本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
作者 Dark Horse
前言
在使用 Python 开发爬虫的过程中,requests 和 BeautifulSoup4(别名bs4) 应用的比较广泛,requests主要用于模拟浏览器的客户端请求,以获取服务器端响应,接收到的响应结果,如:网页HTML源码则交由 bs4 封装后再解析提取目标内容数据。
今天的案例中,我们将使用一个新库 MechanicalSoup 该库事实上是对 requests 和 bs4 的进一步封装,让请求和解析的工作进一步简化,如果你已经熟悉 requests 和 bs4 的基本操作,下面的代码理解起来应该不会很困难。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
Python学习交流群:1039649593
准备工作
mechanicalsoup 安装
终端下使用 pip 安装即可,也会自动安装相关依赖组件库
pip install mechanicalsoup
网页分析
今天我们要请求的是全球是最大的电影数据库网站 IMDb,其官网地址是 http://www.imdb.com 首页显示效果如图所示:
我们要爬取数据的页面,可以通过“Menu“ 导航的子菜单项 "Top Rated Movies" 进入,或直接访问 https://www.imdb.com/chart/top/
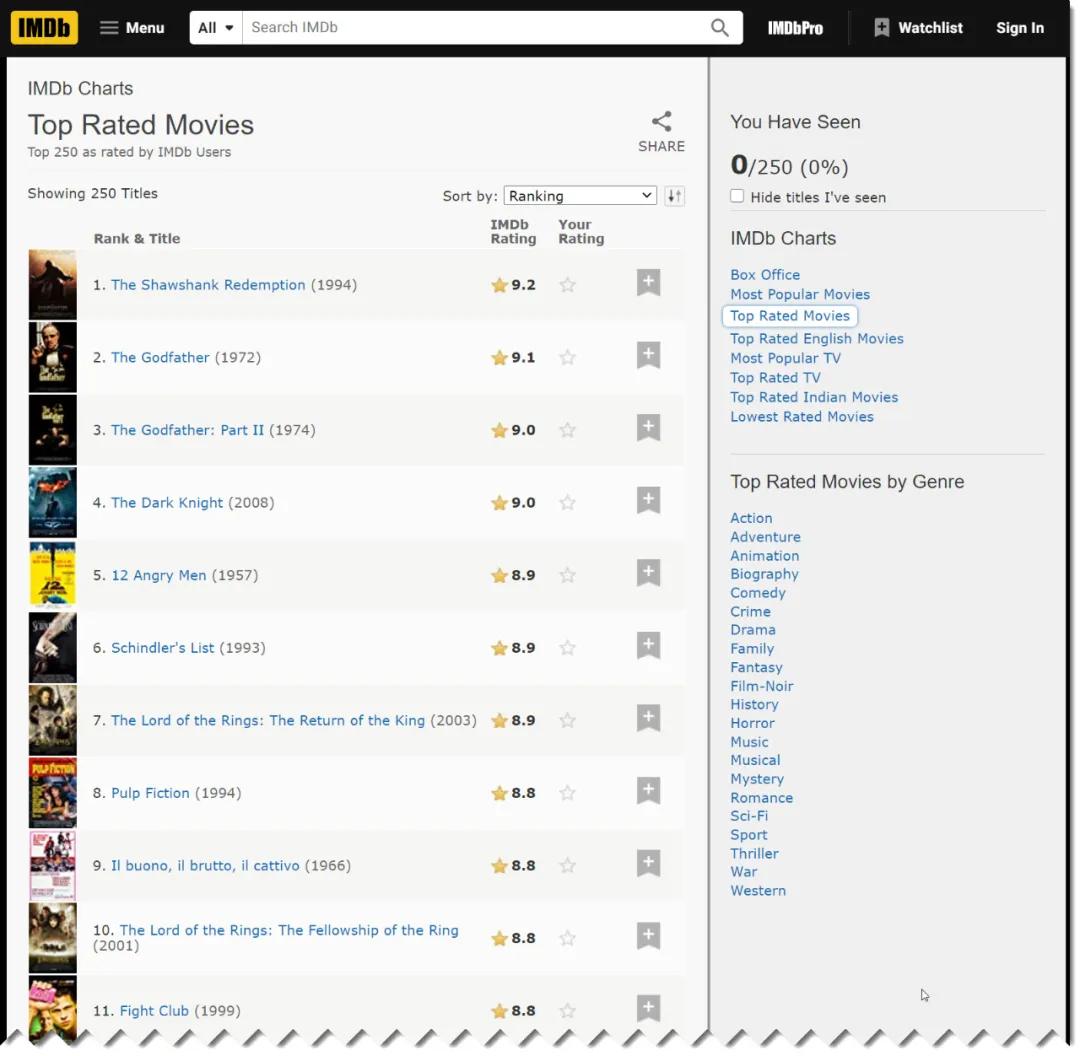
我们要采集的目标数据为左侧页面的列表,经过浏览器右键“检查”分析,得知第一条数据项均包含在一个表格行内,此时我们进一步明确要采集的数据为排名、电影标题、发行年份三列,分析得到以下HTML元素:
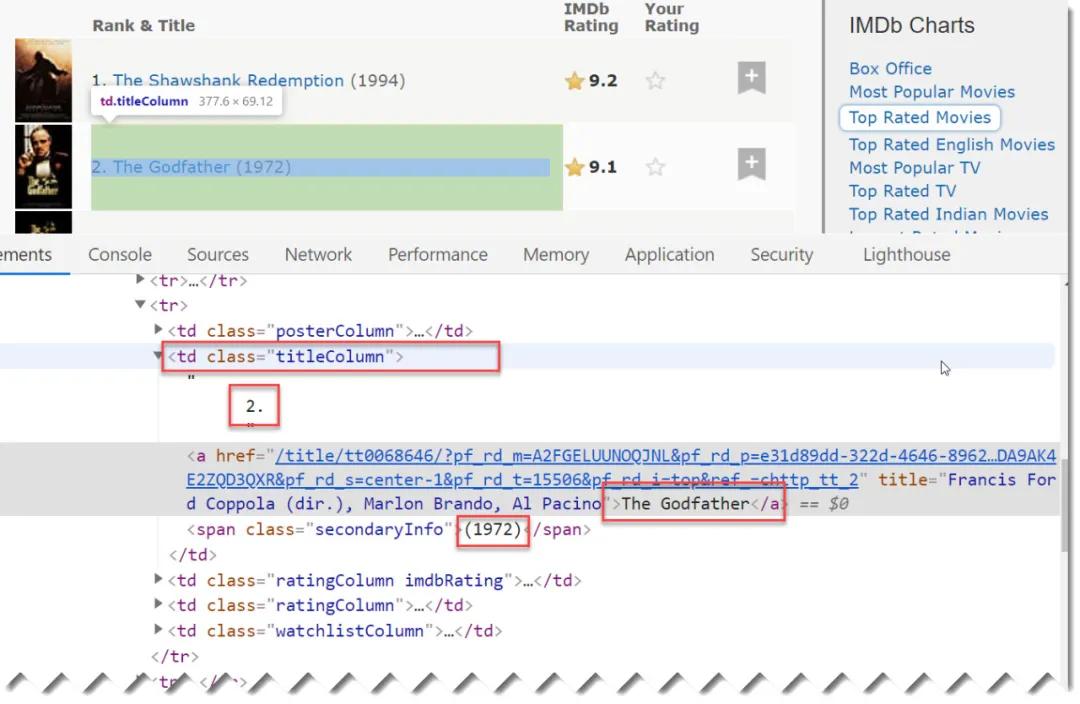
目标数据均包含在一个td class="titleColumn" 单元格内,此时只需要批量获取有该特征的批量单元格,再取出目标数据并清理即可。
编码实现
采集并打印
初步代码结构:
imdb.py
import mechanical
# 数据容器
data = []
def fetch_data():
# 此处爬取页面目标数据
def main():
fetch_data()
if __name__ == "__main__":
main()重点的代码逻辑是包含在 fetch_data() 函数内,具体代码如下(含注释):
def fetch_data():
url = "https://www.imdb.com/chart/top/"
# 构造浏览器对象
b = mechanicalsoup.StatefulBrowser()
# 请求目标网址
b.open(url)
# b.page 即为当前响应页面源码,且已封装为 BeautifulSoup 对象
# 页面中找出所有具有 class="titleColumn" 属性的 td 单元格集合
items = b.page.find_all("td", class_="titleColumn")
# 遍历所有项
for item in items:
# 取出当前单元格中所所有文本,以"\n"分隔为三个元素
row = item.text.strip().split("\n")
# 进一步清理元素值的空格
# 此时列表中三个元素对应为排名、标题、年份
row = [x.strip() for x in row]
# 将数据添加至data列表容器,便于进一步处理
data.append(row)
# 打印显示
print(row)
此时代码如下:
import mechanicalsoup
data = []
def fetch_data():
url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250"
b = mechanicalsoup.StatefulBrowser()
b.open(url)
items = b.page.find_all("td", class_="titleColumn")
for item in items:
row = item.text.strip().split("\n")
row = [x.strip() for x in row]
data.append(row)
print(row)
def main():
fetch_data()
if __name__ == "__main__":
main()
此时运行代码 python imdb.py 结果如下:
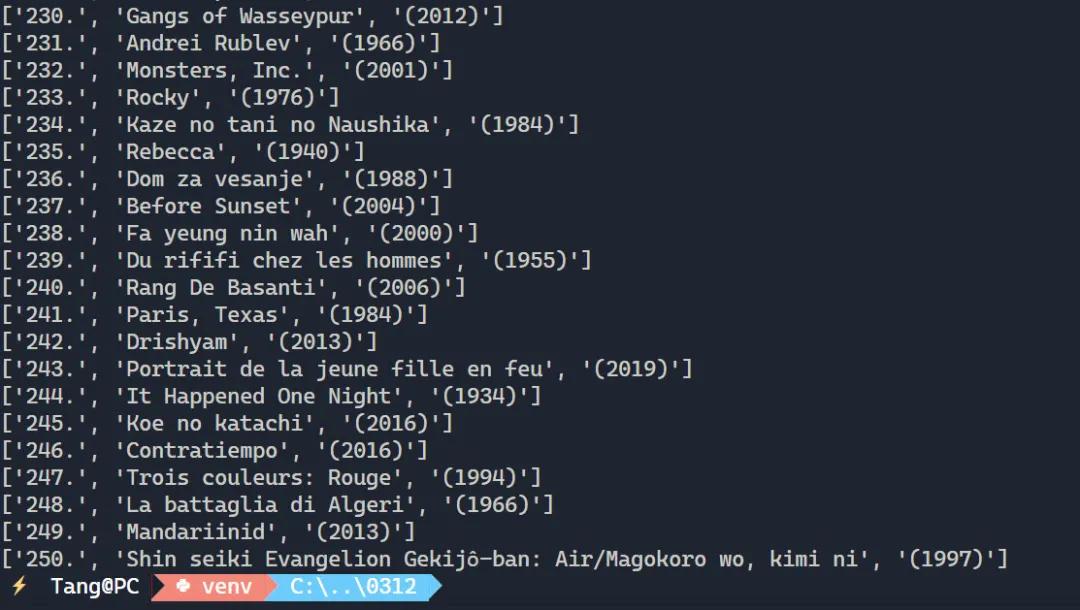
可以看到在逐行提取时打印的效果,此时数据窗口 data 中也包括了所有行250行的电影信息。
将批量数据写入Excel文件
如果将采集的批量电影数据(250条)一次性写入Excel 表格文件,可以安装使用 Excel 操作库,比如:openpyxl 等,在执行完前述步骤 fetch_data() 执行新建、并写入Excel 操作即可。