本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码!
# -*- coding: utf-8 -*
import re
import os
import urllib
import urllib2
from bs4 import BeautifulSoup
def craw(url,page):
html1=urllib2.urlopen(url).read()
html1=str(html1)
soup=BeautifulSoup(html1,'lxml')
imagelist=soup.select('#J_goodsList > ul > li > div > div.p-img > a > img')
namelist=soup.select('#J_goodsList > ul > li > div > div.p-name > a > em')
#pricelist=soup.select('#plist > ul > li > div > div.p-price > strong')
#print pricelist
path = "E:/{}/".format(str(goods))
if not os.path.exists(path):
os.mkdir(path)
for (imageurl,name) in zip(imagelist,namelist):
name=name.get_text()
imagename=path + name +".jpg"
imgurl="http:"+str(imageurl.get('data-lazy-img'))
if imgurl == 'http:None':
imgurl = "http:" + str(imageurl.get('src'))
try:
urllib.urlretrieve(imgurl,filename=imagename)
except:
continue
'''
#J_goodsList > ul > li:nth-child(1) > div > div.p-img > a > img
#plist > ul > li:nth-child(1) > div > div.p-name.p-name-type3 > a > em
#plist > ul > li:nth-child(1) > div > div.p-price > strong:nth-child(1) > i
'''
if __name__ == "__main__":
goods=raw_input('please input the goos you want:')
pages=input('please input the pages you want:')
count =0.0
for i in range(1,int(pages+1),2):
url="https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&suggest=1.def.0.T06&wq=diann&page={}".format(str(goods),str(i))
craw(url,i)
count += 1
print 'work completed {:.2f}%'.format(count/int(pages)*100)图片的命名为商品的名称,京东商品图片地址的属性很可能会有所变动,所以大家进行编写的时候应该举一反三,灵活运用!
这是我下载下来的手机类图片文件的截图: 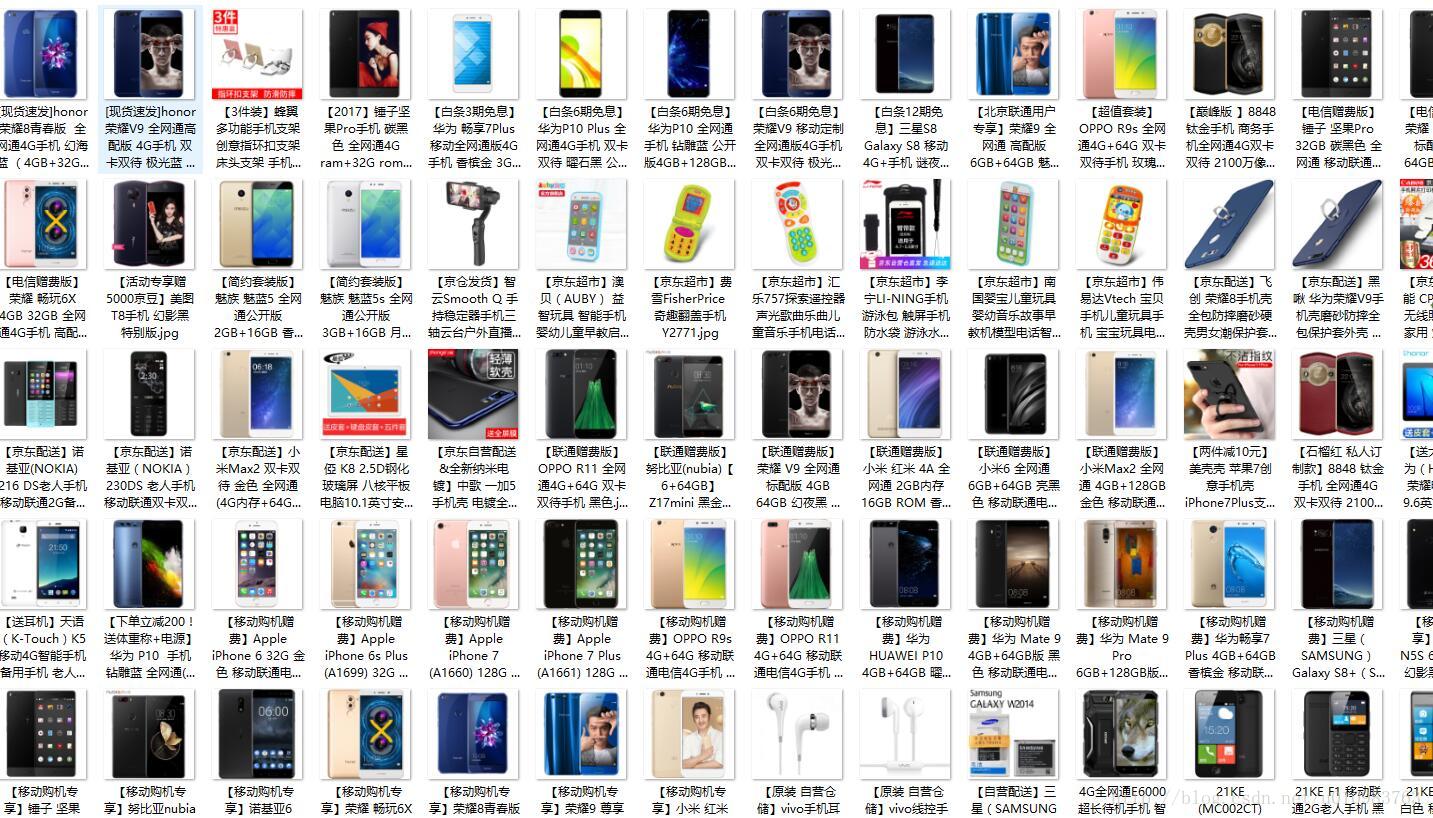
我本地的爬取的速度很快,不到一分钟就能爬取100页上千个商品的图片!