前言
今天来写个网易云音乐个人歌单下载器呗,让我们愉快地开始吧~
开发工具
** Python版本:**3.6.4
** 相关模块:**
DecryptLogin模块;
argparse模块;
prettytable模块;
click模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
DecryptLogin安装方式参见(因为经常更新,已经安装过的小伙伴麻烦记得更新一下,否则可能会在新的案例中报错)
原理简介
既然是模拟登录系列,首先自然是先模拟登录网易云音乐啦,这个利用我们开源的DecrpytLogin库可以轻松地实现:
'''利用DecryptLogin实现模拟登录'''
@staticmethod
def login(username, password):
lg = login.Login()
infos_return, session = lg.music163(username, password)
return infos_return.get('userid'), session
接着就是获取登录用户创建/收藏的歌单列表(注意,因为只是一个小例子,所以仅支持下载登录用户自己创建/收藏的歌单,当然这代码应该很容易可以扩展到下载任意歌单T_T),通过抓包分析(其实网上很多地方可以找到别人分析完后公开的网易云音乐api,需要的可以去知乎或者Github之类的网站上搜索一下对应关键字)我们可以发现登录用户所有歌单的列表可以通过请求以下API获取:
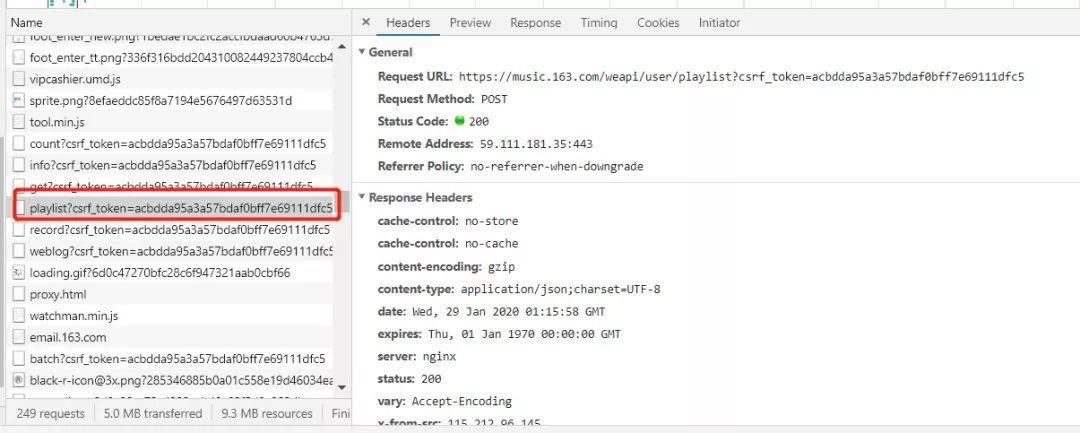
https://music.163.com/weapi/user/playlist?csrf_token=
其中csrf_token的值在用户登录后的session的cookies中可以找到,由此我们可以获得我们需要的歌单相关的信息,代码实现如下:
'''获得所有歌单'''
def getPlayLists(self):
playlist_url = 'https://music.163.com/weapi/user/playlist?csrf_token='
playlists = []
offset = 0
while True:
data = {
"offset": offset,
"uid": self.userid,
"limit": 50,
"csrf_token": self.csrf
}
res = self.session.post(playlist_url+self.csrf, headers=self.headers, data=self.cracker.get(data))
playlists += res.json()['playlist']
offset += 1
if not res.json()['more'] == 'false':
break
all_playlists = {}
for item in playlists:
name = item.get('name')
track_count = item.get('trackCount')
play_count = item.get('playCount')
play_id = item.get('id')
if item.get('creator').get('userId') == self.userid:
attr = '我创建的歌单'
else:
attr = '我收藏的歌单'
all_playlists[str(play_id)] = [name, track_count, play_count, attr]
return all_playlists
接着,用户将选择想要下载的歌单id,根据歌单id,我们将利用以下api来获得该歌单的详细信息:

https://music.163.com/weapi/v6/playlist/detail?csrf_token=
具体而言,代码实现如下:
def getPlayListSongs(self, playlist_id, num_songs):
detail_url = 'https://music.163.com/weapi/v6/playlist/detail?csrf_token='
offset = 0
song_infos = {}
while True:
data = {
'id': playlist_id,
'offset': offset,
'total': True,
'limit': 1000,
'n': 1000,
'csrf_token': self.csrf
}
res = self.session.post(detail_url+self.csrf, headers=self.headers, data=self.cracker.get(data))
tracks = res.json()['playlist']['tracks']
for track in tracks:
name = track.get('name')
songid = track.get('id')
artists = ','.join([i.get('name') for i in track.get('ar')])
brs = [track.get('h')] + [track.get('m')] + [track.get('l')]
song_infos[songid] = [name, artists, brs]
offset += 1
if len(list(song_infos.keys())) >= num_songs:
break
return song_infos
其中返回的信息中br(其实就是歌曲比特率)和歌曲id在后续的歌曲下载中是必须要的,其他信息的提取主要是为了用户交互的需要。接着,当用户确定是下载该歌单中的所有歌曲时,程序就开始下载所有歌曲啦。而某首歌曲下载的代码在之前的音乐下载器里分享过,copy过来稍微改下大概就是这个这样了:
'''下载某首歌曲'''
def downloadSong(self, songid, songname, brs, savepath='.'):
play_url = 'http://music.163.com/weapi/song/enhance/player/url?csrf_token='
print('正在下载 ——> %s' % songname)
for br in brs:
data = {
'ids': [songid],
'br': br.get('br'),
'csrf_token': self.csrf
}
res = self.session.post(play_url+self.csrf, headers=self.headers, data=self.cracker.get(data))
if res.json()['code'] == 200:
download_url = res.json()['data'][0].get('url', '')
if download_url:
break
with closing(self.session.get(download_url, headers=self.headers, stream=True, verify=False)) as res:
total_size = int(res.headers['content-length'])
if res.status_code == 200:
label = '[FileSize]:%0.2f MB' % (total_size/(1024*1024))
with click.progressbar(length=total_size, label=label) as progressbar:
with open(os.path.join(savepath, songname+'.'+download_url.split('.')[-1]), "wb") as f:
for chunk in res.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
progressbar.update(1024)
文章到这里就结束了,感谢你的观看,关注我每天分享Python模拟登录系列,下篇文章分享网抑云个人听歌排行榜爬取
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
All done~完整源代码+干货详见个人简介或者私信获取相关文件。。