本次项目在github上的地址:https://github.com/MaximumRescue/WordCount-Project
写在前面的话
首先我必须要强调,如果你觉得有问题,那一定是你没有认真看下面的说明。
先说一点题外话,从上周任务分配下来到现在,需求在不断变动,描述也非常模糊。既然这只是一周的“小作业”,那么就没有必要把需求模糊化,对于任何一点说明都应该具体清晰,给出的样例必须规范正确,况且如果这门课程的重点在软件质量提升和测试上,那么就不应该在需求上闪烁其辞,这样对大家的开发很不利。这一点还是给开发造成了很大的问题。
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
||
|
· Estimate |
· 估计这个任务需要多少时间 |
15 | 15 |
|
Development |
开发 |
||
|
· Analysis |
· 需求分析 (包括学习新技术) |
60 | 80 |
|
· Design Spec |
· 生成设计文档 |
- | - |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
- | - |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
- | - |
|
· Design |
· 具体设计 |
60 | 90 |
|
· Coding |
· 具体编码 |
500 | 450 |
|
· Code Review |
· 代码复审 |
60 | 40 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
120 | 120 |
|
Reporting |
报告 |
||
|
· Test Report |
· 测试报告 |
120 | 140 |
|
· Size Measurement |
· 计算工作量 |
20 | 15 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
|
合计 |
985 | 980 |
设计思路说明
1. 首先只考虑四个基础功能:统计字符数、单词数、行数,统计结果以指定格式输出到默认文件中。
那么最先想到的一定是模块化,对于以上不同的功能分别构造相应的独立的方法。我个人是不赞成方法的嵌套的,因为很多时候会造成思路的混乱,而且一旦核心功能出了问题,其他模块也就全部崩溃了。
于是这里就开始利用python的文件处理功能以及返回的文件句柄的方法来进行处理。
(1)首先是统计字符功能,很简单f.read()返回一个文件从头到尾的字符串,包括\n,\t等空白字符,因此只需要统计返回的字符串的长度就可以了。
说明:这里的\n,\t均只视作一个字符。
1 # return the character number of a file 2 def char_num(): 3 # open the file with the name 'filename' 4 f = open(filename, 'r') 5 totalstr = f.read() 6 f.close() 7 return filename + ', 字符数:' + str(len(totalstr))
(2)然后是统计行数功能,另一个方法f.readlines()返回一个文件各行组成的列表,只需要统计列表元素个数即可。
1 # return the line number of a file 2 def line_num(): 3 # open the file with the name 'filename' 4 f = open(filename, 'r') 5 lines = f.readlines() 6 f.close() 7 return filename + ', 行数:' + str(len(lines))
(3)统计单词数有一点复杂,但也很简单,我们在上面返回的每一行中进行查找,查找的标准就是正则表达式:单词是由至少两个字母组成的且不含其他符号(不考虑不定冠词a,连接词如five-year-old,缩写如don't这几类特殊词汇)。于是用re.findall(r'[A-Za-z]{2, }')就可以筛选出所有的单词了。
1 # return the word number of a file 2 def word_num(): 3 # open the file with the name 'filename' 4 f = open(filename, 'r') 5 lines = f.readlines() 6 f.close() 7 # get the word by regex expression 8 linewords = [] 9 for i in range(0, len(lines)): 10 linewords.append(re.findall(r'[A-Za-z]{2,}', lines[i])) 11 # count the number of words 12 count = 0 13 for lineword in linewords: 14 for word in lineword: 15 if word.isalpha() == False or len(word) == 1: 16 lineword.remove(word) 17 if lineword != ['']: 18 count += len(lineword) 19 return filename + ', 单词数:' + str(count)
(4)写入文件利用f.write()方法就可以写入了,注意打开时的mode必须是a(追加),不然会抹掉之前所有的记录。
1 # write the information to the file 2 def write_file(filename, info): 3 f = open(filename, 'a') 4 f.write(info) 5 f.close()
这几个部分的实现还算比较简单。但是显然这些方法共用一个参数,所以为了方便起见,我设计了一个类包含了所有的方法,具体内容请参考上面的链接。
2. 接下来是关于扩展功能的说明
扩展功能为:递归处理目录下符合条件的文件;返回代码行/空行/注释行;忽略停用词表的单词(保留字)。
(1)先从最简单的保留字处理开始说,这个与之前单词处理很类似,区别是要除掉保留字,于是我们只需要构造一个保留字列表,判断得到的单词在不在表中,如果在则删掉,统计保留下来的单词数即可,于是我们把之前的方法进行改写即可。获取保留字的方法类似于获取单词的过程:
1 # get the preserved words list 2 def get_prelist(fname): 3 filename = join(sys.path[0], fname).replace('\\', '\\\\') 4 fhandle = open(filename, 'r') 5 wholestr = fhandle.read() 6 prelist = wholestr.split(' ') 7 for word in prelist: 8 if word == "" or word == "\n" or word == "\t": 9 prelist.remove(word) 10 return prelist
(2)接下来说明一下对行的精确统计工作,正如我们在前面说明的,f.readlines()返回的是一个由各行字符串组成的列表,那么我们对每一个字符串做一些处理:
先使用str.replace(a, b)方法将字符串中的换行符,制表符和空格全部去掉,接下来就进行判断:
如果开头是'//'的话就作为注释行,不考虑多行注释;如果一行只有一个字符或没有字符就作为空行;其他全部视为代码行。
1 # return line details of a file 2 def line_detail(): 3 # open the file with the name 'filename' 4 f = open(filename, 'r', encoding='utf-8') 5 # get all line string into a list 6 lines = f.readlines() 7 f.close() 8 # distinguish different lines 9 codelines, emptylines, commentlines = [], [], [] 10 for line in lines: 11 tmpline = line.replace(' ', '') 12 tmpline = tmpline.replace('\t', '') 13 tmpline = tmpline.replace('\n', '') 14 if len(tmpline) == 1 or len(tmpline) == 0: 15 emptylines.append(line) 16 elif tmpline.startswith('//'): 17 commentlines.append(line) 18 else: 19 codelines.append(line) 20 return filename + ', 代码行/空行/注释行:' + str(len(codelines)) + '/'\ 21 + str(len(emptylines)) + '/' + str(len(commentlines))
(3)关于嵌套处理文件夹下所有的符合条件的文件,我们把问题进行分治:
第一,我们需要获取文件类型,这个的思路很简单,我们在命令行中获取相应参数,利用字符串尾部截取即可获得对应的文件类型。
第二,我们根据获取的文件类型,在整个执行文件夹下进行递归查找,返回得到的文件的绝对路径列表。
1 # determine the type needed 2 tmplist = desfile.split('.') 3 type = '.' + tmplist[-1] 4 # get the required list 5 localinfo = directory.build_infolist(type) 6 # build up the information list from the file list 7 def build_infolist(type=''): 8 filenames = build_filelist(type) 9 dirnames = build_dirlist() 10 # get information by creating a FileInfo object 11 infos = [] 12 for fname in filenames: 13 info = FileInfo(path, fname) 14 infos.append(info) 15 # deal with the inner directory 16 for dirname in dirnames: 17 new_path = join(path, dirname) 18 newdir = DirInfo(new_path) 19 new_infos = newdir.build_infolist(type) 20 infos = infos + new_infos 21 return infos
3. 高级功能:显示图形界面,用户通过界面选取单个文件,程序显示相关统计信息。
同样是分治,一部分是通过显示对话框获取文件路径和文件名,另一部分就是将获取的信息做上面的操作。
难点在于显示对话框,显示对话框需要使用wx库,利用里面的FileDialog方法创建对话框,FileDialog.getdirectory()和FileDialog.getname()获取文件路径和文件名。给一些示例代码:
注意:这里只显示字符数,行数,单词数(无保留字)
1 # A method to get filename by dialog 2 def dialog_get(): 3 app = wx.App() 4 frame = wx.Frame(None) 5 openwildcard = "All files(*.*)|*.*|" + \ 6 "C/C++ files(*.c;*.cpp;*.h)|*.c;*cpp;*.h|" + \ 7 "Java source files(*.java)|*.java|" + \ 8 "Python source files(*.py)|*.py|" + \ 9 "Text files(*.txt)|*.txt" 10 # Create open file dialog 11 openFileDialog = wx.FileDialog(frame, "Choose a file to open", 12 wildcard=openwildcard, 13 style=wx.FD_OPEN | wx.FD_FILE_MUST_EXIST) 14 openFileDialog.ShowModal() 15 dir = openFileDialog.GetDirectory() 16 filename = openFileDialog.GetFilename() 17 openFileDialog.Destroy() 18 return dir, filename
源代码模块说明
| FileInfo.py | class FileInfo |
Attributes: path, fname, filename Methods: char_num(), word_num(prelist), line_num(), line_detail(), write_info() |
| DirInfo.py | class DirInfo |
Attributes: path Methods: build_filelist(tyoe), build_dirlist(), build_infolist(type) |
| ExtraOpt.py | - | Methods: get_prelist(fname), dialog_get() |
| main.py | - | (No methods, but some important codes used as main() in java) |
最后其实还有一个setup.py文件用于将脚本文件打包成exe文件,但这不是我们实现项目的重点,因此没有列出来。
软件运行说明
1. .exe文件运行注意要点:
首先说明一下将python脚本文件打包成exe文件的方法,事先你要安装py2exe库,然后构造一个setup.py文件用于打包,对于这个文件用命令行运行:
python <filename>.py py2exe
setup.py文件组织可以是这样的:
1 from distutils.core import setup 2 import py2exe 3 setup(console=["main.py"])
那么打包出来的情况是怎么样的呢?打包过程先创建一个dist文件夹,然后将PythonXX原文件夹里的部分文件复制到这里来,然后构造一些运行必需的注册表。大概的文件结构如下图所示:
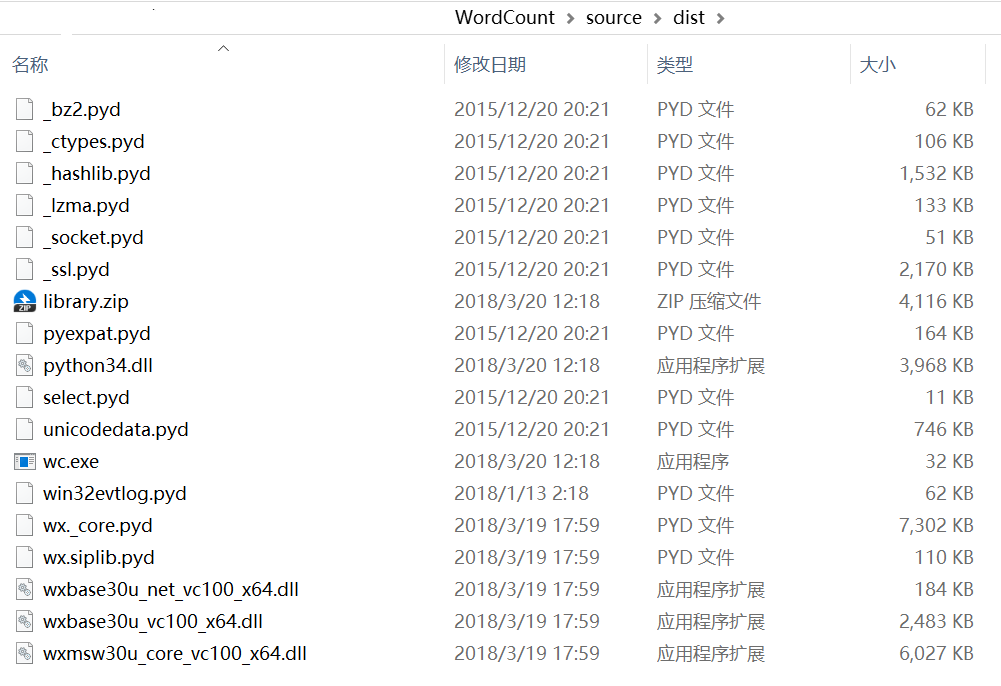
因此如果需要运行的话,必须把所有文件放在一个文件夹里,内容均在BIN文件夹里。其他运行和.exe文件运行类似。
2. 如果.exe文件运行不了的话,可以下载__pycache__文件夹里的.pyc文件和main.py文件,放在一个文件夹下,用python命令运行。
Python版本3.4以上,运行代码:
python main.py [arguments]
3. 如果上面的都不行的话,保证Python 3.4+,安装wxPython库,下载所有.py文件,运行main.py脚本,其他和2.中内容相同。
测试过程设计
1. 先说明一下写完以后对代码的初步评估:
(1)命令行参数处理的结构不够优化,这个部分也很无奈,我采用的字典构造方法是将文件和对应操作参数关联,但这种是否是最优方法,我依旧存疑,关于这个方面需要参考DOS或者python终端的参数处理方法;
(2)这里考虑到一种简单的情况,即文件都能打得开,没有添加异常处理机制,但是我认为异常处理是必须的,时间有限没有加以完善。
(3)文件部署和模块化设计似乎还有一些提升空间。
总之,我觉得这里还是需要做一些优化的,关于python debugger等等工具还是要学一下的。
2. 具体测试:篇幅有限,给出三个文件及部分结果显示:
(1)图形界面测试:命令:
wc.exe -x
file_1.c
1 {1} 2 2
file_2.c
1 a 2 a/ 3 a+b
file_3.c
1 --- 2
显示的界面如下:
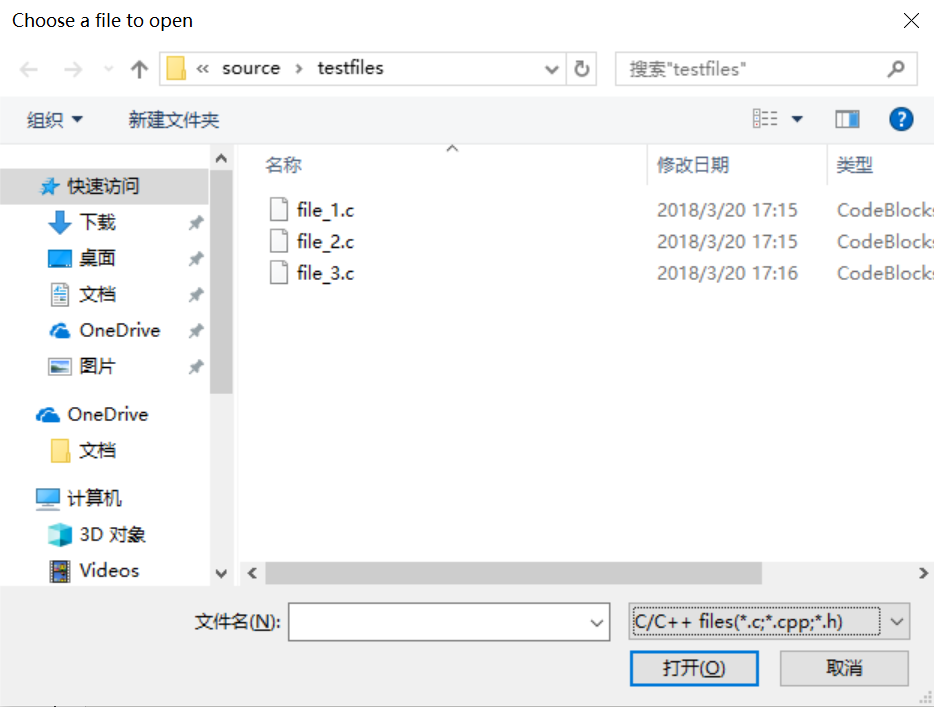
输出的结果如下:
1.
file_1.c, 字符数:5 file_1.c, 行数:2 file_1.c, 单词数:0 2.
file_2.c, 字符数:8 file_2.c, 行数:3 file_2.c, 单词数:0 3.
file_3.c, 字符数:4 file_3.c, 行数:1 file_3.c, 单词数:0
(2)单个文件命令测试:
testfile.c
1 { 2 }// 3 // 4 a 5 aasa// 6 while and or if endif
StopList.txt
while if for
那么测试各个命令:
4. wc.exe -c testfile.c testfile.c, 字符数:52 5. wc.exe -w testfile.c testfile.c, 单词数:6 6. wc.exe -l testfile.c testfile.c, 行数:6 7. wc.exe -a testfile.c testfile.c, 代码行/空行/注释行:3/2/1 8. wc.exe -w testfile.c -e StopList.txt testfile.c, 单词数:4 9. wc.exe -s -c -w -l *.c -e StopList.txt file_1.c, 字符数:5 file_1.c, 单词数:0 file_1.c, 行数:2 file_2.c, 字符数:8 file_2.c, 单词数:0 file_2.c, 行数:3 file_3.c, 字符数:4 file_3.c, 单词数:0 file_3.c, 行数:1 testfile.c, 字符数:52 testfile.c, 单词数:4 testfile.c, 行数:6 10. wc.exe -c -w -l -a testfile.c -o result.txt testfile.c, 字符数:52 testfile.c, 单词数:6 testfile.c, 行数:6 testfile.c, 代码行/空行/注释行:3/2/1
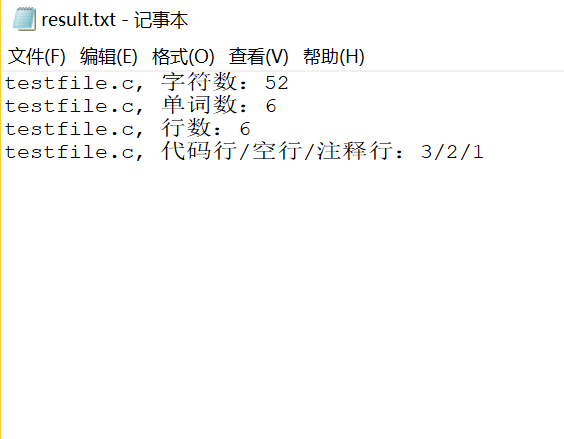
这里显示的正确的结果,过程中出过几个问题并改正过来了:
1)-e 过程文件无法读取:原因:get_prelist()获取路径错误,打包成exe后路径需要重新定向
解决方法:把cur_file_dir()放到ExtraOpt.py中使用该方法路径就重新调好了。
2)-w -e重复输出:原因:两个设置在不同的判断条件中,并没有同时判断。
解决方法:把关于保留字列表的处理放在-w的处理过程中,-e单独获取列表。
目前还没有出现其他问题,但是一定要注意命令行的正确使用,错误的命令行得不到正确的结果。
小结
这次项目内容还是比较充实的,说起来大家都是快毕业的人了,上过的课也都不少了,有经验的人都明白,构建一个项目,不管它再小,有意无意地都会尽量保证一个相对清晰合理的构架。很多厉害的同学写出来的代码都是模块划分非常清晰,结构非常规整的,其健壮性和可重用性都很高。这种做法往往就意味着更高的工作量。搜索信息还是有些困难的,在搜索引擎中百度属于最低一级,必应属于中级,google才是高级(虽然不能用),搜索出来的常常不能满足要求,需要大量查找和人工筛选。而像CSDN,博客园,开源中国这些专业网站上的博客抄袭转载的很多,而且更新的很慢(也许现在大家都去做框架或者AI去了,没人管基础内容的更新),使用语言的特性很多都是已经被淘汰的,新特性在官方文档上的说明和范例并不是那么好懂的(手册类的文档,又不是教材)。经常会出现你想找一种功能的实现方法,跳出来的大多是垃圾信息或者无用的内容,可以说在开发过程中很大一部分时间是浪费在提取有用信息的过程上。
但是做出来了整个过程还是很值得的。不过话说回来,虽然我的测试目前没有检测到问题,但还是需要进一步测试,更加复杂的测试用例是必要的。总之如果上面的设计过程或实现方法有什么问题,希望大家不吝赐教。