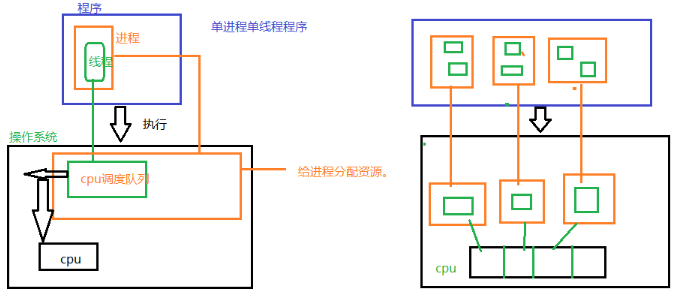
一、程序进程和线程之间的关系
程序:一个应用就是一个程序,比如:qq,爬虫
进程:程序运行的资源分配最小单位,
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
一个程序可以至少有一个进程
线程:cpu的最小调度单位,必须依赖进程而存在,一个进程至少有一个线程,线程是没有独立资源的,一个进程下的所有线程共享该进程所有资源
一个程序至少有一个进程,一个进程至少有一个线程
多任务的目的:充分利用计算机的物理性能,来提高程序运行速度
单线程程序:程序运行的过程中,cpu的利用很低的
遇到各种阻塞,等待这些情况,此时cpu就处于空闲状态
提高cpu的利用有两种方式:
1、cpu有多个核心的,如何利好各个核心多进程编程,
2、单个cpu,如何提高利用率,就是通过多线程编程
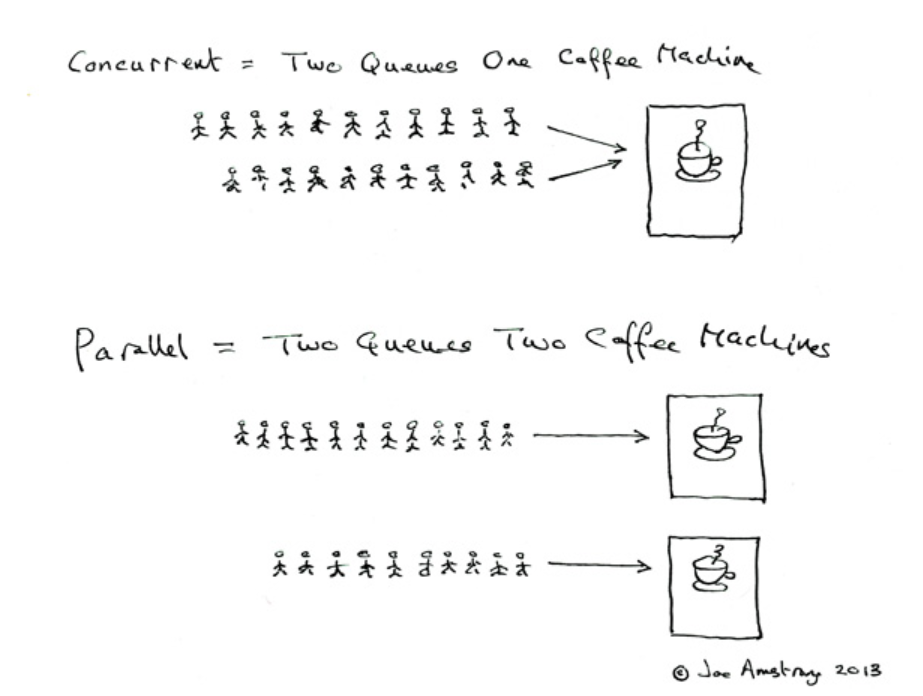
并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机,如果串行,一个队列使用一台咖啡机
两种解决办法:
1、纵向扩展:
买更好的cpu,提高硬件水平。—缺点:总有极限。
2、横向扩展:
增加电脑。分布式思想
并行: 真正的同时执行
在python中并行通过多进程实现
并发: 在统一时刻,cpu只能运行一个任务。但是cpu在各个任务之间切换,因为时间间隔很多,总体可以看来是多个程序一起执行
python的多线程其执行过程就是并发
串行: 有一个任务执行单元,从物理上就只能一个任务、一个任务地执行
前提:cpython编译器
GIL:全局性解释锁。他让多个线程在同时执行后,统一时刻,只能有一个线程拿到GIL这把锁,拿到这把锁的线程,cpu才能执行,存在目的就是为了简化多线程编程,同时避免进程之间数据错乱
缺点:严重制约多线程执行效率
如果利用多线程和多进程将我们程序执行效率提到极致。将cpu的利用率达到100%—还不满足,如何解决?
两种解决办法:
1、纵向扩展:https://user-gold-cdn.xitu.io/2020/7/17/1735bf415da0617a?w=6https://user-gold-cdn.xitu.io/2020/7/17/1735bf415da0617a?w=692&h=452&f=png&s=7952192&h=452&f=png&s=79521
买更好的cpu,提高硬件水平。—缺点:总有极限
2、横向扩展:
增加电脑,分布式思想
想要完成一个功能,有两种选择:
完成创建线程功能
1、使用python已经设置好的模块。
threadin模块
(1)创建一个线程
t = threading.Thread(
target=线程的做的事,一般只需要指定方法的引用即可。
args = (按顺序写入参数列表)–一个元组
)
(2)启动线程
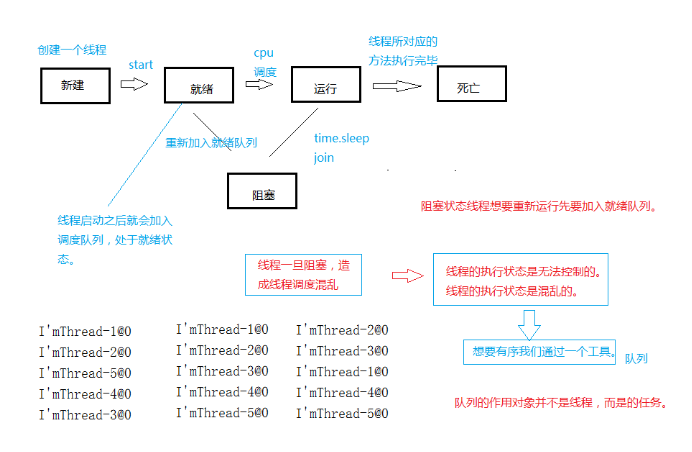
t.start()----启动之后该线程和主线程都是线程
启动之后他和主线程到底谁先执行只有cpu的调度队列来决定的
2、自己造轮子
显示生活中想要制造汽车,并不是一件容易的事情
相比而言,在代码中,先要自己取实现一个线程类,也不容易。但是面向对象有一种思想:继承可以轻松做到造轮子
继承:
-
子类继承父类非私有一切属性和方法
-
子类重写父类的属性和方法,子类拥有就是自己的。(子类实例化后,调用这些属性和方法其实调度就是自己的)
对于继承编程思想:
1、我们想要完成哪些功能,可以使用这个模块
2、当这个模块的默写功能无法满足我们需求的时候,我们可以继承他,就有他的特性
3、如果对那个方法不满足,就重写他
创建线程第二种方法:
1、写一个类
2、继承threading.Thread
3、重写run方法
因为线程启动之后,底层执行的run方法
4、实例化这个类,就相当于创建了一个线程,对象.start()可以启动这个线程
在线程类的使用过程中,一定要让父类的init方法触发
如果自定义线程类实现了init方法,必须在init方法中手动调用父类init方法执行
super().init()
threading.Thread.init(self)
import pymongo
#1、创建连接
client=pymongo.MongoClient(host='localhost',port=27017)
#2、连接数据库
db = client['tencent_data']#如果数据库不存在直接创建
#3、db就相当于数据库引用
#True:upsert=true---有则更新,无则插入
db['招聘信息'].update({'PostId':item['PostId']},{'$set':item},True)
print(item,'保存成功!')
方法一:使用创建线程的方法

代码实现:
for i in range(1, 100):
# parse_page(i)--->用线程代替
t = threading.Thread(target=parse_page, args=(i,))
t.start()
方法二:创建线程类

代码实现:
import pymongo
import requests, threading
from queue import Queue
class Tencent(threading.Thread):
def __init__(self, url, name, q_task):
super().__init__()
self.base_url = url
self.name = name
self.q_task = q_task
# 1、创建连接
self.client = pymongo.MongoClient(host='localhost', port=27017)
# 2、连接数据库
self.db = self.client['tencent_data'] # 如果数据库不存在直接创建
def get_json(self, url, page):
'''
请求ajax。获取json数据
:param url:
:param page:
:return:
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
params = {
'timestamp': '1595207127325',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': page,
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn',
}
response = requests.get(url, params=params, headers=headers)
return response.json()
def write_to_mongo(self, item):
# 3、db就相当于数据库引用
# True:upsert=true---有则更新,无则插入
self.db['招聘信息'].update({'PostId': item['PostId']}, {'$set': item}, True)
print(item, '保存成功!')
def parse_json(self, json_data):
'''
:param json_data:
:return:
'''
for data in json_data['Data']['Posts']:
self.write_to_mongo(data)
def parse_page(self, page):
base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?'
json_data = self.get_json(base_url, page)
# print(json_data)
self.parse_json(json_data)
def run(self):
while True:
if self.q_task.empty():
break
# 1、取出页码
page = self.q_task.get()
print(f'===========第{page}页====================@{self.name}')
# 2、请求,解析
self.parse_page(page)
if __name__ == '__main__':
base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?'
# 1、创建任务队列
q_page = Queue()
# 2、初始化任务队列---页码
for i in range(1, 200):
q_page.put(i)
# 3、创建线程的控制开关-list
crawl_list = ['aa', 'bb', 'cc', 'dd'] # 四个线程
# 4、遍历上面list来循环创建线程
for crawl in crawl_list:
t = Tencent(base_url, crawl, q_page)
t.start()
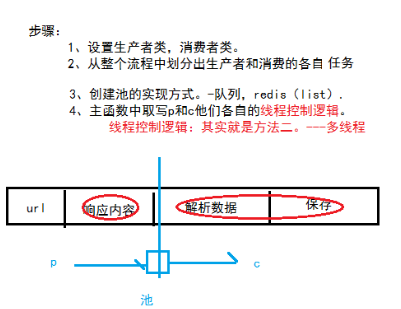
什么是生产者消费者模式?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费 者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待 消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力,下面基于队列实现生产者 消费者模型
定义: 在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题,该模式通过平衡生 产线程和消费线程的工作能力来提高程序的整体处理数据的速度
问题:耦合性太高,这种模式就是解耦合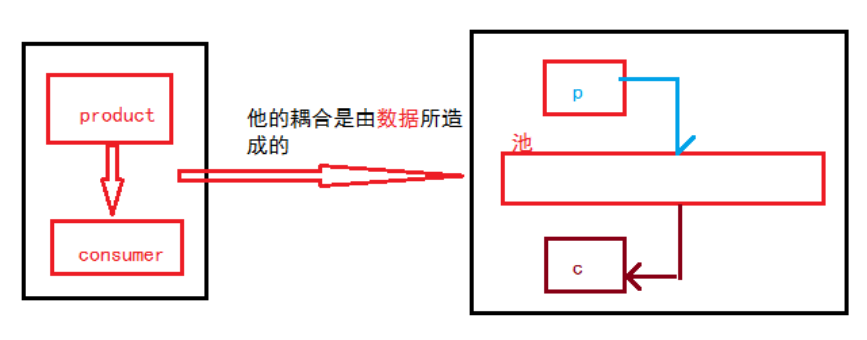
实现步骤:
代码实现:
import pymongo
import requests
from queue import Queue
import threading
class Product(threading.Thread):
def __init__(self, base_url, q_page, name=None):
super().__init__()
self.base_url = base_url
self.q_page = q_page
# self.name = name
def get_json(self, url, page):
'''
请求ajax。获取json数据
:param url:
:param page:
:return:
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
params = {
'timestamp': '1595207127325',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': page,
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn',
}
response = requests.get(url, params=params, headers=headers)
return response.json()
def run(self):
while True:
if self.q_page.empty():
break
page = self.q_page.get()
print(f'生产者线程:=======in {page} page===============@{self.name}')
json_data = self.get_json(self.base_url, page)
# q_json就是公共数据池
q_json.put(json_data)
class Consumer(threading.Thread):
def __init__(self):
super().__init__()
# 1、创建连接
self.client = pymongo.MongoClient(host='localhost', port=27017)
# 2、连接数据库
self.db = self.client['tencent_data2'] # 如果数据库不存在直接创建
def write_to_mongo(self, item):
# 3、db就相当于数据库引用
# True:upsert=true---有则更新,无则插入
self.db['招聘信息'].update({'PostId': item['PostId']}, {'$set': item}, True)
print(item, '保存成功!')
def parse_json(self, json_data):
'''
:param json_data:
:return:
'''
for data in json_data['Data']['Posts']:
self.write_to_mongo(data)
def run(self):
while True:
if q_json.empty() and flag: # ?问题关键在于:我们并没有监控生产者到底做完了没。
break
try:
# 1、取数据--从池子里取
json_data = q_json.get(block=False)
print(f'消费者线程:===@{self.name}==================data:f{json_data}')
# 2、解析保存
self.parse_json(json_data)
except Exception:
continue
if __name__ == '__main__':
base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?'
# 轮询参数
flag = False # p还没下班
# 1、创建一个池
q_json = Queue()
# 2、创建p和c各自线程取完成上述流程。
# 2.1 p的开启
# 初始化任务对垒
q_page = Queue()
for page in range(1, 200):
q_page.put(page)
# 保存生产者的每个线程的引用。
crawl_p = []
for i in range(3):
t = Product(base_url, q_page)
t.start()
crawl_p.append(t)
# 2.2创建c
for i in range(3):
t = Consumer()
t.start()
# 3|保证p都做完了,再将flag-->true
# 阻塞在这里--监测p都是否完成。---join()
a = [p.join() for p in crawl_p]
flag = True