一、模块的使用
模块定义:一系列功能的集合体
分为三大类:1.自定义模块
2.内置模块(比如 time,os,sys)
3.第三方模块
模块的表现形式:
1.使用python编写的py文件
2.已被编译为共享库或DLL的C或C++扩展
3.把一系列模块组织到一起的文件夹(ps:文件夹下有一个__init__.py文件,该文件夹称为包)
4.使用C编写并链接到python解释器的内置模块
为什么要用模块:
1.可以拿来内置、第三方的模块,然后直接使用,这种拿来就用的方式,会极大的提升开发效率
2.将程序中共用的一些功能组织到一个文件中,然后程序各部分组件可以重用该文件中的功能。
优点是 减少代码冗余,增强程序的组织结构性与可维护性
怎么用模块:
一个py文件就是一个模块,如果文件名为modules.py,模块名则为modules
ps:模块的使用必须搞清楚谁是执行文件,谁是被导入的模块
1、模块的使用之import


#:coding:utf-8 #modules.py print('from the modules.py') money=1000 def read1(): print('modules模块.read1',money) def read2(): print('modules模块.read2') read1() def change(): global money money=0


import modules money=111111111111 print(modules.money) print(modules.read1) print(modules.read2) print(modules.change) modules.money=2222 print(money)###结果为money=111111111111 modules.read1()#modules模块.read1 2222 #这个更改成功modules.money=2222 def read1():#此处定义read1 print('run.py中的read1') modules.read1()#执行结果仍为modules模块.read1 2222 money=20000000 modules.change()#此处执行了modules中change函数 print(money)###此处为上述money=20000000 print(modules.money)##结果为0 import modules as spam ##可以as 起个别名 print(spam.money) #依旧执行成功 结果为0
执行文件:run.py 被导入模块是:modules.py
首次导入模块会发生三件事:
1、创建一个模块modules.py的名称空间
2、执行模块对应的文件modules.py,将产生的名字丢到模块的名称空间中
3、在当前执行文件的名称空间中拿到一个名字modules,该名字就是指向模块modules.py的名称空间的
import modules# modules=modules.py名称空间的内存地址
ps:
在当前执行文件中引用模块中的名字语法为:modules.名字,必须加上modules.作为前缀
modules.名字相当于指名道姓地跟某一个名称空间要名字,根本不会与当前执行文件的名字冲突
2、模块的使用之 from import


#modules.py # print('from the modules.py') __all__=['money','read1'] money=1000 def read1(): print('spam模块.read1',money) def read2(): print('spam模块.read2') read1() def change(): global money money=0


from spam import money,read1,read2,change # def read1(): print('run.py.read1') read1() # run.py.read1 read2() # spam模块.read2 ------------> spam模块.read1 1000 from spam import money as my print(my) #1000 # =========================================== from spam import * # * 会检索被导入模块中的__all__指定的名字,如果没有该变量那默认导入所有 print(money) #1000 print(read1) # <function read1 at 0x0000000001EB1C80> # print(read2) #会报错 # print(change) #会报错
执行文件:run.py 被导入模块: spam.py
首次导入模块会发生三件事
1、创建一个模块spam.py的名称空间
2、执行模块对应的文件spam.py,将产生的名字丢到模块的名称空间中
3、在当前执行文件的名称空间中拿到一个名字money,该名字就是指向模块spam.py的名称空间的那个money
from spam import money,read1,read2,change
两种导入方式的对比
相同点:函数的作用域关系在定义阶段就规定死了,与调用位置无关
from import
优点:可以不用加前缀而直接引用名字,更简洁
缺点:容易与当前执行文件中的名字冲突
import
优点:指名道姓跟某一个名称空间要名字,肯定不会与当前名称空间中的名字冲突
缺点:必须加上前缀
3、循环导入的问题


# print('正在导入m1') # # x='m1.py' # # from m2 import y # print('正在导入m1') def f1(): from m2 import y,f2 print(y) f2() x='m1.py'


# print('正在导入m2') # # y='m2' # # from m1.py import x print('正在导入m2') def f2(): from m1 import x print(x) y='m2.py'
### run.py # 1、创建m1.py的名称空间 # 2、执行m1.py的代码,将产生的名字丢到m1.py的名称空间中 # 3、在当前执行文件的名称空间中拿到一个名字m1 import m1 m1.f1()
4、模块的搜索路径
模块搜索路径优先级:
内存 --------> 内置的模块 --------> sys.path(环境变量)


#模块的查找顺序 1、在第一次导入某个模块时(比如spam),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用 ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看 2、如果没有,解释器则会查找同名的内建模块 3、如果还没有找到就从sys.path给出的目录列表中依次寻找spam.py文件。 #sys.path的初始化的值来自于: The directory containing the input script (or the current directory when no file is specified). PYTHONPATH (a list of directory names, with the same syntax as the shell variable PATH). The installation-dependent default. #需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错。 #在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。 1 >>> import sys 2 >>> sys.path.append('/a/b/c/d') 3 >>> sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索 注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理, #首先制作归档文件:zip module.zip foo.py bar.py import sys sys.path.append('module.zip') import foo,bar #也可以使用zip中目录结构的具体位置 sys.path.append('module.zip/lib/python') #windows下的路径不加r开头,会语法错误 sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a') #至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。 #需要强调的一点是:只能从.zip文件中导入.py,.pyc等文件。使用C编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降。
5、区分python文件的两种用途
一个python文件有两种用途:(模块与脚本)
1、可以执行运行:__name__ == '__main__'
2、可以被当做模块导入:__name__ == '模块名'
if __name__ == '__main__':
二、包的使用
1、什么是包
官网解释
Packages are a way of structuring Python’s module namespace by using “dotted module names”
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
具体的:包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来
需要强调的是:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块
2、为什么要用包
包的本质就是一个文件夹, 那么文件夹唯一的功能就是将文件组织起来 随着功能越写越多 ,我们无法将所以功能都放到一个文件中, 于是我们使用模块去组织功能, 而随着模块越来越多, 我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性。
ps:注意事项
#1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 #2、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件 #3、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
|---示例 | ||---dir1 #文件夹 | | |-----dir2 #文件夹 | | |---p1 #包文件夹 | | |||-------------p2 #包文件夹 | | ||| ||----- __init__.py | | ||| |------m3.py | | ||| | | |||--- __init__.py | | ||----m1.py | | |-----m2.py | | | |------run.py #执行文件


# run.py from dir1.dir2 import p1 p1.f1() p1.f2() p1.f3() #====================================== #dir1文件夹 (dir2文件夹) # #dir2文件夹(p1包文件夹) #====================================== #p1下的文件内容 #__init.py from .m1 import f1 from .m2 import f2 from .p2.m3 import f3 #------------------------------------------ #m1.py def f1(): print('m1.f1') #------------------------------------------- #m2.py def f2(): print('m2.f2') #------------------------------------------- #p1包文件夹(p2包文件夹) #======================================= #p2下的文件内容 #__init__.py #空 #-------------------------------------------- #m3.py def f3(): print('m3.f3')
#import p1 #1 创建p1的名称空间 #2 执行p1下的__init__.py文件的代码,将执行过程中产生的名字都丢到名称空间中 #3 在当前执行文件中拿到一个名字p1,p1指向__init__.py的名称空间
#包内模块的:绝对导入与相对导入 # 绝对导入:每次导入都是以最顶级包为起始开始查找的 # 相对导入:相对于当前所在的文件,.代表当前所在的文件,..代表上一级,... # 强调: # 相对导入只能在被导入的模块中使用 # 在执行文件里不能用.或者..的导入方式 #注意: # 但凡在导入时带点的,点的左边必须是一个包
三、软件开发的目录规范
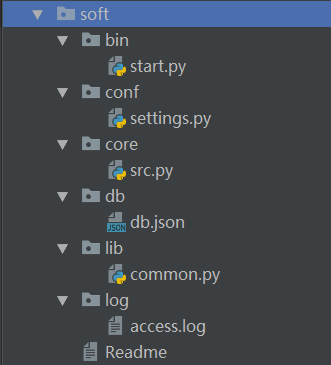
1、bin 文件夹 :一般放程序启动文件(start.py)
2、conf 文件夹:一些配置信息(例如路径等)
3、core 文件夹:程序的核心文件 与用户挂钩的
4、db 文件夹 :数据文件所在地
5、lib 文件夹 :公共模块文件(例如认证文件)
6、log 文件夹 :日志文件所在地
7、Readme 文件 :程序的帮助文档
四、常用模块之logging模块
一、日志的级别
CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 #不设置
二、默认级别为warning ,默认打印到终端
import logging logging.debug('调试debug') logging.info('消息info') logging.warning('警告warn') logging.error('错误error') logging.critical('严重critical') ''' WARNING:root:警告warn ERROR:root:错误error CRITICAL:root:严重critical '''
三、为logging 模块指定全局配置,针对所有logger有效,控制打印到文件
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有


filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger 的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 #格式 %(name)s:Logger的名字,并非用户名,详细查看 %(levelno)s:数字形式的日志级别 %(levelname)s:文本形式的日志级别 %(pathname)s:调用日志输出函数的模块的完整路径名,可能没有 %(filename)s:调用日志输出函数的模块的文件名 %(module)s:调用日志输出函数的模块名 %(funcName)s:调用日志输出函数的函数名 %(lineno)d:调用日志输出函数的语句所在的代码行 %(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d:线程ID。可能没有 %(threadName)s:线程名。可能没有 %(process)d:进程ID。可能没有 %(message)s:用户输出的消息


#========使用 import logging logging.basicConfig(filename='access.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('调试debug') logging.info('消息info') logging.warning('警告warn') logging.error('错误error') logging.critical('严重critical') #========结果 access.log内容: 2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug 2017-07-28 20:32:17 PM - root - INFO -test: 消息info 2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn 2017-07-28 20:32:17 PM - root - ERROR -test: 错误error 2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical part2: 可以为logging模块指定模块级的配置,即所有logger的配置
四、logging模块的Formatter ,Handler,Logger,Filte 对象
#logger:产生日志的对象 #Filter:过滤日志的对象 #Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 #Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式


''' critical=50 error =40 warning =30 info = 20 debug =10 ''' import logging #1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出 logger=logging.getLogger(__file__)#日志名 #2、Filter对象:不常用,略 #3、Handler对象:接收logger传来的日志,然后控制输出 h1=logging.FileHandler('t1.log') #打印到文件 h2=logging.FileHandler('t2.log') #打印到文件 h3=logging.StreamHandler() #打印到终端 #4、Formatter对象:日志格式 formmater1=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p',) formmater2=logging.Formatter('%(asctime)s : %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p',) formmater3=logging.Formatter('%(name)s %(message)s',) #5、为Handler对象绑定格式 h1.setFormatter(formmater1) h2.setFormatter(formmater2) h3.setFormatter(formmater3) #6、将Handler添加给logger并设置日志级别 logger.addHandler(h1) logger.addHandler(h2) logger.addHandler(h3) logger.setLevel(10) #7、测试 logger.debug('debug') logger.info('info') logger.warning('warning') logger.error('error') logger.critical('critical')
详细步骤:
1、配图
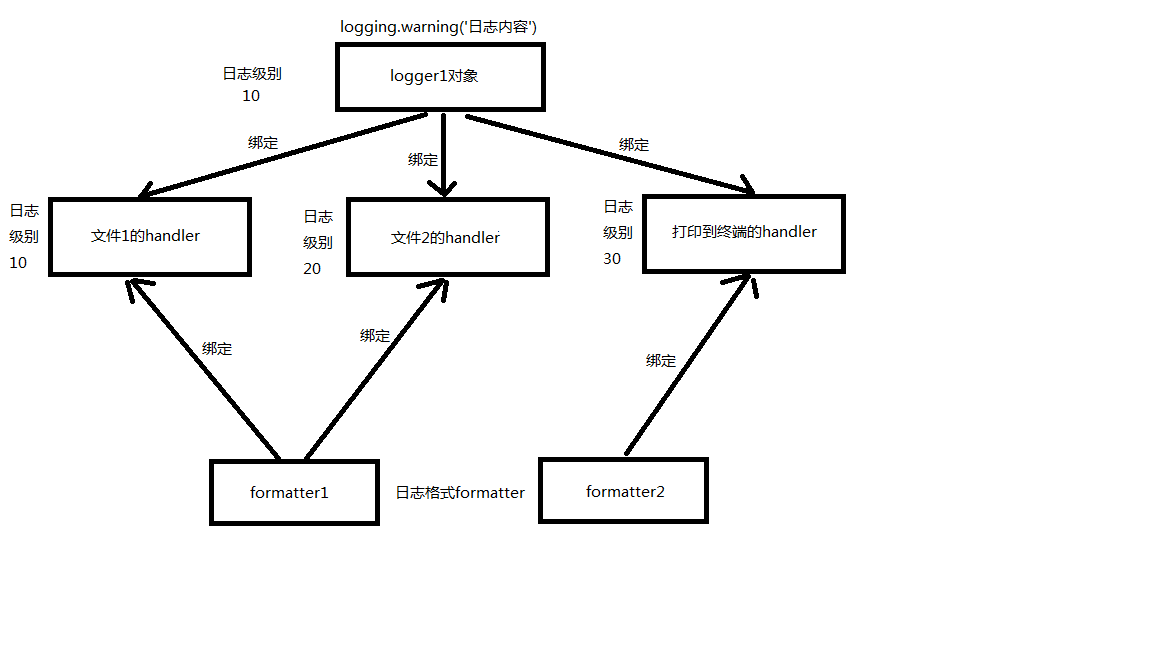
1、logger对象负责产生日志
logger1=logging.getLogger('xx日志')
2、filter过滤(基本用不到)
3、handler对象需要与logger对象绑定,用来接收logger对象传过来的日志,控制打印到不同的地方(文件、终端)
fh1=logging.FileHandler(filename='a1.log',encoding='utf-8') fh2=logging.FileHandler(filename='a2.log',encoding='utf-8') sh=logging.StreamHandler()# 往终端打印的
4、formmater对象需要与handler对象绑定,用于控制handler对象的日志格式


formmater1=logging.Formatter( fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p' ) #两种不同的日志格式 formmater2=logging.Formatter( fmt='%(asctime)s - %(levelname)s : %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p' )
ps1:设置日志级别(统一设置):logger与handler两层关卡都放行,日志最终才放行
logger1.setLevel(10) #logger对象设置 fh1.setLevel(10) #文件1的handler设置级别 fh2.setLevel(20) #文件2的handler设置级别 sh.setLevel(30) #打印到终端的handler设置级别
ps2:建立logger对象与handler对象的绑定关系
logger1.addHandler(fh1)
logger1.addHandler(fh2)
logger1.addHandler(sh)
ps3:建立handler对象与formmater对象的绑定关系
fh1.setFormatter(formmater1)
fh2.setFormatter(formmater1)
sh.setFormatter(formmater2)
最终:使用logger1对象产生日志,打印到不同的位置
logger1.debug('蘑菇买彩票中奖30元') logger1.warning('蘑菇花了1000元买彩票')
五、Logger与Handler的级别