准备工作
-
新建项目-新建PythonFile
-
安装爬虫模块

1pip install requests -
requests的常用函数
- request.get(),对应http协议的get请求,也就是把网页下载下来。
- request.post(),对应Http协议的post请求,就是把数据上传到网页服务器。
-
观察boss直聘的url。
1https://www.zhipin.com/c101250100-p110101/- 通过观察发现,后面应该是城市代码和职位代码
- 通过检查-network发现,城市代码应该是储存在city.json里面
- 职位代码应该是储存在position.json里面


通过观察:city.json的url为
1
|
https://www.zhipin.com/wapi/zpCommon/data/city.json
|
postion.json的url为
1
|
https://www.zhipin.com/wapi/zpCommon/data/position.json
|

爬取城市代码
-
测试连接
1
2
3
4
5import requests
# requests-->请求
url = 'https://www.zhipin.com/wapi/zpCommon/data/city.json' # boss直聘城市链接
response = requests.get(url)
print(response) # 打印响应返回值:
1<Response [200]>200:代表返回成功
404:网络连接失败
500:服务器奔溃
-
加入浏览器伪装头’user-agent’,防止被服务器发现你是爬虫
1headers = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'} -
第一次打印
1
2
3
4
5
6
7
8import requests
from pprint import pprint
url = 'https://www.zhipin.com/wapi/zpCommon/data/city.json' # boss直聘城市代码
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
response = requests.get(url, headers=headers)
data = response.json() # 从返回对象中提取json
pprint(data)结果如下:
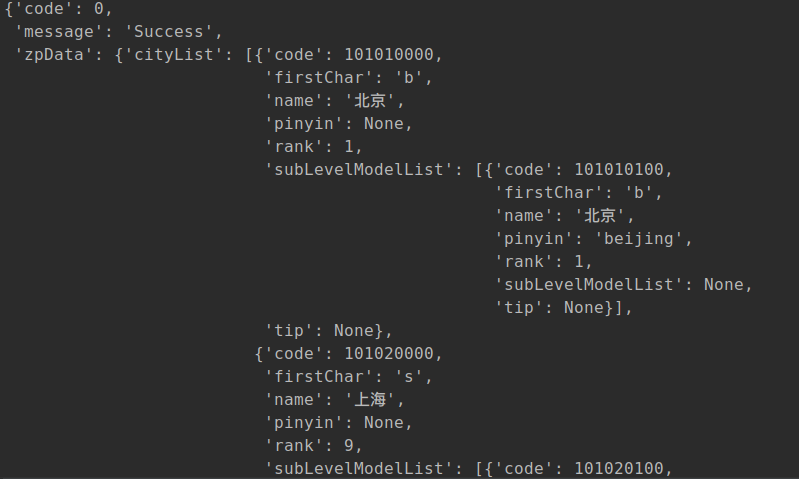
根据上图观察,返回的json可以当成是一个多层字典。

数据均在zpData\cityList下,于是对zpData进行第一次解包。

对cityList进行第二次解包。
1
|
import requests
|

省和城市代码就爬取完毕了,直接粘贴到excel就可以。至于如何直接导出excel,后面再说。