@

Python--Pandas简单了解
1. Pandas介绍
1.1 Pandas介绍 - 数据处理工具
-
panel+data+analysis - panel面板数据 - 计量经济学 三维数据
1.2 为什么使用Pandas
- 便捷的数据处理能力
- 读取文件方便
- 封装了
Matplotlib、Numpy的画图和计算
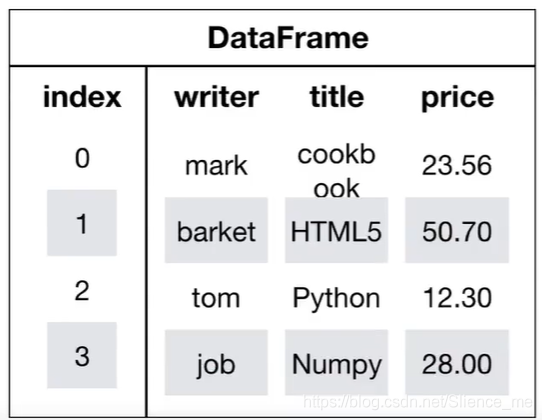
1.3 DataFrame
- 结构:既有行索引,又有列索引的二维数组
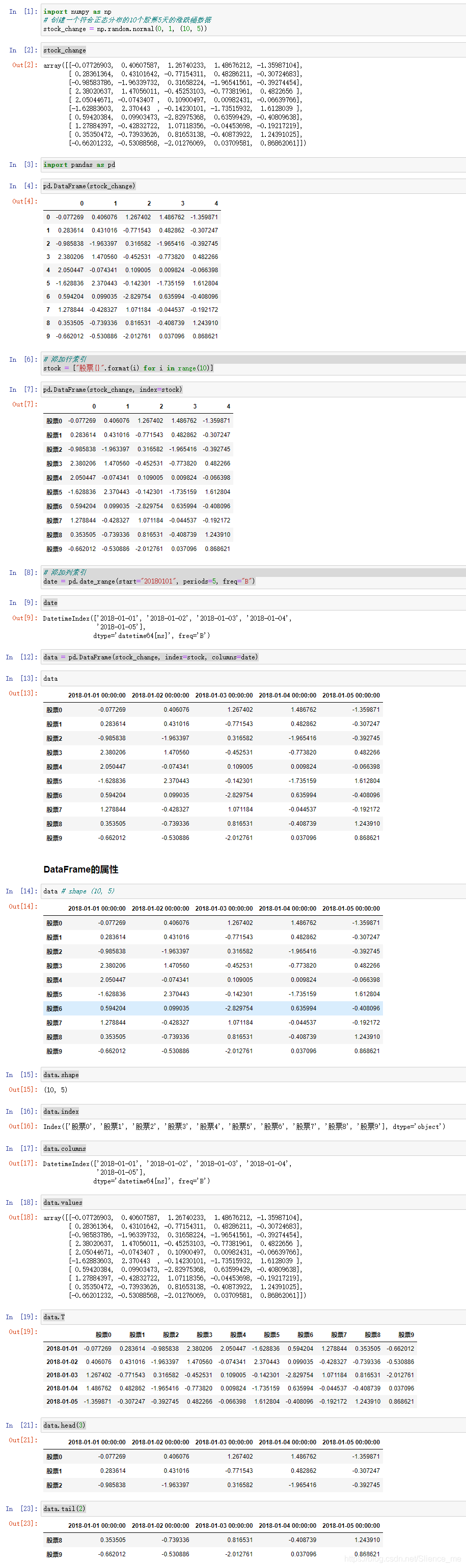
- 属性:
-
shape# (2,3) -
index: 行索引,表名不同行,横向索引,叫index -
columns: 列索引,表名不同列,纵向索引,叫columns -
values:直接获取其中array的值 -
T: 转置
-
- 方法:
-
head()默认显示前5行,可指定head(3) -
tail()默认显示后5行
-
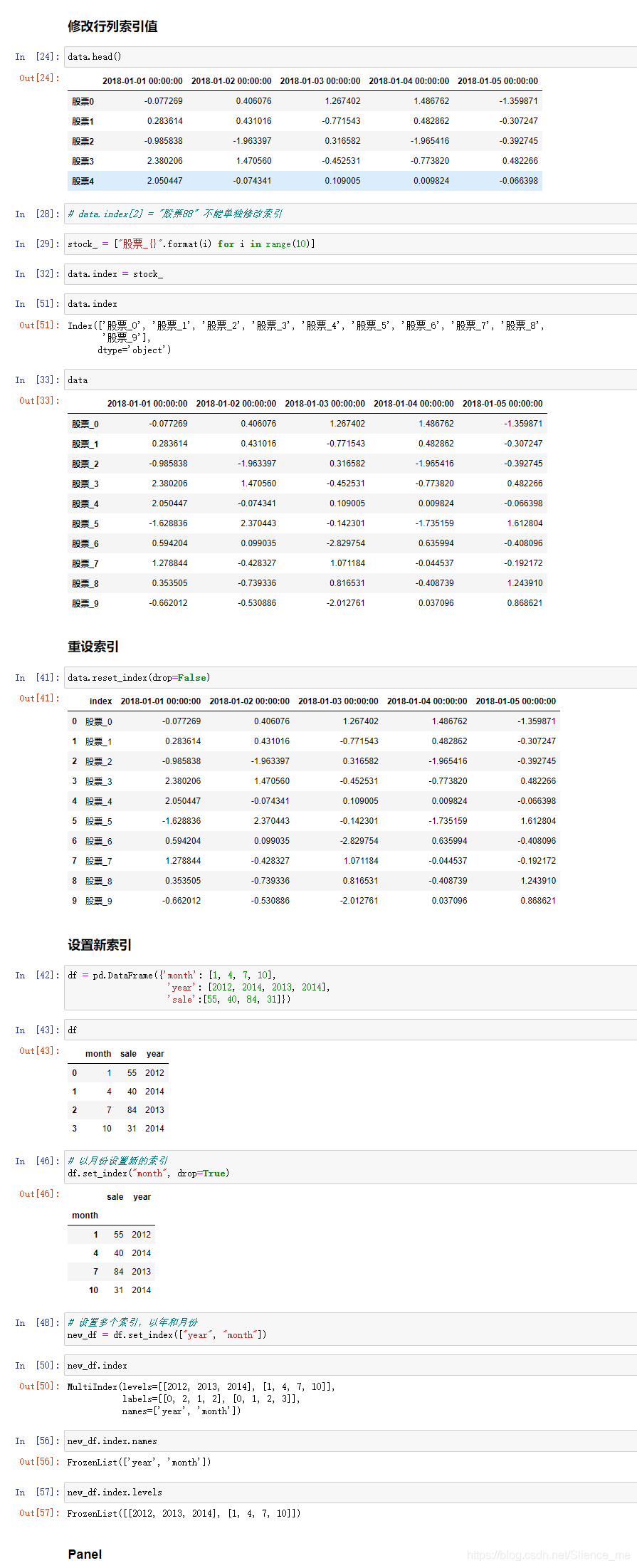
- 3 DataFrame索引的设置
- 1)修改行列索引值
- 2)重设索引
- 3)设置新索引
DataFrame索引的设置
- 以某列值设置为新的索引
-
set_index(keys, drop=True)-
keys: 列索引名称或者列索引名称的列表 -
drop:boolean, default True. 当作新的索引,删除原来的列
-
-
- 2
Panel-
DataFrame的容器
-
- 3
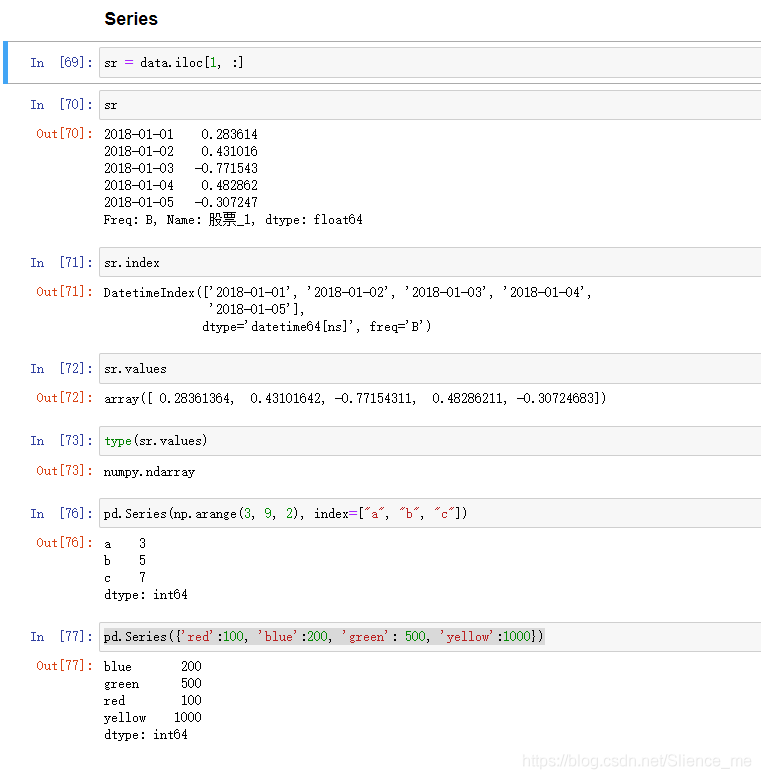
Series- 带索引的一维数组
- 属性
indexvalues
- 总结:
-
DataFrame是Series的容器 -
Panel是DataFrame的容器
-
2. 基本数据操作
2.1 索引操作
- 读取文件
data = pd.read_csv("./stock_day/stock_day.csv")
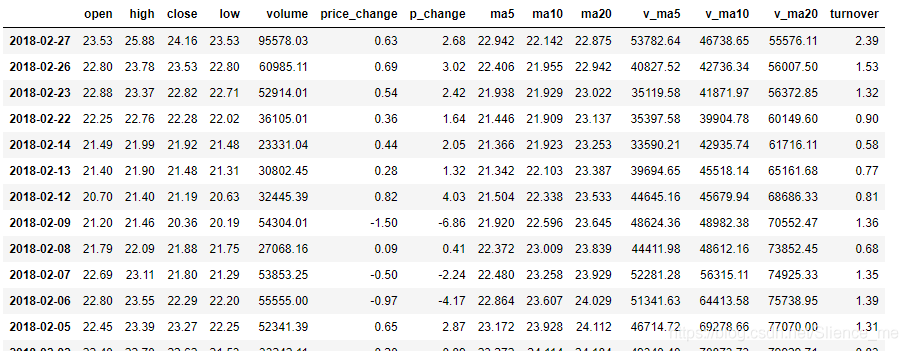
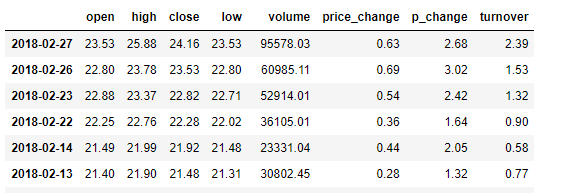
- 删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
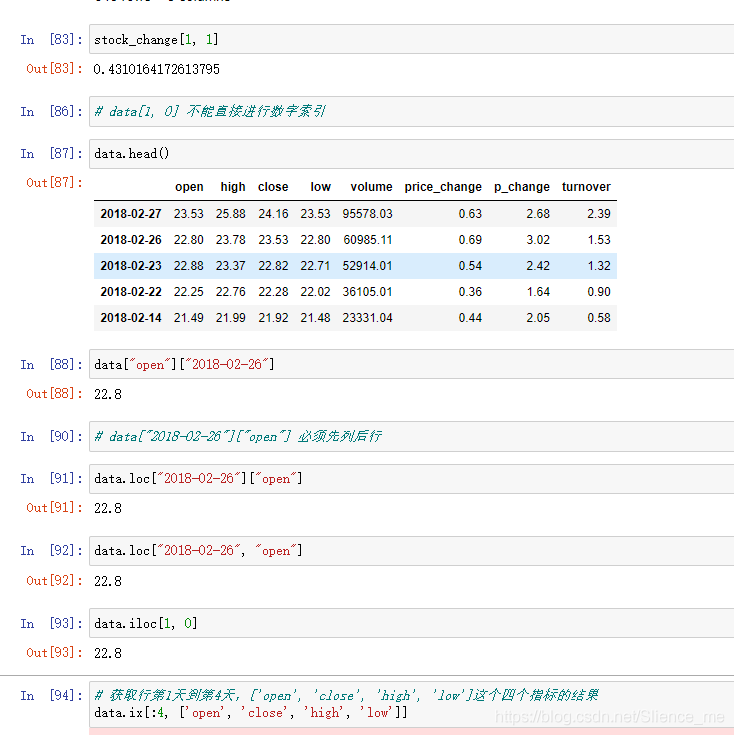
- 直接索引
- 先列后行
- 按名字索引
loc
- 按数字索引
iloc
- 组合索引
- 数字、名字

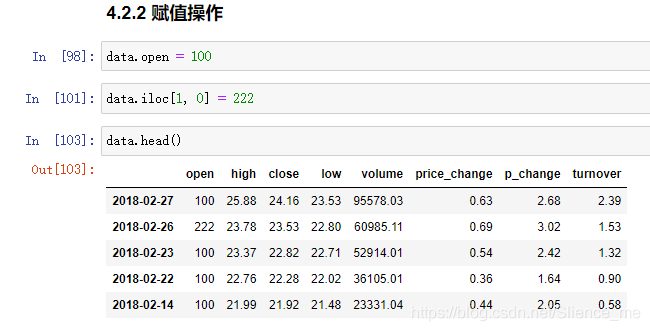
2.2 赋值
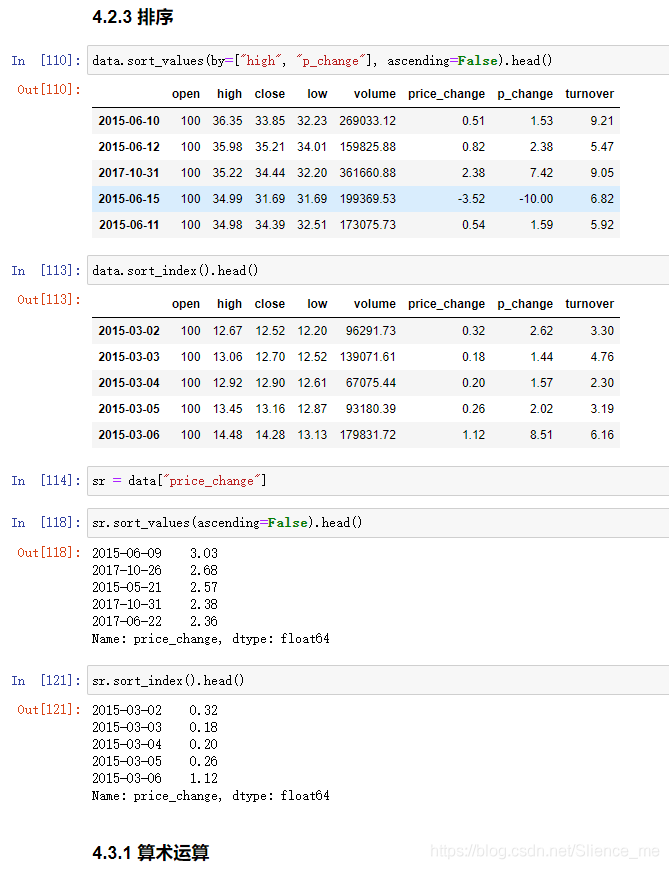
2.3 排序
- 对内容排序
dataframeseries
- 对索引排序
dataframeseries
- 使用
df.sort_values(key= , ascending=)对内容进行排序- 单个键或者多个键进行排序,默认升序
-
ascending=False,降序 -
ascending=True,升序
- 使用
series.sort_values(ascending=)对内容进行排序- series排序时,只有一列,不需要参数
-
ascending=False,降序 -
ascending=True,升序
- 使用
series.sort_index(ascending=)对索引进行排序- 与df一致
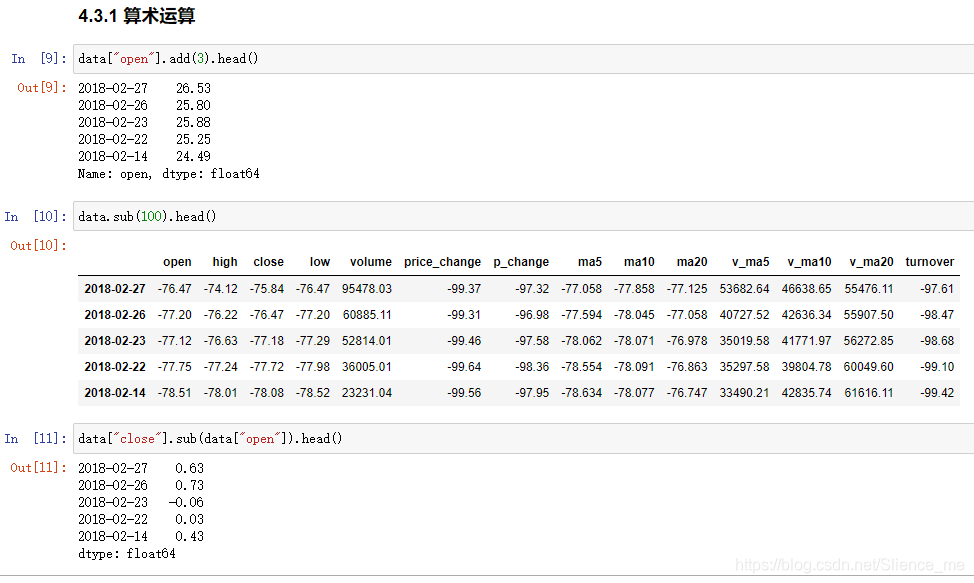
3. DataFrame运算
算术运算
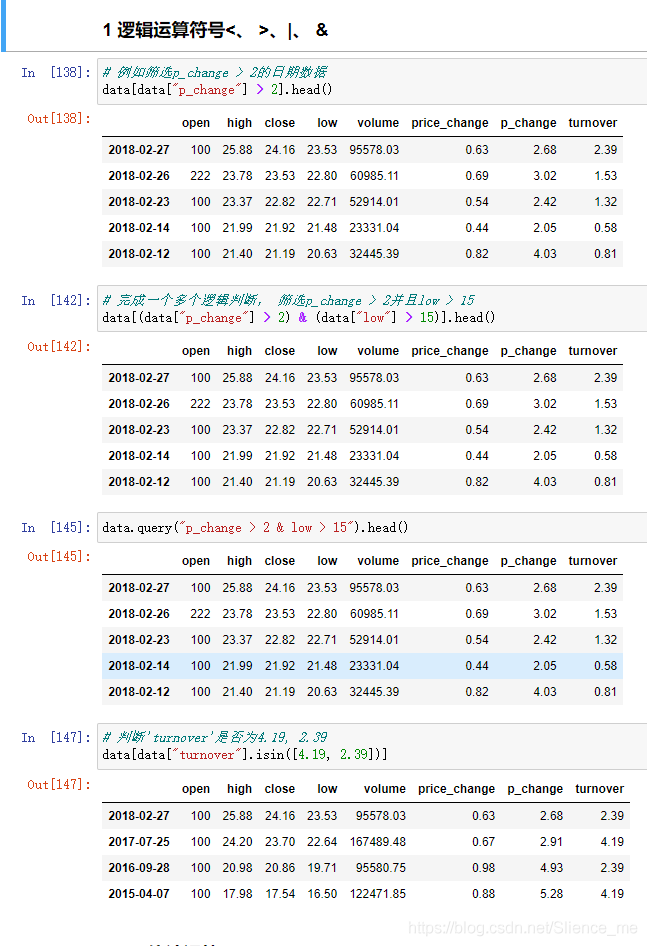
逻辑运算
- 逻辑运算符
- 布尔索引
- 逻辑运算函数
- `query()` 查询
- `isin()` 是不是在条件中
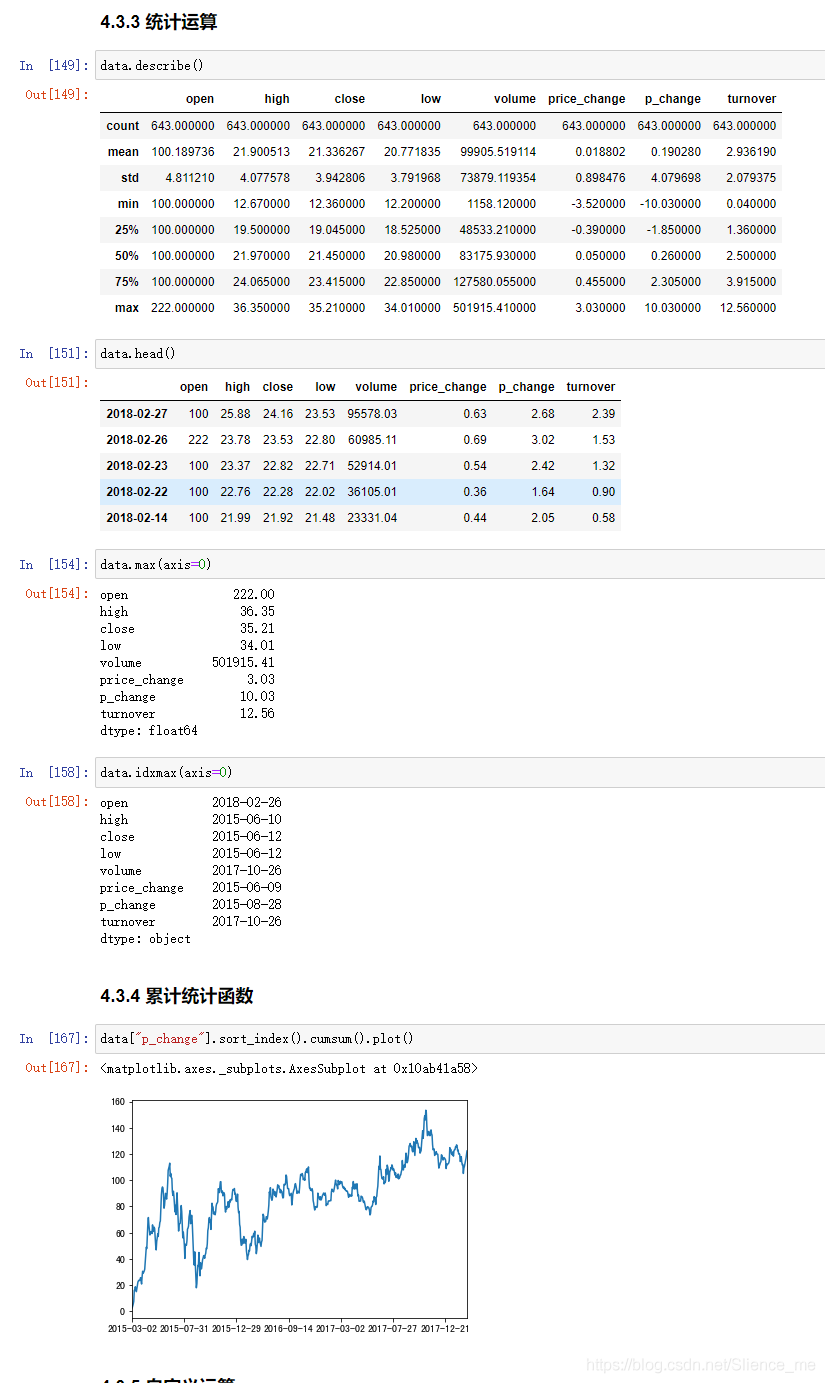
统计运算
-
min max mean median var std最小值,最大值,均值,中位数,方差,标准差
-np.argmax()
-np.argmin()
-describe()能够直接得出很多统计结果,count,mean,std,min,max- 计算平均值,标准差,最大值,最小值
| conut | Number of non-NA observations |
|---|---|
| sum | Sum of values 值的总和 |
| mean | Mean of values 数据的平均值 |
| median | Arithmetic median of values 数据的算数平均值 |
| min | Minimum 最小值 |
| max | Maximum 最大值 |
| mode | Mode 众数 |
| abs | Absolute Value 绝对值 |
| prod | Product of values 值的积 |
| std | Bessel-corrected sample standard deviation 贝塞尔校正样本标准差 |
| var | Uniblased variance 无偏方差;均方差 |
| idxmax | compute the index labels with the maximum 计算索引标签的最大值 |
| idxmin | compute the index labels with the minimum 计算索引标签的最小值 |
-
对于单个函数去进行统计的时候,坐标轴还是按照这些默认为"columns"(axis=0, default), 如果要对行"index"需要指定(axis=1)
自定义运算
-
apply(func, axis=0)-
func:自定义函数 -
axis=0:默认是列,axis=1为行进行运算
-
- 定义一个对列,最大值 最小值的函数
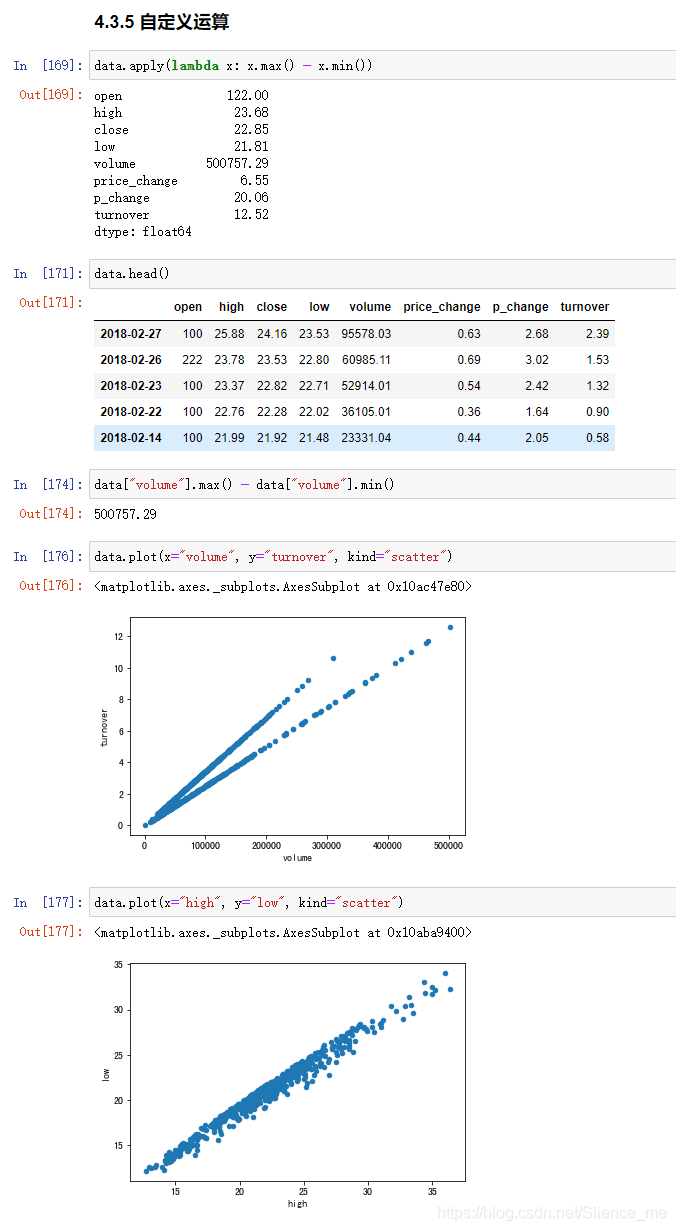
4. Pandas画图
pandas.DataFrame.plot
-
DataFrame.plot(x-None, y=None, kind='line')-
x: label or positon, default None -
y: label, positon or list of label , positions, default None- Allows plotting of one colume versus another 允许绘制一列对另一列
-
kind: str-
'line': line plot (default) 折线图 -
'bar': vertical bar plot -
'barh': horizontal bar plot -
'hist': hisogram 直方图 -
'pie': pie plot 饼状图 -
'scatter': scatter plot 散点图
-
-
5 文件读取与存储
5.1 CSV
1. 读取csv文件-read_csv()
-
pandas.read_csv(filepath_or_buffer, sep=',' , delimiter = None)-
filepath_or_buffer: 文件路径 -
usecols: 指定读取的列名, 列表形式
-
2. 写入csv文件-to_csv()
-
DataFrame.to_csv(path_or_buf=None, sep=',' ,columns=None, header=True, index=True, index_label=None, mode='w', encoding=None)-
path_or_buf: string or file handle, default None -
sep:character, default',' -
columns: sequence, optional -
mode: 'w':重写, 'a':追加 -
index: 是否写进行索引 -
header: boolean or list of string ,default True,是否写进索引值
-
Series.to_csv(path=None,index=True,sep=',',na_rep='',float_format=None,header=False,index_label=None,mode='w',encoding=None,compression=None,date_format=None,decimal='.')
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])
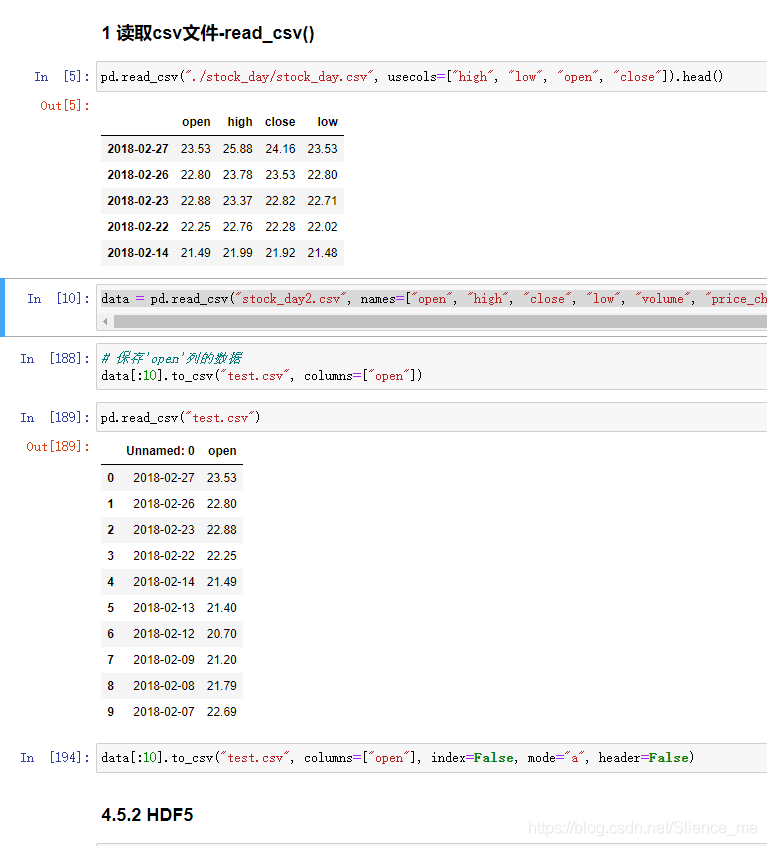
5.2 HDF5
hdf5 存储 3维数据的文件
key1 dataframe1二维数据
key2 dataframe2二维数据
pd.read_hdf(path, key=)
df.to_hdf(path, key=)
1. 读取HDF5文件-read_hdf()
HDF5文件的读取和存储都需要指定一个键,值为要存储的DataFrame
pandas.read_hdf(path_or_buf, key=None, **kwargs)- 从h5文件中读取数据
-
path_or_buf: 文件路径 -
key:读取的键 -
mode:打开文件的模式 -
return:Theselected object
-
需要安装tables模块避免不能读取HDF5文件
pip install tables
2. 写入HDF5文件-to_hdf()
-
DataFrame.to_hdf(path_or_buf, key, **kwargs)-
path_or_buf: 文件路径 -
key:读取的键 -
mode:打开文件的模式 -
return:Theselected object
-
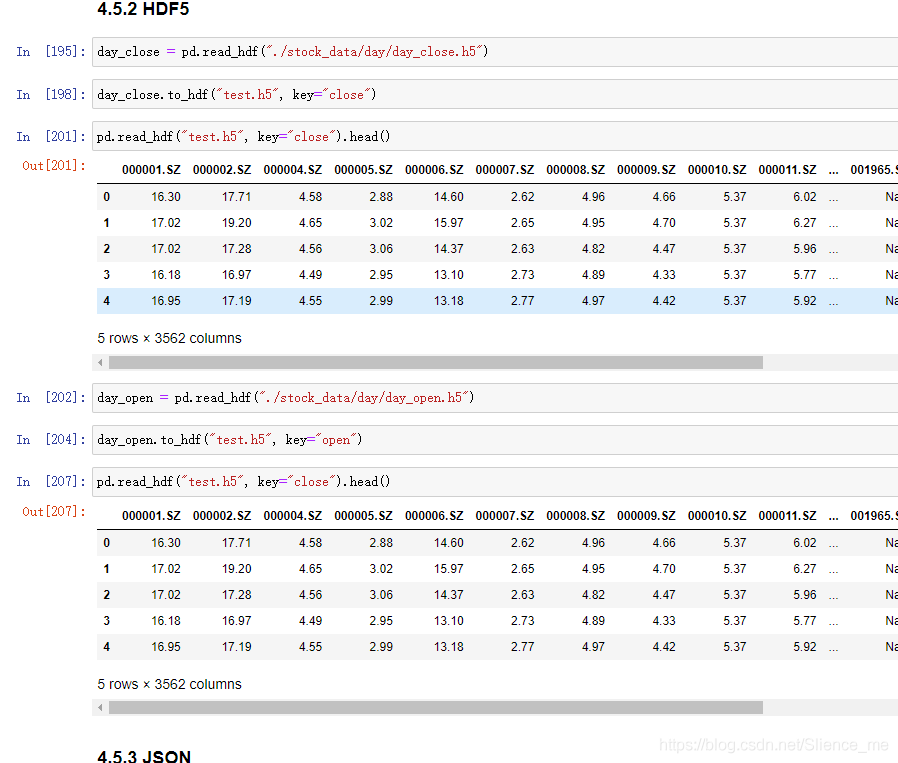
5.3 JSON
1. read_json()
-
pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False)- 将JSON格式准换成默认的Pandas DataFrame格式
-
orient: string, Indication of expected JSON string format.-
'split':dict like {index -> [index], columns -> [columns], data -> [values]} -
'records': list like [{column -> value}, ..., {column -> value}] -
'index': dict like {index -> {column -> value}} -
'columns': dict like {column -> {index -> value}},默认该格式 -
'values': just the values array
-
-
lines: boolean , default False- 按照每行读取json对象
-
typ: default ‘frame’, 指定转换成的对象类型series或者dataframe
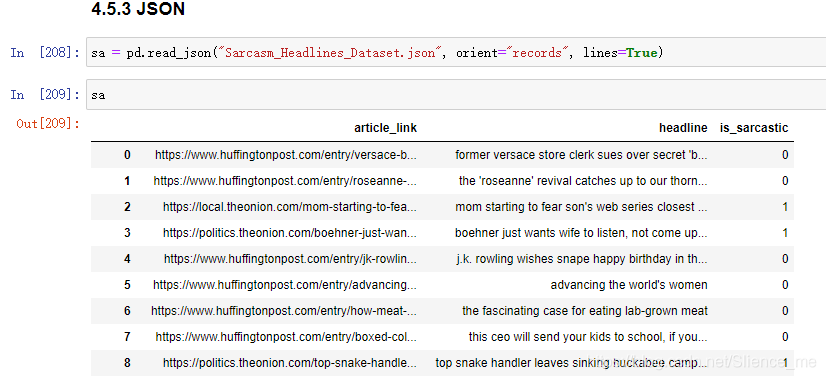
2. to_json()
