前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Darcy频道
import requests from lxml import etree import re from bs4 import BeautifulSoup import openpyxl import csv def get_price(): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0', 'Refrer': 'https://ganzhou.newhouse.fang.com/house/s/b9{}/', } for i in range(1, 10): url = "https://ganzhou.newhouse.fang.com/house/s/b9{}/".format(str(i)) response = requests.get(url, headers=headers) if response.status_code == 200: xml = etree.HTML(response.content.decode('gbk')) name = xml.xpath('//div[@class="nl_con clearfix"]//div[@class="nlc_details"]//a[@data-yd=""]//text()') for index in range(len(name)): name[index] = name[index].strip() address = xml.xpath('//div[@class="nl_con clearfix"]//div[@class="nlc_details"]//div[@class="address"]/a/text()') for index in range(len(address)): address[index] = address[index].strip() price = xml.xpath('//div[@class="nl_con clearfix"]//div[@class="nlc_details"]//div[@class="nhouse_price"]/span/text()') for index in range(len(price)): price[index] = price[index].strip() with open('赣州房价.csv', 'w') as f: writer = csv.writer(f) writer.writerows(zip(name, price, address)) f.close() if __name__ == '__main__': get_price()
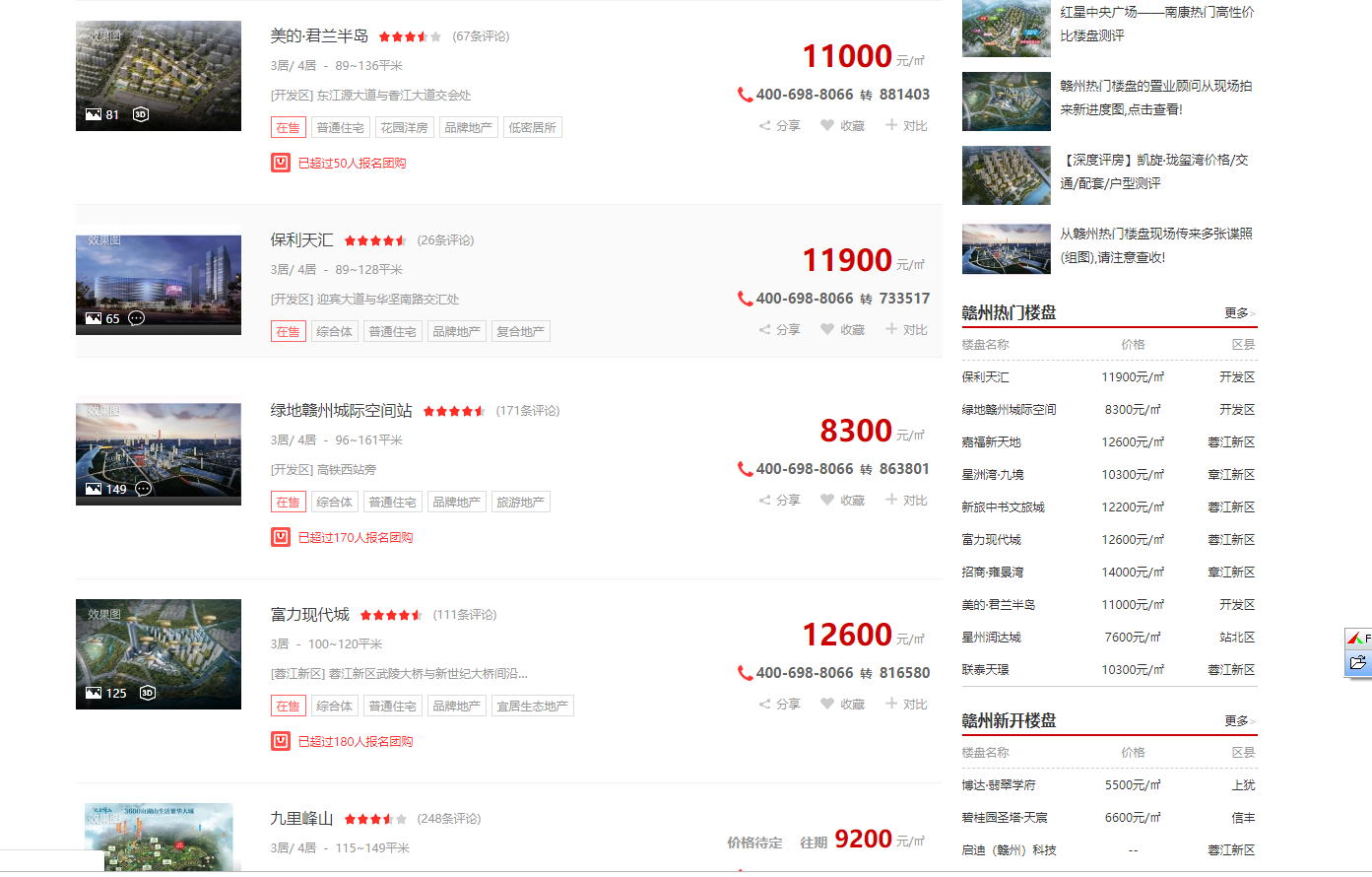
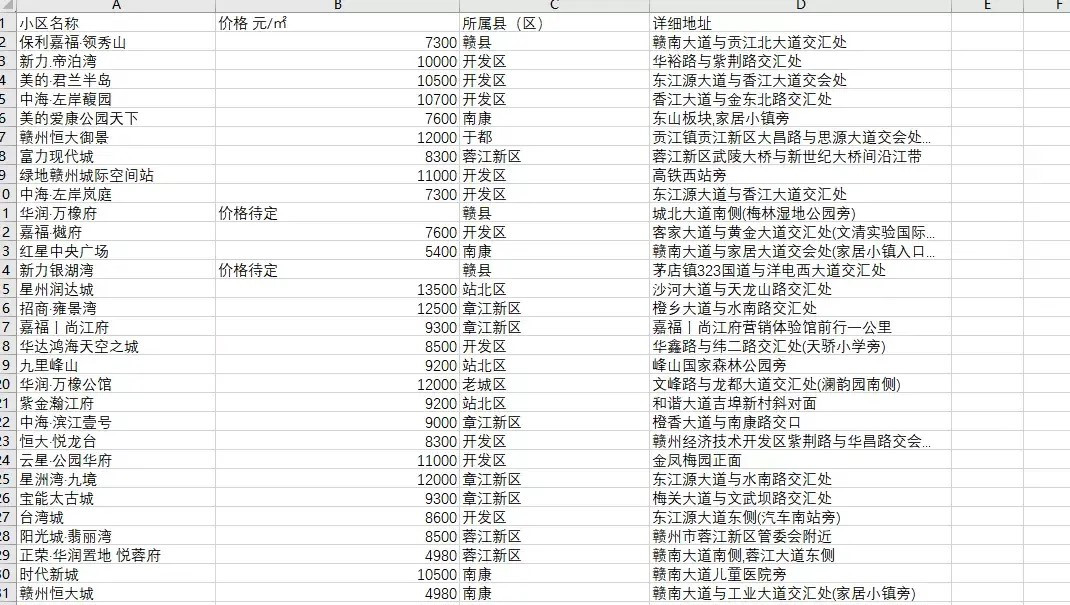
示例结果:
PS:如有需要Python学习资料的小伙伴可以加下方的群去找免费管理员领取

可以免费领取源码、项目实战视频、PDF文件等