RFM模型
RFM模型是衡量客户价值和客户创利能力的重要工具和手段,是一种探索性数据分析方法。在众多的客户关系管理(CRM)的分析模式中,RFM模型是最被广泛提及的。该模型通过3项指标来描述该客户的价值状况。根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有三个神奇的要素,这三个要素构成了数据分析最好的指标:
- 最近一次消费(Recency):表示用户最近一次消费距离现在的时间。消费时间越近的客户价值越大。1年前消费过的用户肯定没有1周前消费过的用户价值大。
- 消费频率(Frequency) :消费频率是指用户在统计周期内购买商品的次数,经常购买的用户也就是熟客,价值肯定比偶尔来一次的客户价值大。
- 消费金额(Monetary):消费金额是指用户在统计周期内消费的总金额,体现了消费者为企业创造利润的多少,自然是消费越多的用户价值越大。
企业在推行CRM时,就要根据RFM模型的原理,了解客户差异,并以此分类进行企业流程重建,才能创新业绩与利润。
客户分类
基于这三个维度,将每个维度分为高低两种情况,我们构建出了一个三维的坐标系。分为8个客户类型维度切片。
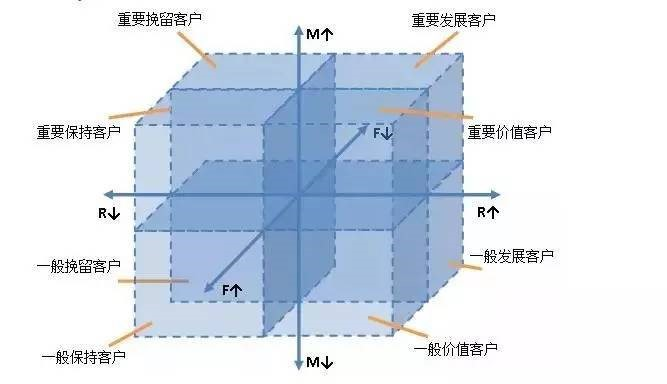
| 客户类型 | R(最近一次消费时间) | F(消费频率) | M(消费总金额) |
| 重要价值客户 | 高 | 高 | 高 |
| 重要发展客户 | 高 | 低 | 高 |
| 重要保持客户 | 低 | 高 | 高 |
| 重要挽留客户 | 低 | 低 | 高 |
| 一般价值客户 | 高 | 高 | 低 |
| 一般发展客户 | 高 | 低 | 低 |
| 一般保持客户 | 低 | 高 | 低 |
| 一般挽留客户 | 低 | 低 | 低 |
客户价值分析
RFM评分:由于R值、F值、M值存在量级之间的差距,无法直观的通过加减或平均来衡量用户价值,根据三组数据各个值的特性,采用机器学习特征工程之数据分箱来衡量客户价值。
关于变量分箱主要分为两大类:有监督型和无监督型
对应的分箱方法:
A. 无监督:(1) 等宽 (2) 等频 (3) 聚类 K-Means
B. 有监督:(1) 卡方分箱法(ChiMerge) (2) ID3、C4.5、CART等单变量决策树算法 (3) 信用评分建模的IV最大化分箱 等
数据分析
1 import pandas as pd
2 import numpy as np
3
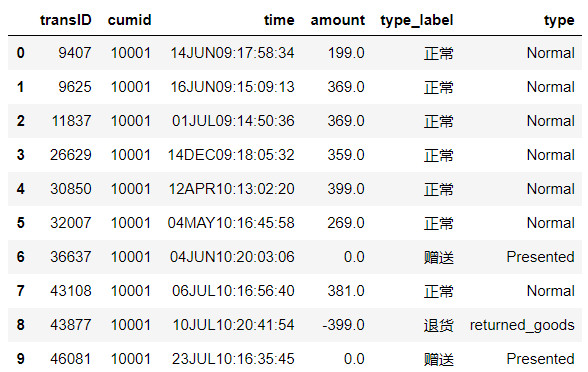
4 #1. 导入示例交易订单数据
5 df = pd.read_csv(r'D:\python_test\Data_Mining\data\RFM_TRAD_FLOW.csv', encoding='GBK')
6 df.head(10)
1 # 2.按照RFM方法进行数据处理
2
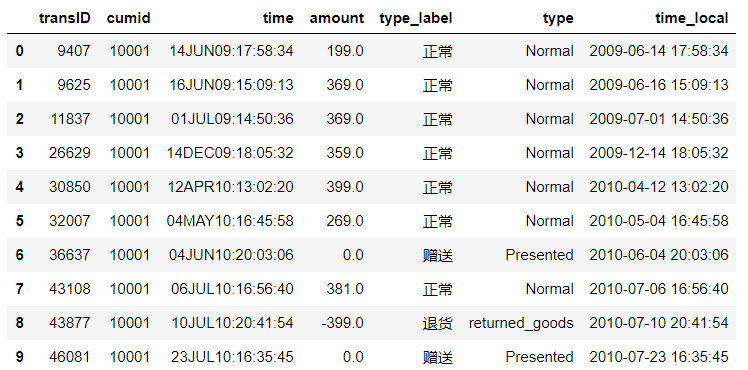
3 # time字段是英式日期时间标识法,转换成中国本地日期时间表示法以便于查看。
4 import time
5 df['time_local'] = pd.to_datetime(df['time'], errors='coerce', format='%d%b%y:%H:%M:%S')
6 df.head(10)
1 # 观察交易金额数据可以看到有0消费额,有负数消费额,继续查看交易类型,发现为“赠送”和“退货”所造成。
2 # 先查看一下数据的基本情况发现是26662行,6列的数据集。
3 df.describe
1 # 查看一下赠送和退货比例这些<=0占总数的比例是多少?如果很少就删除。查看后发现占消费比例竟然达到了33.97 %。
2 # 许多网上分析认为这些是无效数据。但是我个人认为这些类型其实也是消费真实情况的一部分,尽量不要篡改数据是数据分析的基本原则。因此我还是保留了这部分数据纳入分析体系。
3 a = 1-df['transID'][df.amount>0].count()/df['transID'].count()
4 print('赠送和退货比例占总数的{0:^6.2f}%'.format(a*100))

1 # 查看数据中是否存在Na等缺失值,如果有fillna(0)填充。 2 # 结果发现数据完好并不存在缺失值 3 df.isna().any()

数据处理
1 # 将时间字符串转换成时间戳 2 # pandas 用 Timestamp 表示时点数 3 import time 4 df['timestamp'] = df['time'].apply(lambda x:time.mktime(time.strptime(x,'%d%b%y:%H:%M:%S')))
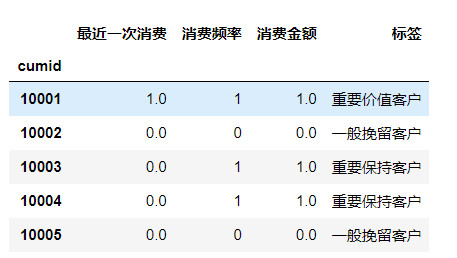
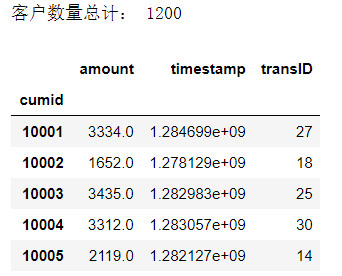
1 # 构造RMF模型的特征值 2 rfm = df.pivot_table( 3 index = 'cumid', 4 values = ['timestamp','transID','amount'], 5 aggfunc = { 6 'timestamp':'max', # R 最近消费时间 7 'transID':'count',# F 消费频率 8 'amount':'sum', # M 消费总金额 9 }) 10 print('客户数量总计:',len(rfm)) 11 rfm.head()
1 ### 构建模型,筛选目标客户,通过将需要转换成类别型数据的连续型数据进行二值化,用1,0分别代表高低 2 3 from sklearn import preprocessing 4 5 threshold = pd.qcut(rfm["timestamp"], 2, retbins=True)[1][1] 6 binarizer = preprocessing.Binarizer(threshold=threshold) 7 time_new_q = pd.DataFrame(binarizer.transform(rfm["timestamp"].values.reshape(-1, 1))) 8 time_new_q.index=rfm.index 9 time_new_q.columns=["最近一次消费"] 10 11 threshold = pd.qcut(rfm['transID'], 2, retbins=True)[1][1] 12 binarizer = preprocessing.Binarizer(threshold=threshold) 13 interest_q = pd.DataFrame(binarizer.transform(rfm['transID'].values.reshape(-1, 1))) 14 interest_q.index=rfm.index 15 interest_q.columns=["消费频率"] 16 17 threshold = pd.qcut(rfm['amount'], 2, retbins=True)[1][1] 18 binarizer = preprocessing.Binarizer(threshold=threshold) 19 value_q = pd.DataFrame(binarizer.transform(rfm['amount'].values.reshape(-1, 1))) 20 value_q.index=rfm.index 21 value_q.columns=["消费金额"] 22 23 24 analysis=pd.concat([time_new_q, interest_q, value_q], axis=1) 25 26 analysis = analysis[['最近一次消费','消费频率','消费金额']] 27 # analysis.head() 28 29 label = { 30 (1,1,1):'重要价值客户', 31 (1,0,1):'重要发展客户', 32 (0,1,1):'重要保持客户', 33 (0,0,1):'重要挽留客户', 34 (1,1,0):'一般价值客户', 35 (1,0,0):'一般发展客户', 36 (0,1,0):'一般保持客户', 37 (0,0,0):'一般挽留客户', 38 } 39 analysis['标签'] = analysis[['最近一次消费','消费频率','消费金额']].apply(lambda x: label[(x[0],x[1],x[2])], axis = 1) 40 analysis.head()