目录
1 什么是文件 1
2 打开的文件模式 1
2.1 模式规则 1
2.2 过程分析: 1
2.3 模式: 1
2.3.1 打开文件的模式有(默认为文本模式): 2
2.3.2 对于非文本文件,我们只能使用b模式, 2
2.3.3 了解部分 2
2.4 文件路径 2
2.5 案例: 3
2.5.1 过程分析 3
2.6 强调 3
2.6.1 强调第一点: 3
2.6.2 强调第二点: 4
3 python2与python3 的不同 4
4 操作文件的方法 4
4.1 read 4
4.1.1 readline当文件太大时 5
4.1.2 readlines, 5
4.2 write 6
4.3 a,追加 6
4.4 b:byte字节 7
4.5 r+读写 7
4.6 W+写读 7
5 文件内光标的移动 8
5.1 Seek移动光标 8
5.2 Truncate截断文件 8
5.3 Tell 返回光标所在的位置 8
6 文件的操作 9
1 什么是文件
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量
#2. 通过句柄对文件进行操作
#3. 关闭文件
2 打开的文件模式
2.1 模式规则
文件句柄=open(‘文件名/文件路径’,‘模式’,‘字符集’)
2.2 过程分析:
(1) 由应用程序向操作系统发起系统调用open()
(2) 操作系统打开该文件,并返回一个文件句柄给应用程序
(3) 应用程序将文件句柄赋值给变量f
2.3 模式:
rwa(追加写),r+,w+,rb,wb,ab,r+b,w+b,a+b,a+(追加写读)
|
Character |
Meaning |
|
‘r' |
读 |
|
‘w' |
写入。只要操作了就会清空源文件。在继续写入就不会清空。如果文件不存在,会自动创建文件 |
|
‘a' |
追加 |
|
‘b' |
二进制 |
|
‘t' |
文字 |
|
‘+' |
打开磁盘文件进行更新(读写) |
|
‘U' |
通用换行模式(为了向后兼容;不应在新代码中使用) |
2.3.1 打开文件的模式有(默认为文本模式):
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
w,只写模式【不可读;不存在则创建;存在则清空内容】
a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】
2.3.2 对于非文本文件,我们只能使用b模式,
"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
2.3.3 了解部分
"+" 表示可以同时读写某个文件
r+, 读写【可读,可写】
w+,写读【可读,可写】
a+, 写读【可读,可写】
x, 只写模式【不可读;不存在则创建,存在则报错】
x+ ,写读【可读,可写】
xb
2.4 文件路径
相对路径(常用)
绝对路径
../表示上一层路径
2.5 案例:
#1. 打开文件,得到文件句柄并赋值给一个变量
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
#2. 通过句柄对文件进行操作
data=f.read()
#3. 关闭文件
f.close()
2.5.1 过程分析
#1、由应用程序向操作系统发起系统调用open(...)
#2、操作系统打开该文件,并返回一个文件句柄给应用程序
#3、应用程序将文件句柄赋值给变量f
2.6 强调
2.6.1 强调第一点:
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为:
1、f.close() #回收操作系统级打开的文件
2、del f #回收应用程序级的变量
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源,
而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close()
虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文
with open('a.txt','w') as f:
pass
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
强调第一点:资源回收
2.6.2 强调第二点:
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
f=open('a.txt','r',encoding='utf-8')
3 python2与python3 的不同
#首先在python3中操作文件只有一种选择,那就是open()
#而在python2中则有两种方式:file()与open()
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,我们一般使用open()打开文件进行操作,而用file当做一个类型,比如type(f) is file
4 操作文件的方法
4.1 read
f.read() #读取所有内容,光标移动到文件末尾
f.readline() #读取一行内容,光标移动到第二行首部
f.readlines() #读取每一行内容,存放于列表中
了解
f.readable() #文件是否可读 f.writable() #文件是否可读 f.closed #文件是否关闭 f.encoding #如果文件打开模式为b,则没有该属性 f.flush() #立刻将文件内容从内存刷到硬盘 f.name
4.1.1 readline当文件太大时
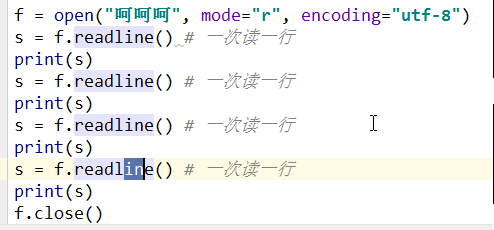
---->结果一行一行读下去,会出现许多空行
文件中的每一行本身有换行的功能,加上print()默认有换行的功能
----->去掉很多行
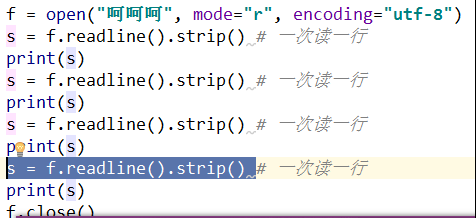
---->但问题是这样太麻烦,能不能用循环?

4.1.2 readlines,
返回一个列表,将文件中的每一行作为列表中的每一项返回一个列表
#4.读文件的第四种方式:readlines,返回一个列表,将文件中的每一行作为列表中的每一项返回一个列表
f = open('1.歌词.txt',encoding='utf-8')
content = f.readlines()
print('readlines : ',content) # readlines : ['111\n', '222\n', 'aaa\n', 'bbb\n', '哇哈哈\n', 'QQ星']
f.close()
4.2 write
带w的:只要你操作了,就会清空源文件,在写就不清空
如果文件不存在,会自动创建文件
f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) #文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
f.flush() #立刻将文件内容从内存刷到硬盘
4.3 a,追加

4.4 b:byte字节
处理的是非文本文件

4.5 r+读写


read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
4.6 W+写读

5 文件内光标的移动
5.1 Seek移动光标
文件内光标移动都是以字节为单位
移动到开头 seek(0)
移动到结尾seek(0,2)
seek(偏移量,位置)
注意:seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
5.2 Truncate截断文件
是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果

5.3 Tell 返回光标所在的位置
告诉光标所在的位置

6 文件的操作
步骤:
引入0s模块
打开目标文件,r
打开文件副本,w
从r中读取内容进行修改,写入到副本
删除源文件
重命名副本
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace('alex','SB') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f:
line=line.replace('alex','SB')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
例子:
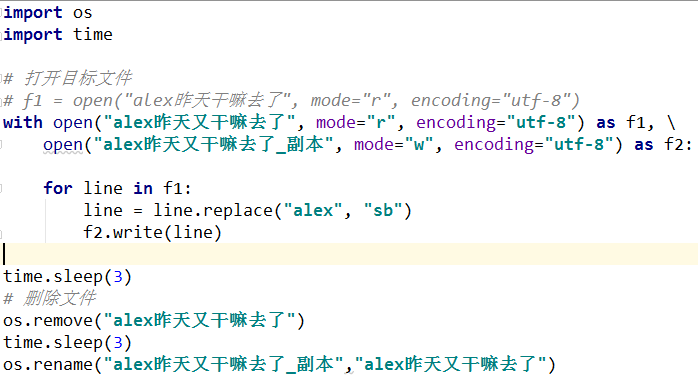
例子:小护士.txt
id,name,phone,car,home,salary
1,alex,10086,特使啦,于新竹,50000
2,wusir,10010,五菱,青年,500000
---------》打印成下面的效果:
{'id': '1', 'name': 'alex', 'phone': '10086', 'car': '特使啦', 'home': '于新竹', 'salary': '50000'}
------à代码
lst = []
with open('小护士.txt',mode='r',encoding='utf-8') as f:
first = f.readline().strip().split(",") #第一行单放
print(first)
for line in f :
dic = {}
ls = line.strip().split(',') #切割
for i in range(len(first)):
dic[first[i]] = ls[i]
lst.append(dic)
print(lst)