1:创建爬虫文件,获取url地址
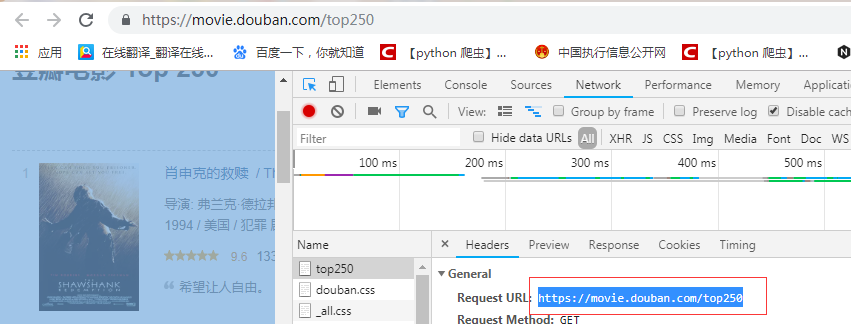
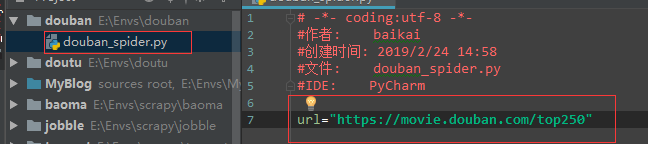
2:使用request获取第一页的请求信息
# -*- coding:utf-8 -*- #作者: baikai #创建时间: 2019/2/24 14:58 #文件: douban_spider.py #IDE: PyCharm import requests from bs4 import BeautifulSoup url="https://movie.douban.com/top250" wb_data=requests.get(url) # 获取网页文本信息 soup=BeautifulSoup(wb_data.text,'lxml') # 从soup中提取我们想要的信息 titles=soup.select('div.hd>a') rates=soup.select('span.rating_num') imgs=soup.select('img[width="100"]') for title,rate,img in zip(titles,rates,imgs): data={ 'title':list(title.stripped_strings), 'rate':rate.get_text(), 'img':img.get('src') } print(data)
3:获取多页的请求信息
# -*- coding:utf-8 -*- #作者: baikai #创建时间: 2019/2/24 14:58 #文件: douban_spider.py #IDE: PyCharm import requests from bs4 import BeautifulSoup urls=['https://movie.douban.com/top250?start=n&filter=' for n in range(0,250,25)] for url in urls: wb_data=requests.get(url) # 获取网页文本信息 soup=BeautifulSoup(wb_data.text,'lxml') # 从soup中提取我们想要的信息 titles=soup.select('div.hd>a') rates=soup.select('span.rating_num') imgs=soup.select('img[width="100"]') for title,rate,img in zip(titles,rates,imgs): data={ 'title':list(title.stripped_strings), 'rate':rate.get_text(), 'img':img.get('src') } print(data)