前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:人厨子

概述
爬虫项目实践
目标:首都医科大学官网新发文章
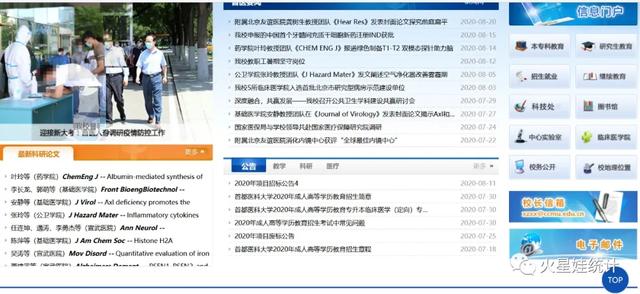
步骤
- 请求网址
- 通过正则表达式提取数据
- 分析数据
代码
# 导入模块 # 用于请求网址 import requests # 用于解析网页源代码 from bs4 import BeautifulSoup # 用于正则 import re # 目标网址 # 设置页数,提取10页的数据 page=[''] for i in range(1,10,1): page.append(i) # 保存文件 with open(r'ccmu.csv','a',encoding='utf-8') as f: for i in page: url= 'http://www.ccmu.edu.cn/zxkylw_12912/index'+str(i)+'.htm' # 必要时添加header请求头,防止反爬拦截 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0' } # 目标网址请求方式为get resp=requests.get(url) html = resp.content.decode('utf-8') # 解析html soup = BeautifulSoup(html,'html.parser') # 找到最近发表的sci论文 # 使用find和find_all 函数 infos=soup.find('ul',{'class':'list03'}).find_all('li') for info in infos: time=info.find('span').get_text() ajt= info.find('a').get_text() # 写入文件 f.write("{},{}\n".format(time,ajt))
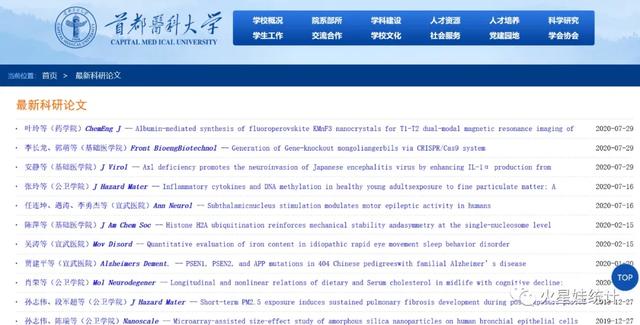
结果

PS:如有需要Python学习资料的小伙伴可以加下方的群去找免费管理员领取

可以免费领取源码、项目实战视频、PDF文件等