首先说一下这个有啥用?要说有用也没啥用,要说没用吧,既然能拿到这些数据,拿来做数据分析。能有效的得到职位信息,薪资信息等。也能为找工作更加简单吧,且能够比较有选择性的相匹配的职位及公司
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
本章节源码仓库为:https://github.com/Mr2753/PythonScrape
一言不合直接上代码!具体教程及思路总代码后!
所用解释器为Python3.7.1,编辑器为Pycharm 2018.3.5.
本着虚心求学,孜孜不倦,逼逼赖赖来这里虚心求学,孜孜不倦,逼逼赖赖,不喜勿喷,嘴下手下脚下都请留情。
本节所涉:Request基本使用、Request高级使用-会话维持、Cookies、Ajax、JSON数据格式
Request更多详情请参考Request官方文档:
Cookie:有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息
具体Cookies详情请参考:https://baike.baidu.com/item/cookie/1119?fr=aladdin
首先介绍一下关于本章代码的基本思路:
四步走(发起请求、得到响应、解析响应得到数据、保存数据)
四步中准确来说是三步,(发起请求,得到响应、解析响应,提取数据、保存数据)
-
请求网页(在搜索框中输入所查询的岗位<例如:Python>,得到BASE_URL,)
- BASE_URL:https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=
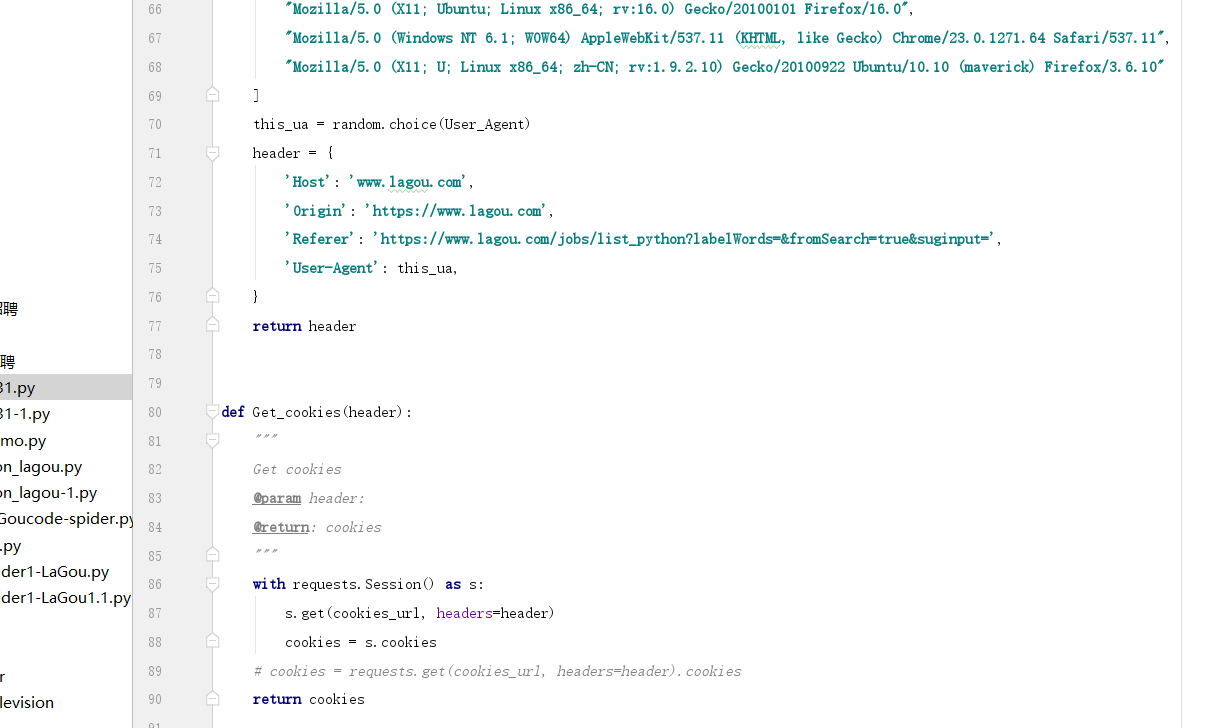
- 加入请求头(注意加Cookies),请求BASE_URL
- 观察响应信息以及本网页源码观察浏览器网页源码,对比发现其中并没有我们所需要的信息:发现Ajax的痕迹。

- 经过一系列操作发现Ajax网页地址(在这里直接请求此链接并不能访问):
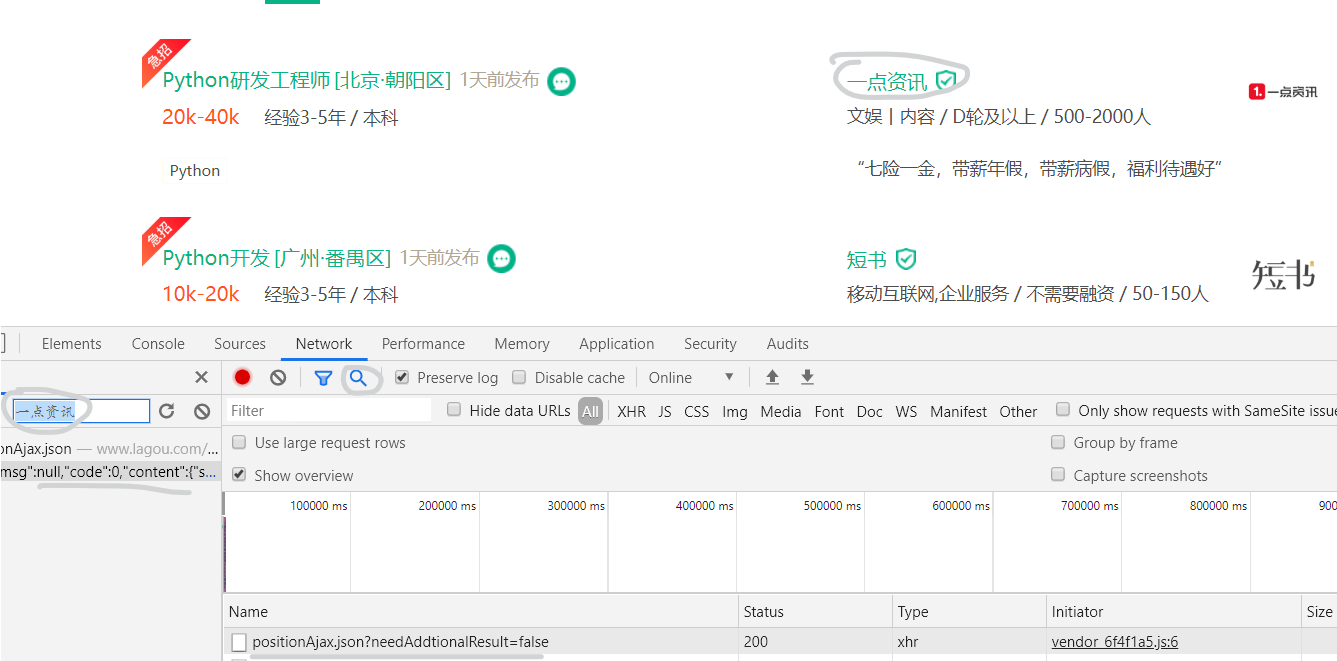
- 多次请求过后,发现错误。错误的缘由是由于Cookies限制,并且网页以动态检测,且时间间隔小。
- 经过前言的学习,已经学会了。会话维持。动态得到Cookies,这样不就可以把这个“反爬”彻底绕过了呢?答案肯定是滴
- 哪让我们做一下会话维持,并动态提取Cookies吧。
- 易混淆点:cookies的维持为什么是维持BASE_URL的而不是Ajax_URL?下面按照个人理解对于本Ajax给出以下解释:结合Ajax原理可知,Ajax其基本原理就是在网页中插入异步触发的。说到底他还是在这个页面,并没有转到其他页面。只是需要特定条件触发即可插入本网页
-
1234567891011def Get_cookies(header):"""Get cookies@param header:@return: cookies"""with requests.Session() as s:s.get(cookies_url, headers=header)cookies = s.cookies# cookies = requests.get(cookies_url, headers=header).cookiesreturn cookies
-
- 万事俱备、只欠东风:请求Ajax_URL 即可得到以下
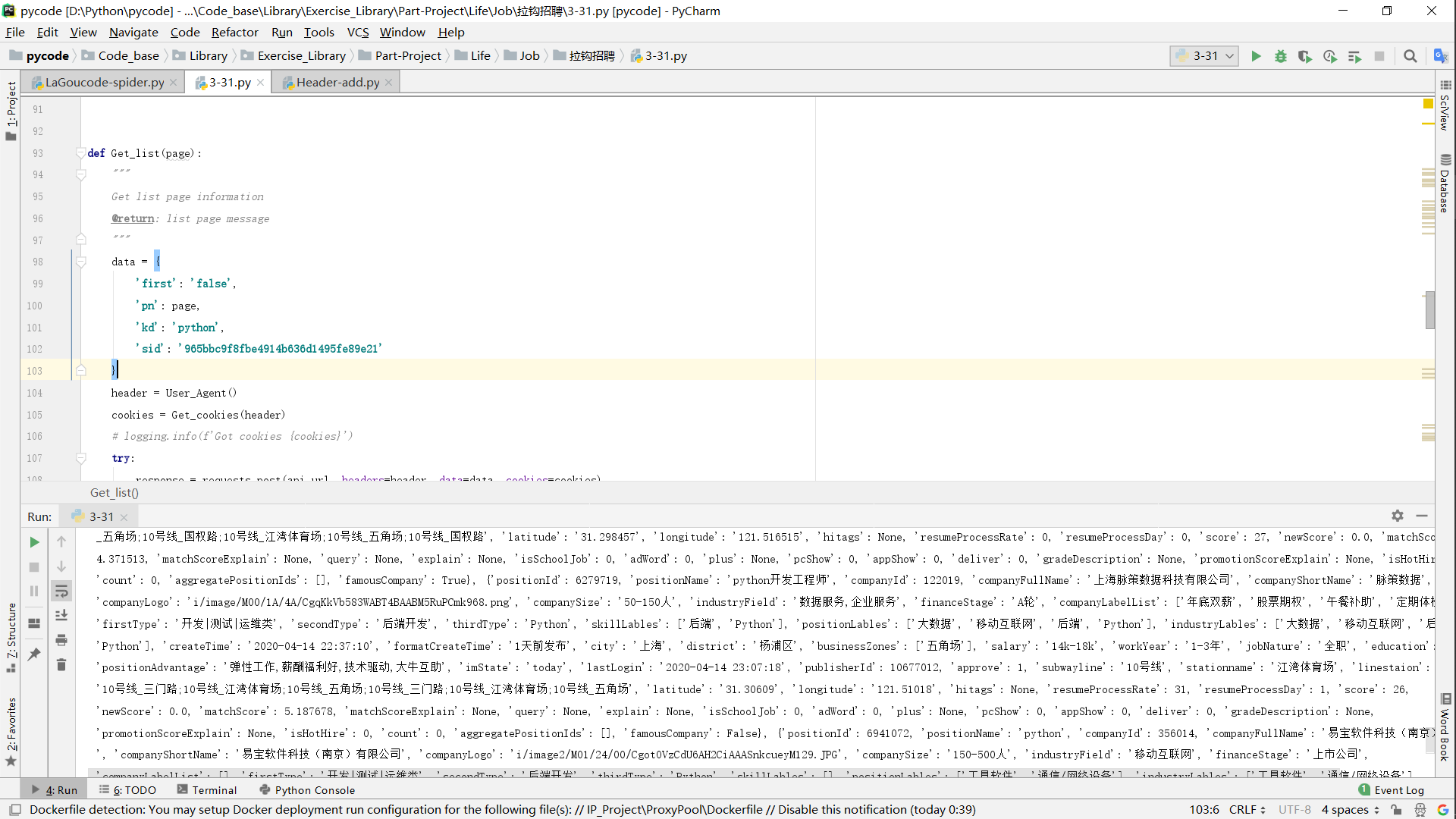
- 得到响应:经过以上操作已经请求完成了。并能够保障请求稳定性。(当然在此并没有做异常捕获,如果加上,将会更稳)
-
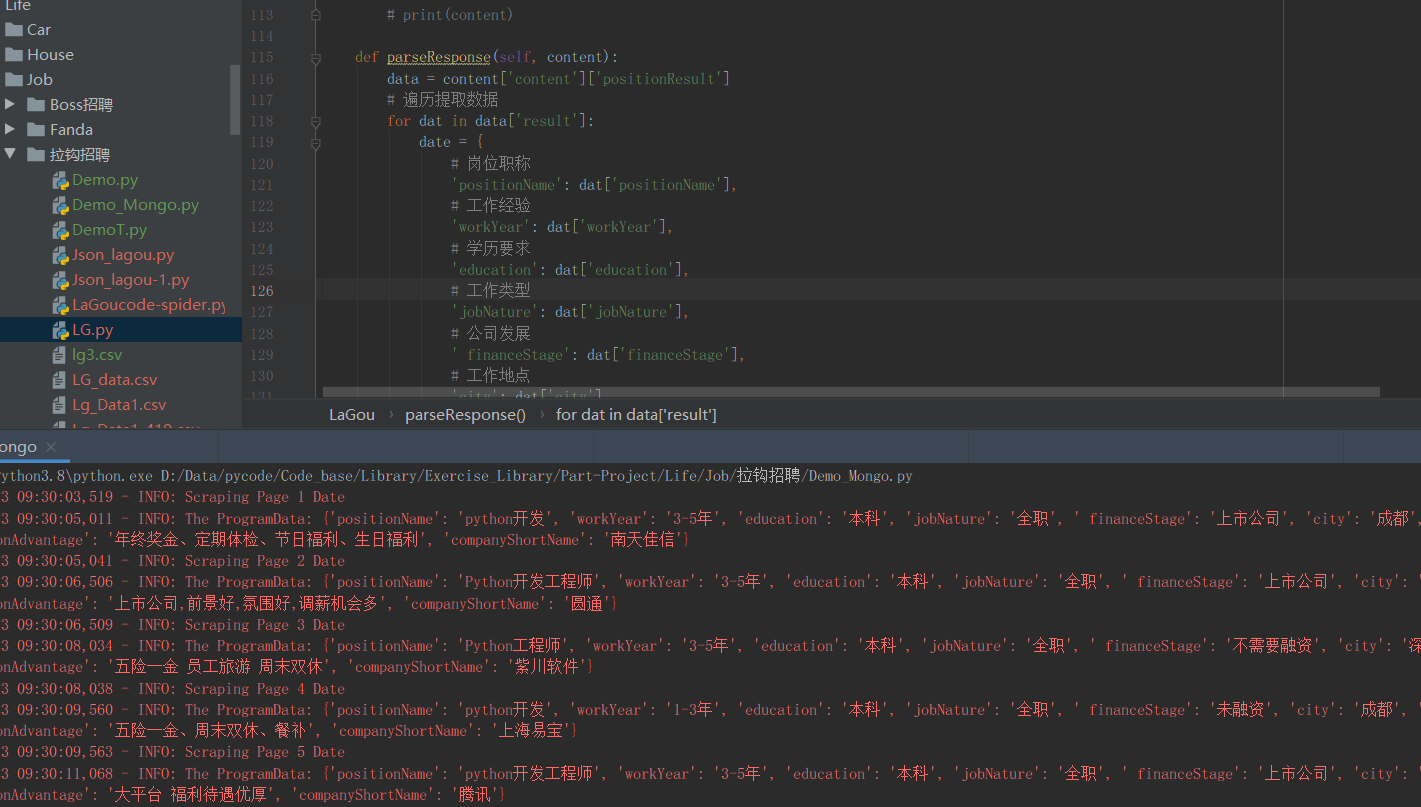
解析响应:如果上述步骤没有错的话,到此已经能得到网页数据了(如上图):
-
- 我用的提取代码如下 :123456789101112131415161718192021222324252627def parse(message):industryField = message['industryField']# company_messagepositionName = message['positionName']companyFullName = message['companyFullName']companySize = message['companySize']financeStage = message['financeStage']# companyLabelList = message['companyLabelList']companyLabelList = '|'.join(message['companyLabelList'])Type = "|".join([message['firstType'], message['secondType'], message['thirdType']])Address = ''.join([message['city'], message['district'], ])salary = message['salary']positionAdvantage = message['positionAdvantage']# limitation factorworkYear = message['workYear']jobNature = message['jobNature']education = message['education']items = f"{positionName}, {companyFullName}, {companySize}, {financeStage}, {companyLabelList}, {industryField}, " \f"{Type}, {salary}, {jobNature}, {education}"# items = "".join(str(# [positionName, companyFullName, companySize, financeStage, companyLabelList, industryField, Type, salary,# jobNature, education]))if items:# print(items)logging.info(items)# return items.replace('[', '').replace(']', '')return items.replace('(', '').replace(')', '')
- 此时只需提取相关数据,即可。得到:
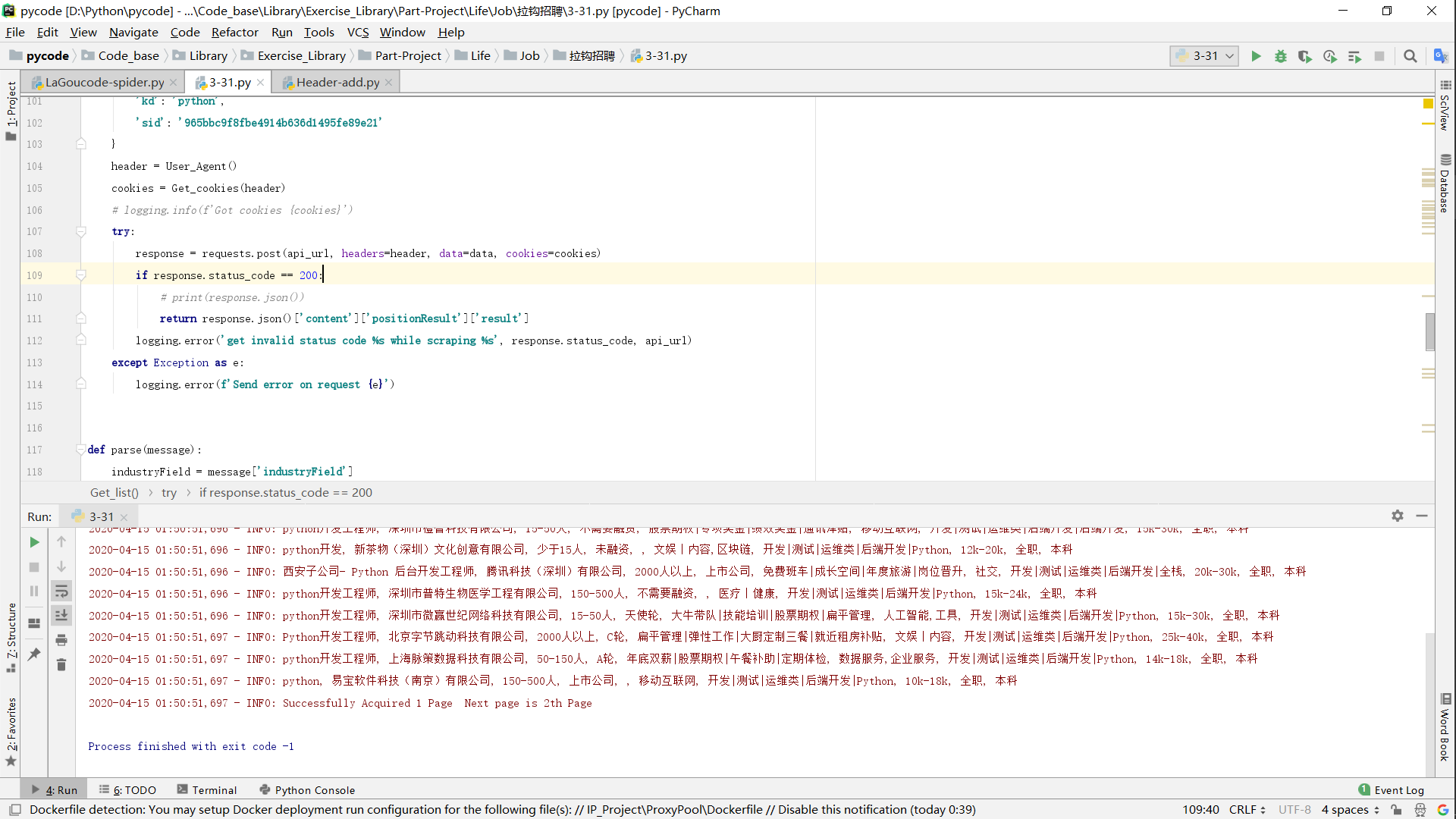
- 我用的提取代码如下 :
-
保存数据:
-
常规保存:(保存到本地)
-
|
1
2
3
4
|
def save_message(item):
with open('lg3.csv', 'a+', encoding='gbk') as f:
f.write(item + '\n')
thread_lock.release()
|
-
数据入库:(保存到数据库)
-
本源码地址:https://github.com/Mr2753/PythonSpider/blob/master/%E8%81%8C%E4%BD%8D%E6%8B%9B%E8%81%98/Demo_Mongo.py
在这里我选择的为Mongo,接下来,那咱们操作一下吧。Mongo的安装便不在此处赘述。与mongo相关的文章,在这里比较推荐才哥和东哥的几篇文章(以本文来看,比较建议看看这几篇文章。并没说其他不好啊,不,我没有,我没说哦),地址如下:
前方高能预警,造!!!:(此时的你已安装了Mongo,并能正常使用mongo。剩下的交给我,我教你好了)
-
安装pymongo
1pip install pymongo -
建立连接:在原有的代码基础上改写,添加类似于如下的代码:
1234567MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'# MONGO_DB_NAME = 'Jobs'# MONGO_COLLECTION_NAME = 'Jobs'client = pymongo.MongoClient(MONGO_CONNECTION_STRING)db = client['Jobs']collection = db['Jobs']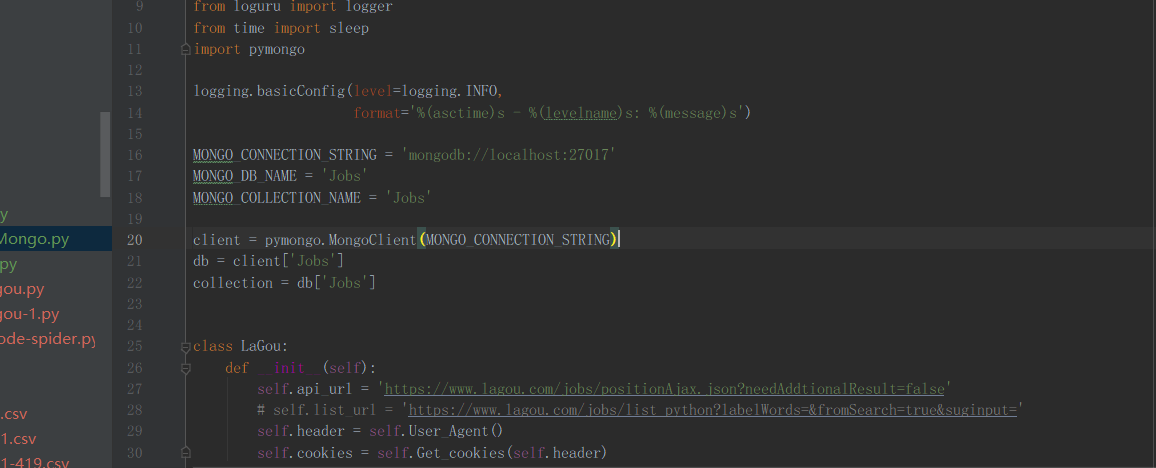
-
新增存储方法:
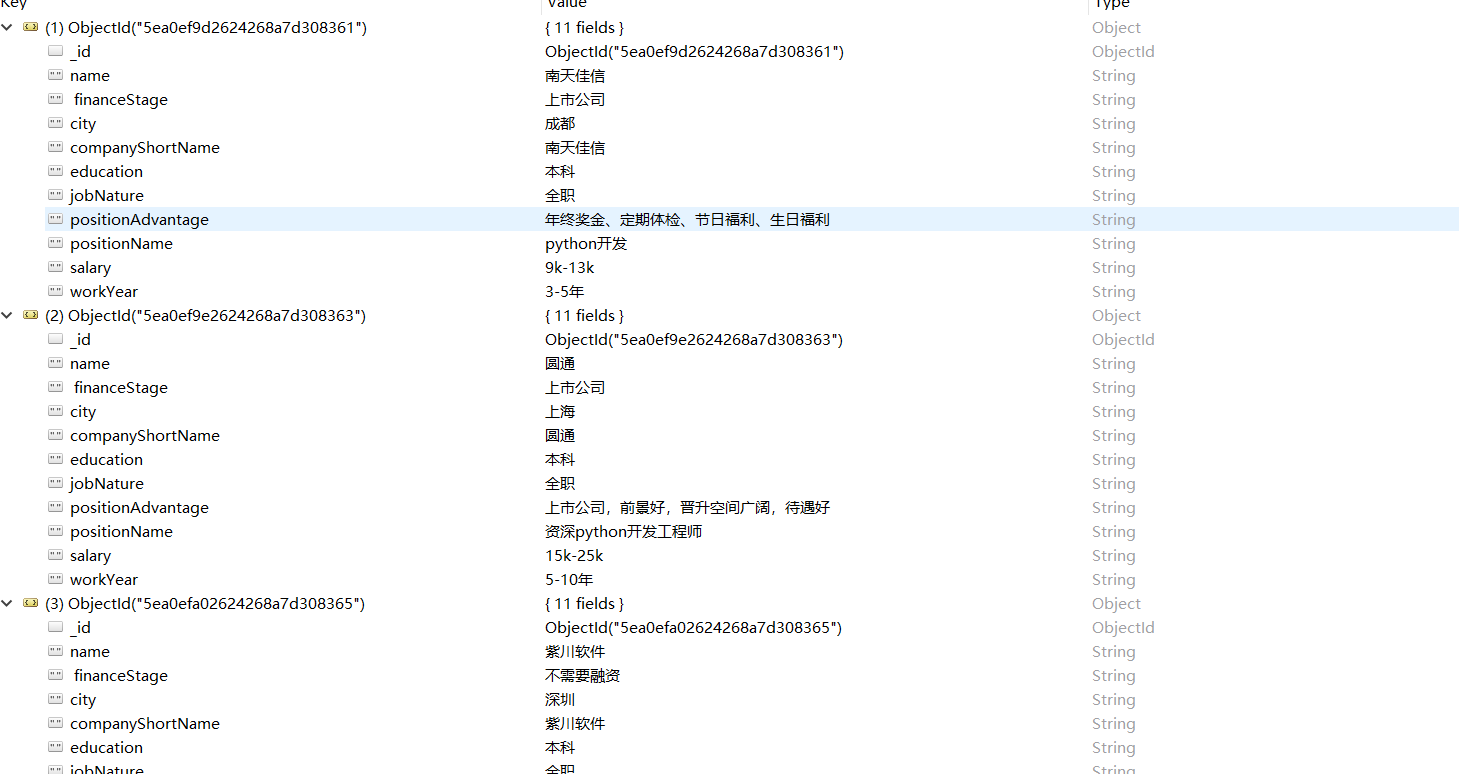
1234567891011def save_data(self, date):"""save to mongodb:param date::return:"""collection.update_one({'name': date.get('companyShortName')}, {'$set': date}, upsert=True)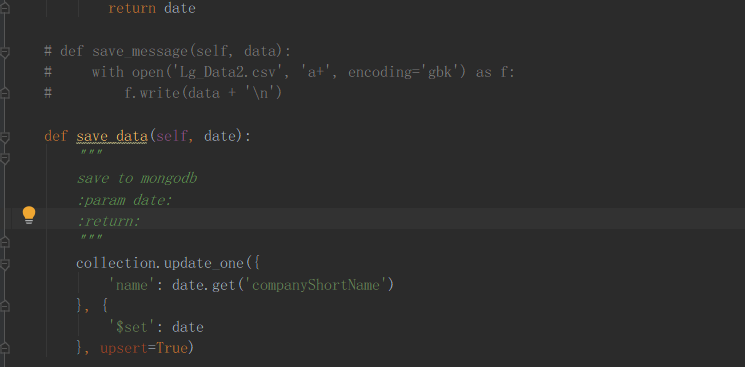
-
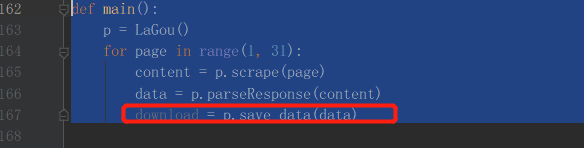
调用此方法:
123456def main():p = LaGou()for page in range(1, 31):content = p.scrape(page)data = p.parseResponse(content)download = p.save_data(data)
注意:由于mongo的存储格式为key :value形式,所以咱们提取到的数据返回也必须是key :value形式:
看我看我,怎么搞的,我是这样搞的: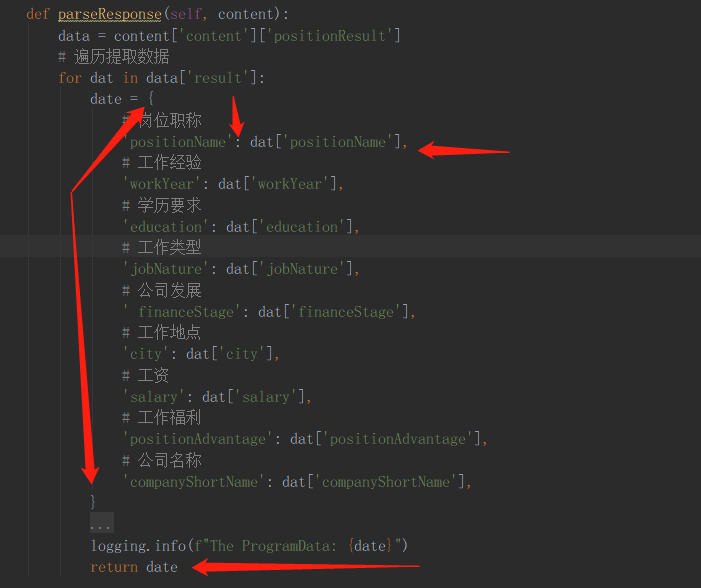
左手叉腰,右手摇,Over!