312157 bytes/s
nmethod code size : 168352 bytes
nmethod total size : 276856 bytes分别测试的结果如下:
类型 Total compilation time(JIT编译总耗时) 两次 foreach(lambda) 循环 0.044 s 两次 foreach (普通)循环 0.016 s 两次 增强for循环 0.015 s 一次 foreach(lambda) 一次增强for循环 0.046 s 通过上述测试结果,反正更加说明了一个问题:只要有 Lambda 参与的程序,编译时间总会长一些
再次通过查询资料,了解了新的命令
java -verbose:class -verbose:jni -verbose:gc -XX:+PrintCompilation com.code.jvm.preheat.Demo解释一下命令的意思
# 输出jvm载入类的相关信息
-verbose:class
# 输出native方法调用的相关情况
-verbose:jni
# 输出每次GC的相关情况
-verbose:gc
# 当一个方法被编译时打印相关信息
-XX:+PrintCompilation对包含Lambda和不包含的分别执行命令,得到的结果如下:
从日志文件大小来看,就相差了十几kb
注:文件过大,仅展示部分内容
# 包含Lambda
[Loaded java.lang.invoke.LambdaMetafactory from D:\JDK\jre1.8\lib\rt.jar]
# 中间省略了很多内容,LambdaMetafactory 是最明显的区别(仅从名字上发现)
[Loaded java.lang.invoke.InnerClassLambdaMetafactory$1 from D:\JDK\jre1.8\lib\rt.jar]
5143 220 4 java.lang.String::equals (81 bytes)
[Loaded java.lang.invoke.LambdaForm$MH/471910020 from java.lang.invoke.LambdaForm]
5143 219 3 jdk.internal.org.objectweb.asm.ByteVector::<init> (13 bytes)
[Loaded java.lang.invoke.LambdaForm$MH/531885035 from java.lang.invoke.LambdaForm]
5143 222 3 jdk.internal.org.objectweb.asm.ByteVector::putInt (74 bytes)
5143 224 3 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes)
5143 225 3 com.code.jvm.preheat.Demo::lambda$getTime$0 (6 bytes)
5144 226 4 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes)
5144 223 1 java.lang.Integer::intValue (5 bytes)
5144 221 3 jdk.internal.org.objectweb.asm.ByteVector::putByteArray (49 bytes)
5144 224 3 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes) made not entrant
5145 227 % 4 java.util.ArrayList::forEach -
Lambda初次使用很慢?从JIT到类加载再到实现原理
阅读(2619) 评论(0)