Mechanize
本文仅为学习笔记,欢迎大家交流和指出错误
以下是基本操作:
1 import mechanize
2 #创建一个浏览器对象
3 br = mechanize.Browser()
4 #以下是一些基本设置
5 #设置是否处理HTML html-equiv标头,当浏览器等设备接收服务器端传送的文件时,首先会接收文件的相关名称/值对。
6 #如:<meta http-equiv="content-type" content="text/html; charset=utf-8" /> 获得了该html编码方式
7 br.set_handle_equiv(True)
8 #是否向每个请求发送referer头。referer是http请求header标头的一部分。头域的值表明了是哪个URL地址触发了对当前页面的访问。
9 br.set_handle_referer(True)
10 #设置是否遵守robots协议
11 br.set_handle_robots(False)
12 #设置是否处理重定向。重定向(Redirect)就是通过各种方法将各种网络请求重新定个方向转到其它位置。
13 #当网站调整或者网页被移到一个新的地址或者网页扩展名发生改变时都会引起重定向
14 br.set_handle_redirect(True)
15 #设置是否处理gzip传输编码。gzip是一种数据压缩格式。
16 #GZIP压缩的比率往往在3到10倍,也就是本来90k大小的页面,采用压缩后实际传输的内容大小只有28至30K大小,这可以大大节省服务器的
网络带宽,同时如果应用程序的响应足够快时,网站的速度瓶颈就转到了网络的传输速度上,因此内容压缩后就可以大大的提升页面的浏览速度。
17 br.set_handle_gzip(True)
18
19 br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(),max_time=1)
20 #设置debug相关的吧
21 br.set_debug_http(True)
22 br.set_debug_redirects(True)
23 br.set_debug_response(True)
24 #设置http header 就是告诉网站,我是个来自Mozilla浏览器的访问,不是爬虫
25 br.addheaders = [('User-agent', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]
26 #打开网址。
27 br.open("http://www.baidu.com")
28 #被打开的网址会有一个框架,可以查看框架,对框架进行操作,来完成复杂的交互
29 for form in br.forms():
30 print form
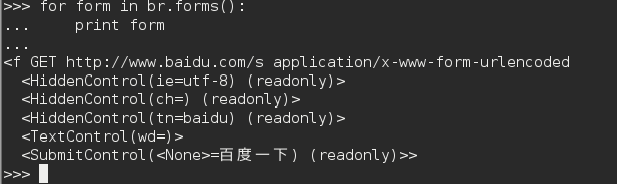
从上图可以看出,只有一个名字为 f 的框架。有的时候框架并没有名字,那就只能按顺序排序,第一个就是 nr = 0 ,第二个就是 nr = 1,以此类推
1 #选择框架 f
2 br.select_form(name='f')
3 #向框架中的wd写写入要搜索的内容
4 br.form['wd'] = 'python'
5 #提交,就相当于点击了百度网页的搜索按钮
6 br.submit()
7 #查看一下打开的网页是否是期望中的
8 print(br.title())
运行结果如下:
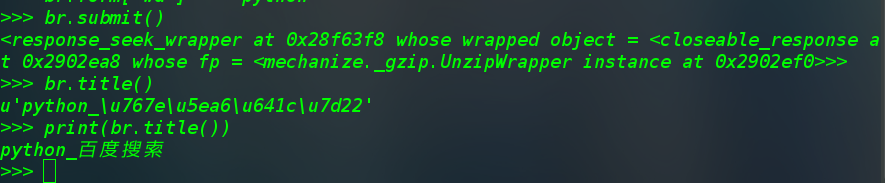
1 #也可以输出html文本
2 print br.response().read()
3 #由于过长,此处略
4 #输出这个网页中的所有url
5 for link in br.links():
6 print("text:%s , url:%s"%(link.text,link.url))
7 #即为其url信息
8 #还可以选择链接再次打开
9 newUrl = br.click_link(text='可以用 Python 编程语言做哪些神奇好玩的事情? - 知乎')
10 br.open(newUrl)
11 #就运用到上述的操作就可以对网页进行交互操作,来得到我们想要的
12 #也可以使用这个来返回上一页
13 br.back()
14 #查看现在的url,检查是否返回
15 print(br.geturl())
1 # 使用 用户名和密码登陆网站
2 br.add_password('http://你想登陆的网址.com','username','password')
3 #之后再
4 br.open('http://你想登陆的网址.com')
5 #也可以先打开网站,之后输出form。利用br.form['username'] = ''方式来登陆
6
7
8 #获取cookie并使用cookie登陆 需要先登陆进网站才能获取该网站的cookie
9 #下例为获取zhihu的cookie的例子
10 import cookielab,mechanize
11 br.mechanize.Browser()
12 br.open('https://www.zhihu.com/question/56932365/answer/246810982')
13 c = cookie.LWPCookieJar()
14 br.back()
15 br.set_cookiejar()
16 br.open('https://www.zhihu.com/question/56932365/answer/246810982')
17
18 #设置proxy
19 br.set_proxies({'https','xxx.xxx.xxx.xx:xxx'})
20 br.add_proxy_password('username','password')
21 #或者
22 br.set_proxies('http','username:password@xxx.xxx.xxx.xx:xxx')
mechanize初始化Browser()的时候,如果你不给他传一个history对象作为参数,Browser()就会按照默认的方式(允许保存操作历史)来进行初始化,这样以来每次都会储存,就会占据内存,导致越来越慢。
解决:自定义一个NoHistory对象 传给它:
class NoHistory(object):
def add(self, *a, **k): pass
def clear(self): pass
b = mechanize.Browser(history=NoHistory())