目录
1. URL的组成
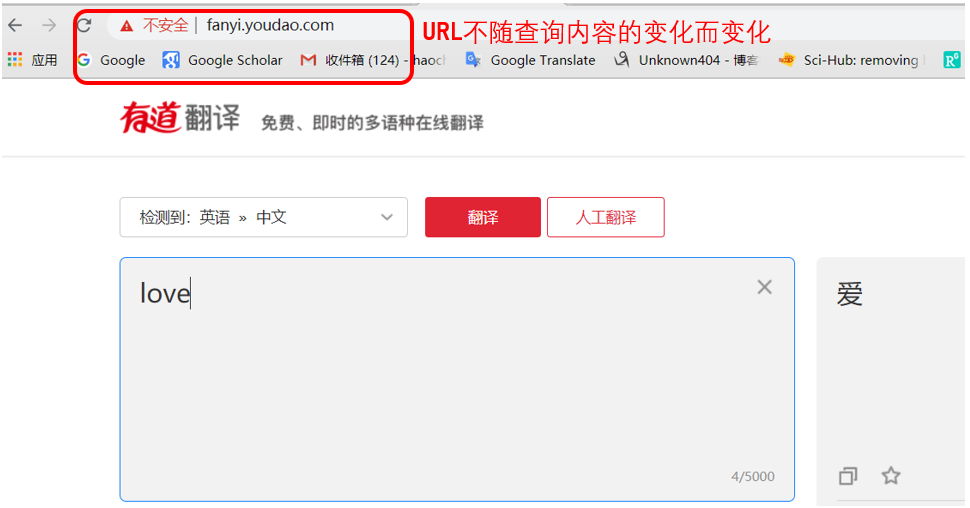
汉字通过URL encode(UTF-8)编码出来的编码,里面的字符全是打字节
如果你复制粘贴下来这个网址,出来的不是汉字,而是编码后的字节
https://www.baidu.com/s?wd=%E7%BC%96%E7%A8%8B%E5%90%A7
我们也可以在python中做转换-urllib.parse.urlencode
import urllib.parse.urlencode
url = "http://www.baidu.com/s?"
wd = {"wd": "编程吧"}
out = urllib.parse.urlencode(wd)
print(out)结果是: wd=%E7%BC%96%E7%A8%8B%E5%90%A7
2. 贴吧爬虫
2.1. 只爬贴吧第一页
import urllib.parse
import urllib.request
url = "http://www.baidu.com/s?"
keyword = input("Please input query: ")
wd = {"wd": keyword}
wd = urllib.parse.urlencode(wd)
fullurl = url + "?" + wd
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
request = urllib.request.Request(fullurl, headers = headers)
response = urllib.request.urlopen(request)
html = response.read()
print(html)2.2. 爬取所有贴吧的页面
对于一个贴吧(编程吧)爬虫,可以翻页,我们可以总结规律
page 1: http://tieba.baidu.com/f?kw=%E7%BC%96%E7%A8%8B&ie=utf-8&pn=0
page 2: http://tieba.baidu.com/f?kw=%E7%BC%96%E7%A8%8B&ie=utf-8&pn=50
page 3: http://tieba.baidu.com/f?kw=%E7%BC%96%E7%A8%8B&ie=utf-8&pn=100import urllib.request
import urllib.parse
def loadPage(url,filename):
"""
作用: url发送请求
url:地址
filename: 处理的文件名
"""
print("正在下载", filename)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read()
return html
def writePage(html,filename):
"""
作用:将html内容写入到本地
html:服务器响应文件内容
"""
print("正在保存",filename)
with open(filename, "wb") as f:
f.write(html)
print("-"*30)
def tiebaSpider(url, beginPage, endPage):
"""
作用:贴吧爬虫调度器,复制组合处理每个页面的url
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
fullurl = url + "&pn=" + str(pn)
html = loadPage(fullurl,filename)
writePage(html,filename)
if __name__ == "__main__":
kw = input("Please input query: ")
beginPage = int(input("Start page: "))
endPage = int(input("End page: "))
url = "http://tieba.baidu.com/f?"
key = urllib.parse.urlencode({"kw":kw})
fullurl = url + key
tiebaSpider(fullurl, beginPage, endPage)结果是:
Please input query: 编程吧
Start page: 1
End page: 5
正在下载 第1页.html
正在保存 第1页.html
------------------------------
正在下载 第2页.html
正在保存 第2页.html
------------------------------
正在下载 第3页.html
正在保存 第3页.html
------------------------------
正在下载 第4页.html
正在保存 第4页.html
------------------------------
正在下载 第5页.html
正在保存 第5页.html
------------------------------3. GET和POST的区别
- GET: 请求的url会附带查询参数
- POST: 请求的url不会
3.1. GET请求
对于GET请求:查询参数在QueryString里保存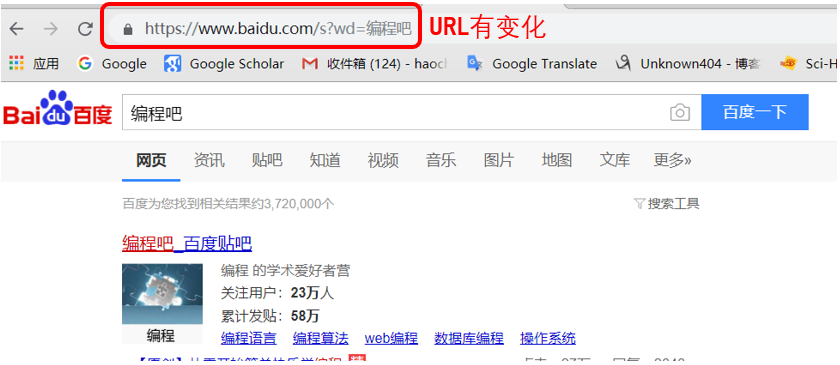

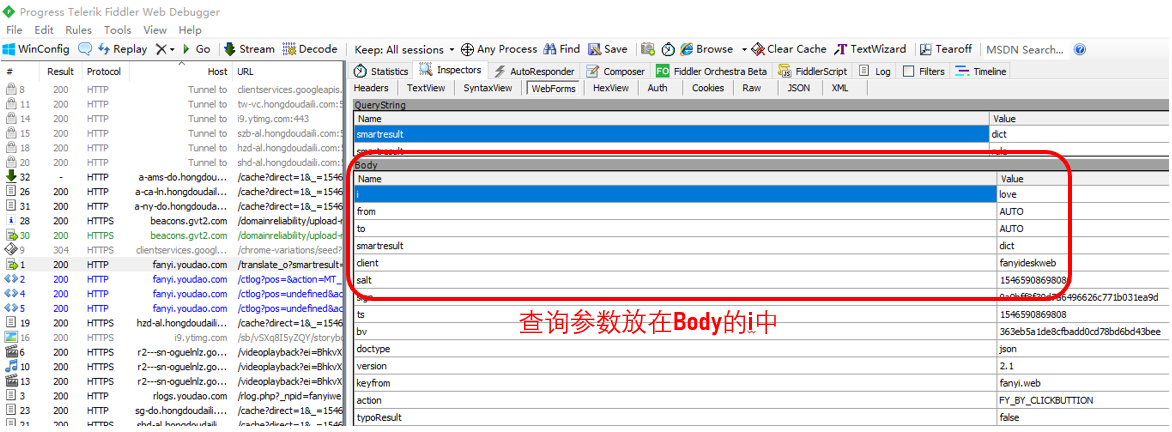
3.3. POST请求
对于POST请求: 茶韵参数在WebForm里面