爬虫简介
爬虫:一段自动抓取互联网信息的程序。
什么意思呢?
互联网是由各种各样的网页组成。每一个网页对应一个URL,而URL的页面上又有很多指向其他页面的URL。这种URL之间相互的指向关系就形成了一个网络,这就是互联网。
正常情况下就是我们采用人工点击的方式,去获取互联网上指定的信息,这种方式的特点是覆盖面小。
那有没有可能有一种方式,是当我们设定了一个互联网上感兴趣的目标,然后自动地从互联网上去获取我们所需要的数据呢?
有,这就是爬虫。它可以从一个URL出发访问该URL所关联的所有URL,并且从每个页面上提取出我们所需要的价值数据。
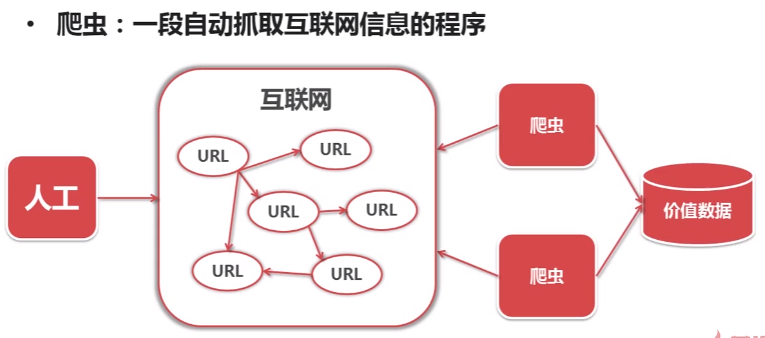
也就是说,爬虫就是自动访问互联网,并且提取数据的程序。
爬虫技术的价值
互联网数据,为我所用。
Python简单爬虫架构
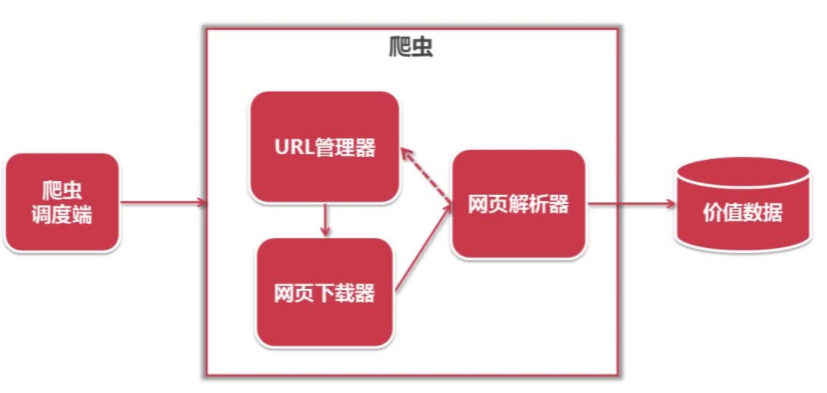
1)首先,我们需要一个爬虫调度端。爬虫调度端的作用:启动爬虫,停止爬虫,监视爬虫运行情况。
2)在爬虫程序中有三个模块:URL管理器、网页下载器、网页解析器。
3)URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出待爬取的URL,将其传送给“网页下载器”。
4)网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”。
5)网页解析器:解析网页可解析出
①有价值的数据
②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”
此时,这三个模块就形成了一个循环,只要有感兴趣的URL,这三个模块就会一直循环下去。
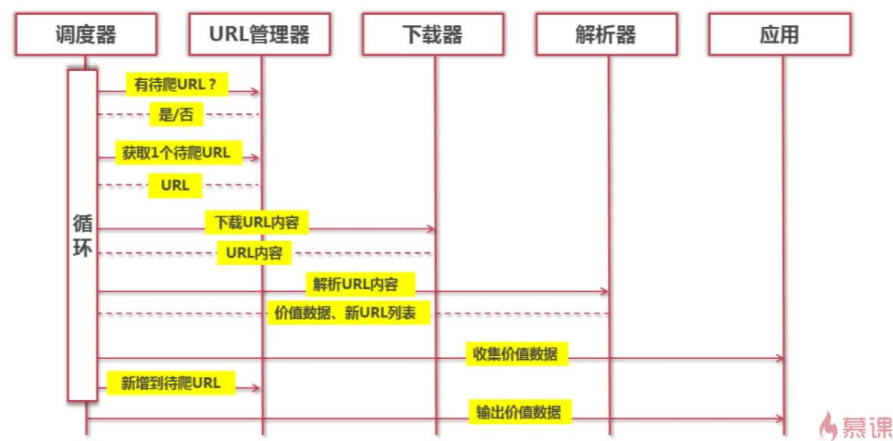
Python简单爬虫架构的动态运行流程(以时序图的方式展示)
Python爬虫URL管理
URL管理器:管理待抓取URL集合和已抓取URL集合。
目的:防止重复抓取、防止循环抓取。
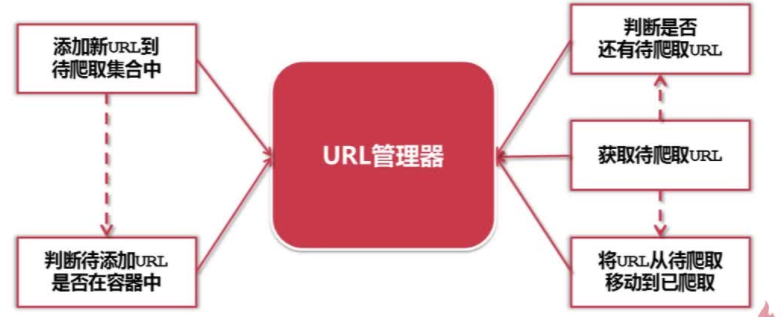
Python爬虫URL管理器的实现方式
Python爬虫URL管理器的实现方式具体有三种:
1)使用内存,在Python中主要使用set集合(方便去除重复的元素)

2)使用关系数据库,使用两个字段:url和is_crawled(用来标记是否被爬取)

3)使用缓存数据库,同样使用set集合

其中,大型公司一般选择高性能的缓存数据库。个人,小公司一般使用内存。若是想永久存储,常使用关系数据库。
Python爬虫网页下载器简介
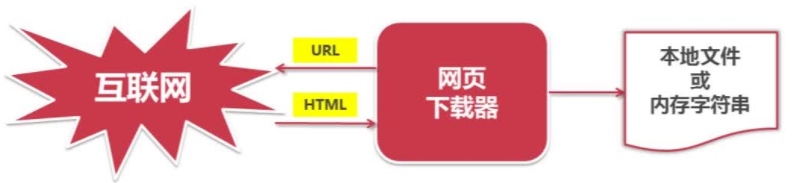
网页下载器:一个工具,通过URL将互联网上对应的的网页以HTML的形式下载到本地存储成本地文件或内存字符串,后进行后续处理;
Python有哪几种网页下载器:urllib2(Python官方模块,基础模块)、requests(第三方模块,功能强大)。
Python爬虫urlib2下载器网页的三种方法
1)urllib2下载网页方法1:最简洁方法
将url直接传给urllib2的urlopen()方法。
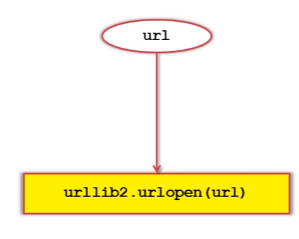
对应代码:

2)urllib2下载网页方法2:除url外,添加data、http header。
进行增强处理。
其中,data向服务器提交需要用户输入的数据。
http header用来向服务器提交http的头信息。
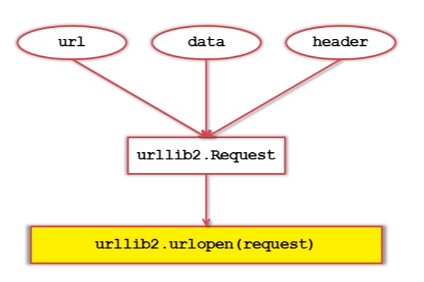
对应代码:

代码中request.add_data('a','1') #添加的数据类型为键值对,即a=1。
request.add_header() #可以对url请求进行伪装
3)urllib2下载网页方法3:添加特殊情景的处理器
更大更强的功能处理能力。
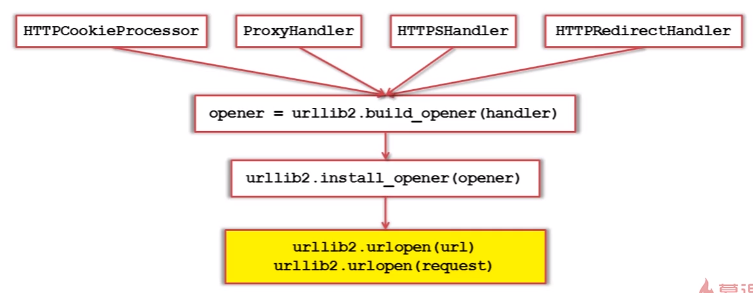
对应代码(举例:增强cookie的处理)
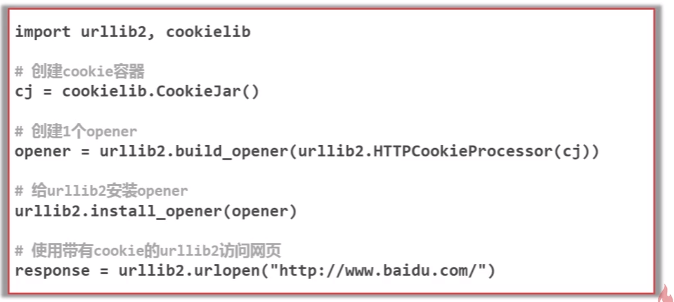
Python爬虫urlib2实例代码演示
import urllib2
url ="http://www.baidu.com"
print '第一种方法' respones1 = urllib2.urlopen(url) print respones1.getcode() print len(respones1.read())
print "第二种方法" request = urllib2.Request(url) request.add_header("user-agent","Mozillla/5.0") respones2 = urllib2.urlopen(request) print respones2.getcode() print len(respones2.read()) print '第三种方法' cj =cookielib.CookieJar() opener = urllib2.bulid_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) print respones3.getcode() print cj print respones3.read()
本篇博客参考慕课网课程:https://www.imooc.com/video/10683