前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Jonsson
喜欢的朋友欢迎关注小编,除了分享技术文章之外还有很多福利,私信“资料”可以领取包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
代码如下:
import os from lxml import etree import requests # 设置头部信息,防止被检测出是爬虫 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' } url = "https://music.163.com/discover/toplist?id=3778678" base_url = 'http://music.163.com/song/media/outer/url?id=' # 新建一个字典用于存储最终所需要的数据 d = dict() re = requests.get(url=url, headers=headers).text # 构造了一个XPath解析对象并对HTML文本进行自动修正 html = etree.HTML(re) # XPath使用路径表达式来选取 x = html.xpath('//a[contains(@href,"/song?")]') # 对取到的数据进行筛选 for data in x: # 获取到音乐url href = data.xpath('./@href')[0] id = href.split("=")[1] href = base_url + "%s.mp3" % id # 添加到字典 if "$" not in id: # 获得到标签内的文本(即音乐的名称) name = data.xpath('./text()')[0] d[href] = name for i in d: # 文件夹不存在,则创建文件夹 save_path = './music' folder = os.path.exists(save_path) if not folder: os.makedirs(save_path) # 下载音乐到当前目录的music文件夹下 get = requests.get(base_url + '%s.mp3' % i, headers=headers).content with open('./music/%s.mp3' % d[i], "wb") as f: print("正在下载歌曲 《%s》 ..." % d[i]) f.write(get)
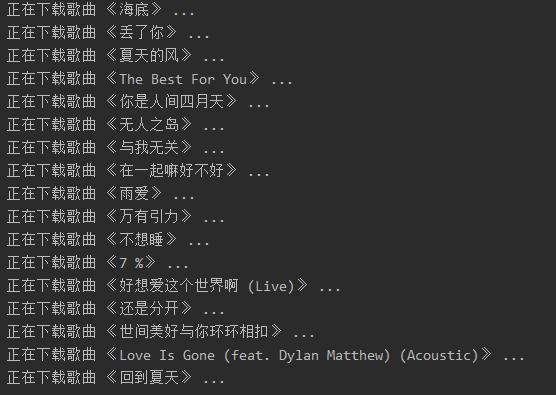
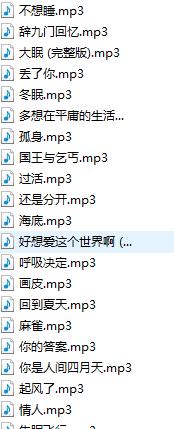
效果如下: