前言
最近刚学了python的爬虫,刚好可以用来爬取漂亮的图片作为壁纸,网上美图网站有很多,比如:花瓣,堆糖。它们请求图片数据的方式差不多类似,都是通过用户不断下滑加载新的图片,这种请求技术就叫做Ajax,全称为 Asynchronous JavaScript and XML,即异步加载数据、资源。
PS:如有需要Python学习资料的小伙伴可以加下方的群去找免费管理员领取

可以免费领取源码、项目实战视频、PDF文件等
所以今天就来写个简答的python小爬虫来练练手,抓取堆糖上的图片。
打开堆糖网站
https://www.duitang.com
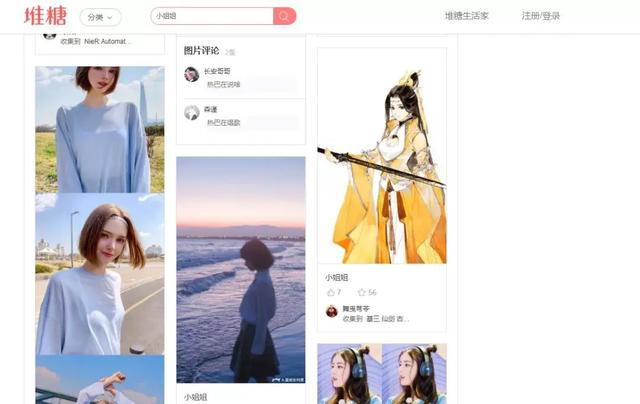
接着在输入框输入咱们感兴趣的内容,进行搜索,咱们的目标就是将搜索结果里的图片爬取到本地硬盘上。
废话不说,立即写个代码来跑一跑。不过在写代码前,咱们还是得先分析一下抓取数据的步骤。
首先,可以查看上浏览器上的地址栏,可以看出这个搜索结果的网址构成还是挺有规律的,前面是堆糖的首页网址,?后面是咱们的请求数据,请求数据里面最关键的就是(kw="搜索关键词"),这是会根据咱们搜索内容不同而改变的。

接着按键盘上的f12调出开发者工具,点击Network,再按f5刷新下网页进行数据重新请求,可以看到在Name的下拉框下有许多的请求文件,咱们可以点击一个文件进行查看下里面请求头数据,这是待会写爬虫非常重要的请求头构造数据来源。
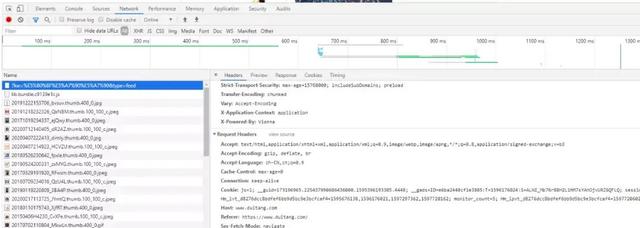
由于网站是通过异步加载数据的方式来获取图片的,所以咱们要找到网站请求的json数据,关注到上边的资源过滤器,当前选择的是All,即所有的资源文件。但是这么多的资源文件不是咱们都需要的,咱们只关注的是json数据,所以点击上面的XHR可以看到里面是空白的,这时你可能会疑惑,咱们要的数据在哪呢?别急,前面说到网页数据是异步加载的,所以咱们只要不断向下滚动鼠标来加载新的图片,这时就会发现Name下拉框下多了很多资源文件,随便选择一个进行查看,将鼠标停留在资源文件上时,会浮出一个url地址。咱们分析下这个url地址,这和前面的url地址有点像,但是复杂了很多。

看不出规律可以单击下资源文件,右边窗口的Request URL行也有这个url,咱们多点击几个文件进行查看,并将里面url地址复制到文本上查看。
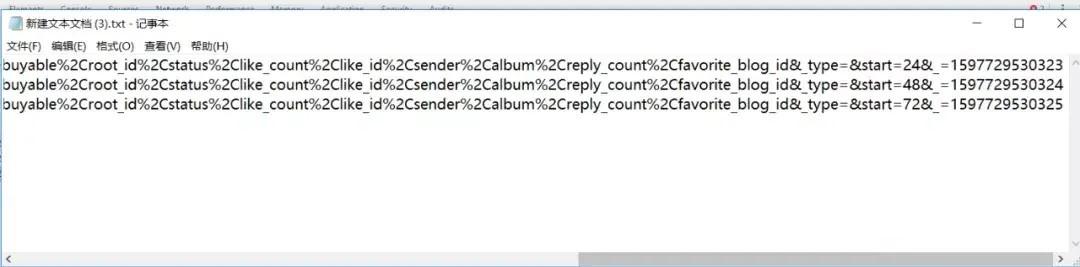
可以看出这些url前面是都是相同的,唯一不同的是后面start和_不同。咱们待会写代码时就构造这个url。
双击可以打开这个url地址,里面会是大段的json数据,里面就有咱们要爬的的数据,不过密集恐惧症患者看后表示有点头晕。当然还有另一个地方可以查看这些数据。

单击一个资源文件,再点击右边Preview,可以看到这里面有许多数据,而咱们要的数据就是前面的json数据,黑色三角形是可以点击的,点击后会展开详细的数据信息。
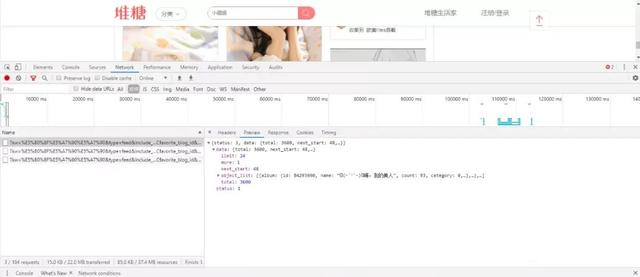
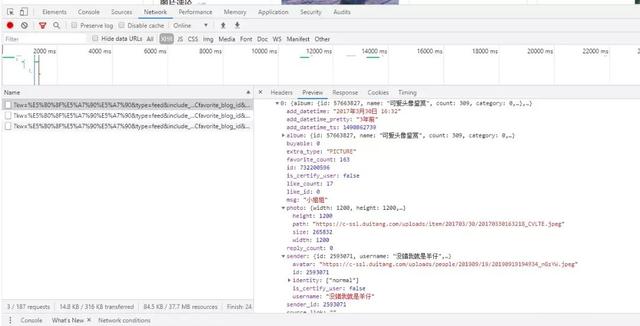
通过查看分析,这里photo下面的path行应该就是咱们的图片的url地址,也就是说只要将这个地址拿到,就可以进行图片的爬取。
分析到这里,就可以来写咱们的代码,打开pycharm,先导入必要的库。
from urllib.parse import urlencode
import requests
import time
import os
接着构造咱们的请求头和每一页的url。
base_url='https://www.duitang.com/napi/blog/list/by_search/?'
headers = {
'Host':'www.duitang.com',
'Referer':'https://www.duitang.com/search/?kw=%e7%be%8e%e5%a5%b3&type=feed',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}def get_page(start,count):
params={
'kw':'小姐姐',
'type':'feed',
'include_fields':'top_comments,is_root,source_link,item,buyable,root_id,status,like_count,like_id,sender,album,reply_count,favorite_blog_id',
'_type':'',
'start':start,
'_':count
}
url = base_url + urlencode(params)
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.json()
else:
print("error")
except requests.ConnectionError as e:
print('Error',e.args)
获取到图片url就可以进行读写操作了。
def parse_page(json):
if json:
items = json.get('data').get('object_list')
for item in items:
data = {}
data['favorite_count'] = item.get('favorite_count');
item = item.get('photo')
data['path']=item.get('path'); ## 获取图片url地址
file_path = '{0}/{1}'.format('./'+download_dir, data['path'].split('/')[-1]) ## 将图片写入到本地硬盘上
with open(file_path, 'wb') as f:
img = requests.get(data['path'])
print(img)
f.write(img.content)
yield data再写个主函数,完成
start_page = 0 ## 从第几页开始爬
page_size = 5 ## 要爬多少页
count = 1597729530322 ## 第1页请求数据中下划线的取值
download_dir = "downlode_img" ## 存放图片文件夹名称
if __name__ == '__main__':
count = 1597729530322 + start_page;
if not os.path.exists('./' + download_dir) :
os.mkdir('./' + download_dir); ## 创建文件夹
for start in range(start_page,page_size*24+1,24):
json = get_page(start,count)
results = parse_page(json)
for result in results:
print(result)
count += 1;
time.sleep(2) ## 每爬完一页暂停2秒,减轻服务器压力
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:it新猿