操作环境: Windows10、Python3.6、Pycharm、谷歌浏览器
目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=default (拉钩Python职位)
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
爬虫目录
1、项目疑惑
拉钩爬虫区别于许多网站的反爬机制,即使请求头参数以及请求体参数加齐也无法请求返回正确数据,若返回 “您操作太频繁,请稍后再访问” 字眼,则表示被拉钩反爬机制识别你的不是正常浏览网页,而是爬虫程序请求。
{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"223.104.65.43","state":2402}
2、分析网页
本次项目与上次腾讯爬虫一样属于ajax加载的动态数据,但是他与腾讯招聘不同的是,列表页是ajax加载数据,而详情页却是静态数据,腾讯招聘则是经典的双ajax加载数据页面。
所以本次项目只为了解决反爬机制与爬取列表页数据即可,下次小编再带大家写一篇动静结合的爬虫项目,敬请期待。话不多说,开始进入正题!
2.1、POST请求
requests模块发送post请求时,提交的是data参数,但data表单参数不会在接口链接上显示,这与之get请求的params参数相反。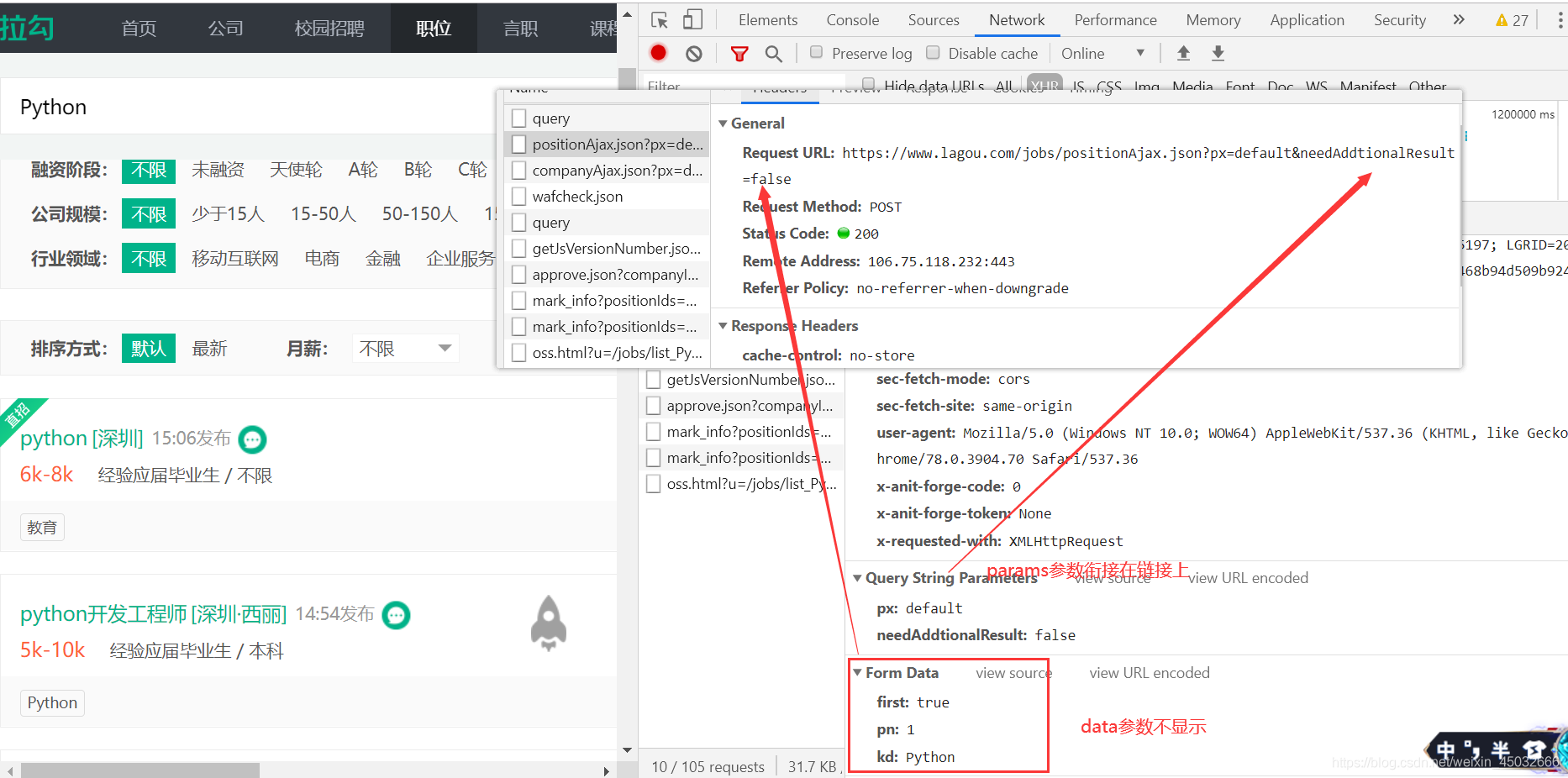
2.2、参数解析
px参数: 工作地点,爬取指定地点的岗位信息。
pn参数: 翻页页数。
kd参数: 职位名,爬取指定岗位名称的相关信息。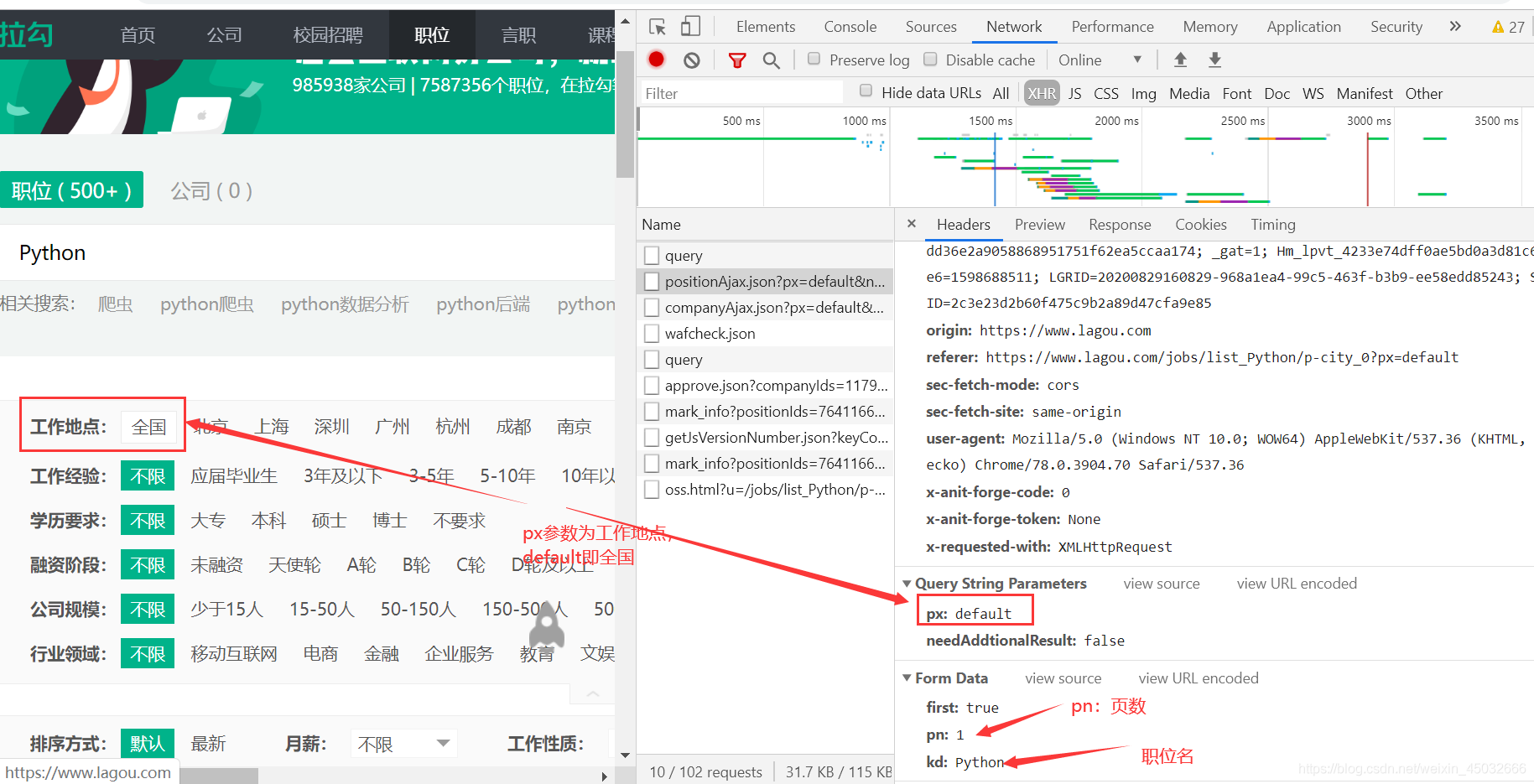
2.3、详情页分析
虽说此次不请求详情页里的数据,但还是帮其他有需要的小伙伴解析一波。
因为详情页为静态数据,所以我们直接分析它的链接即可。从岗位详情页链接可看出两个重要参数:职位特有id与show参数。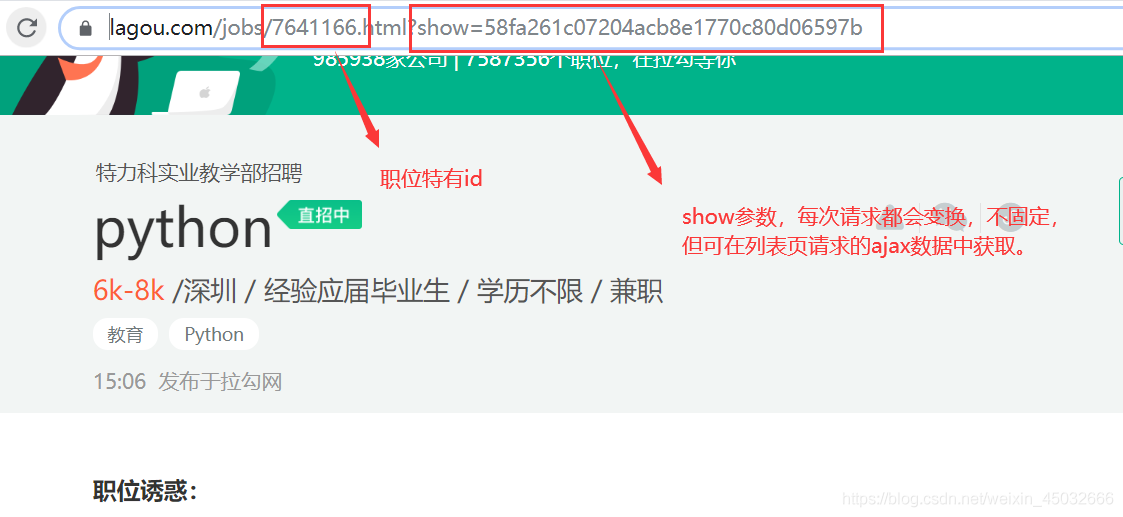
通过分析列表页的json数据发现岗位特有id与show参数均在里面。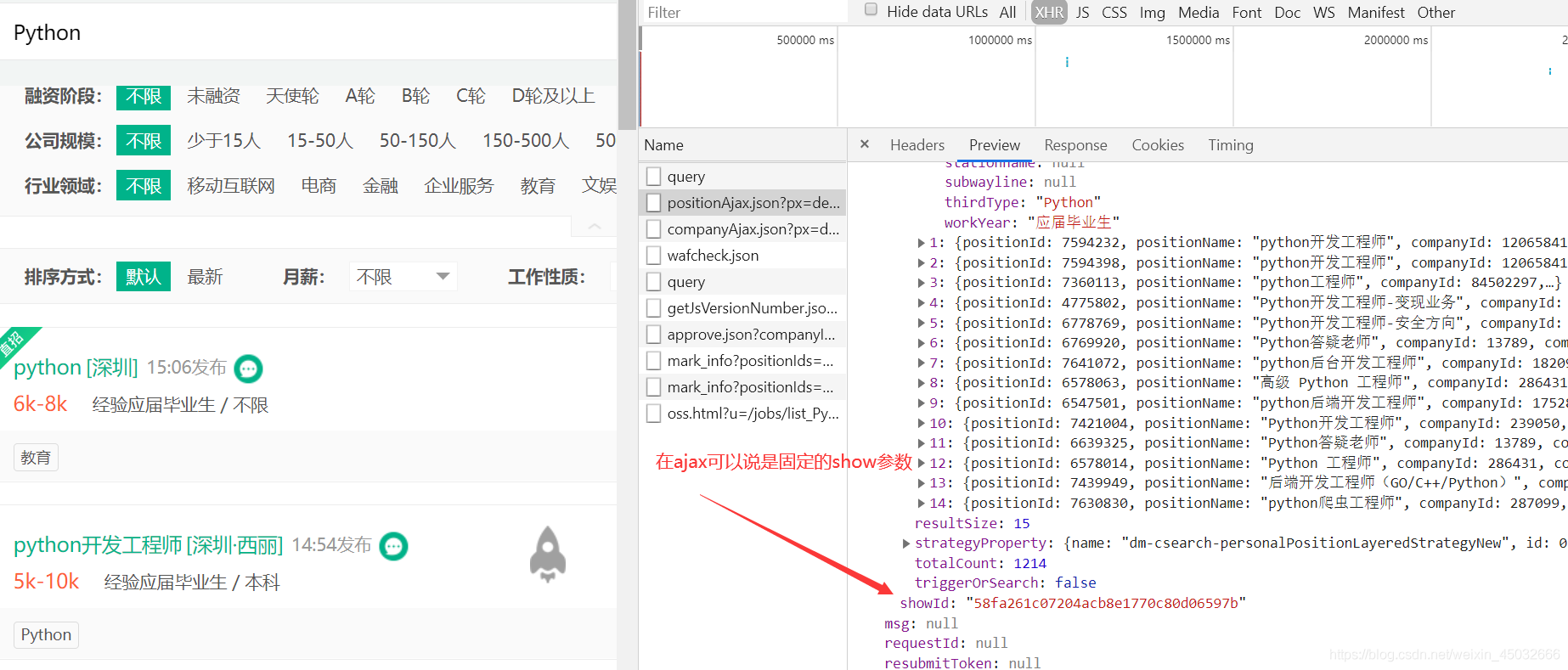
从下图可看出岗位特有id是固定不变的,然而show参数却是每次请求将变换,会更新,不固定。但无关系,直接从请求的列表页中获取即可,即请求即获取。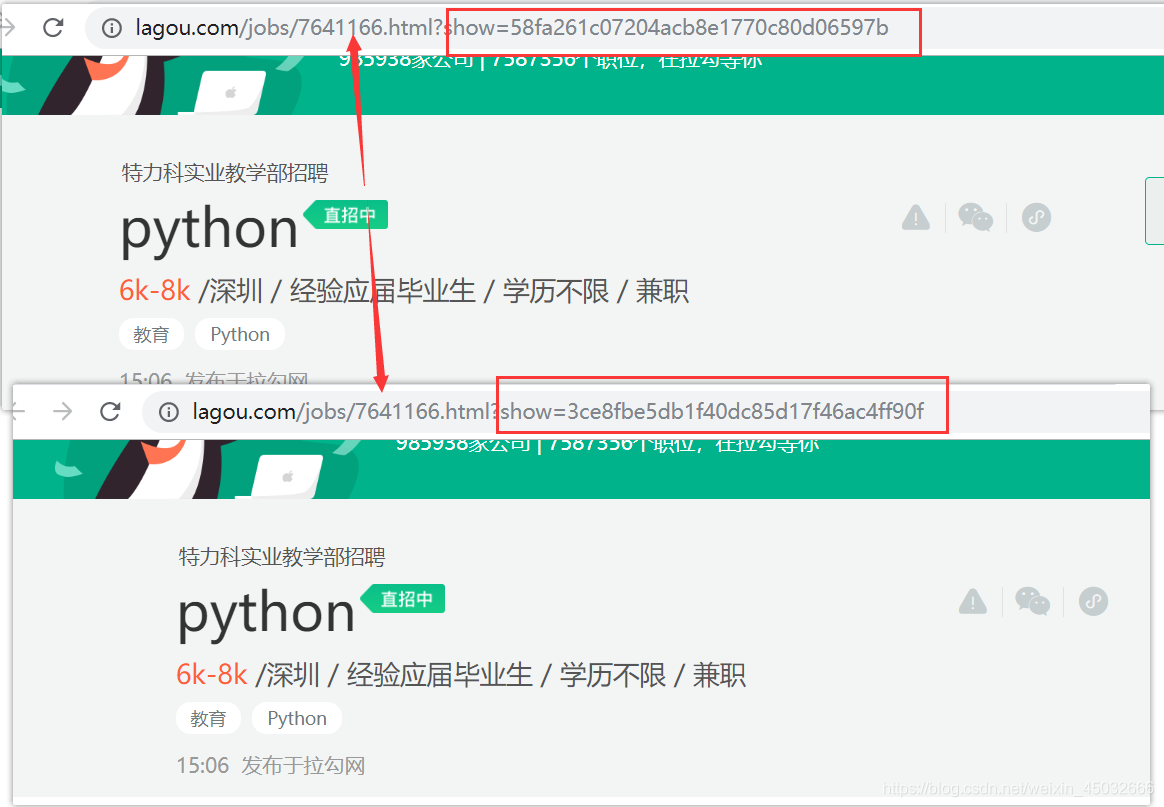
3、解决请求
目标网址: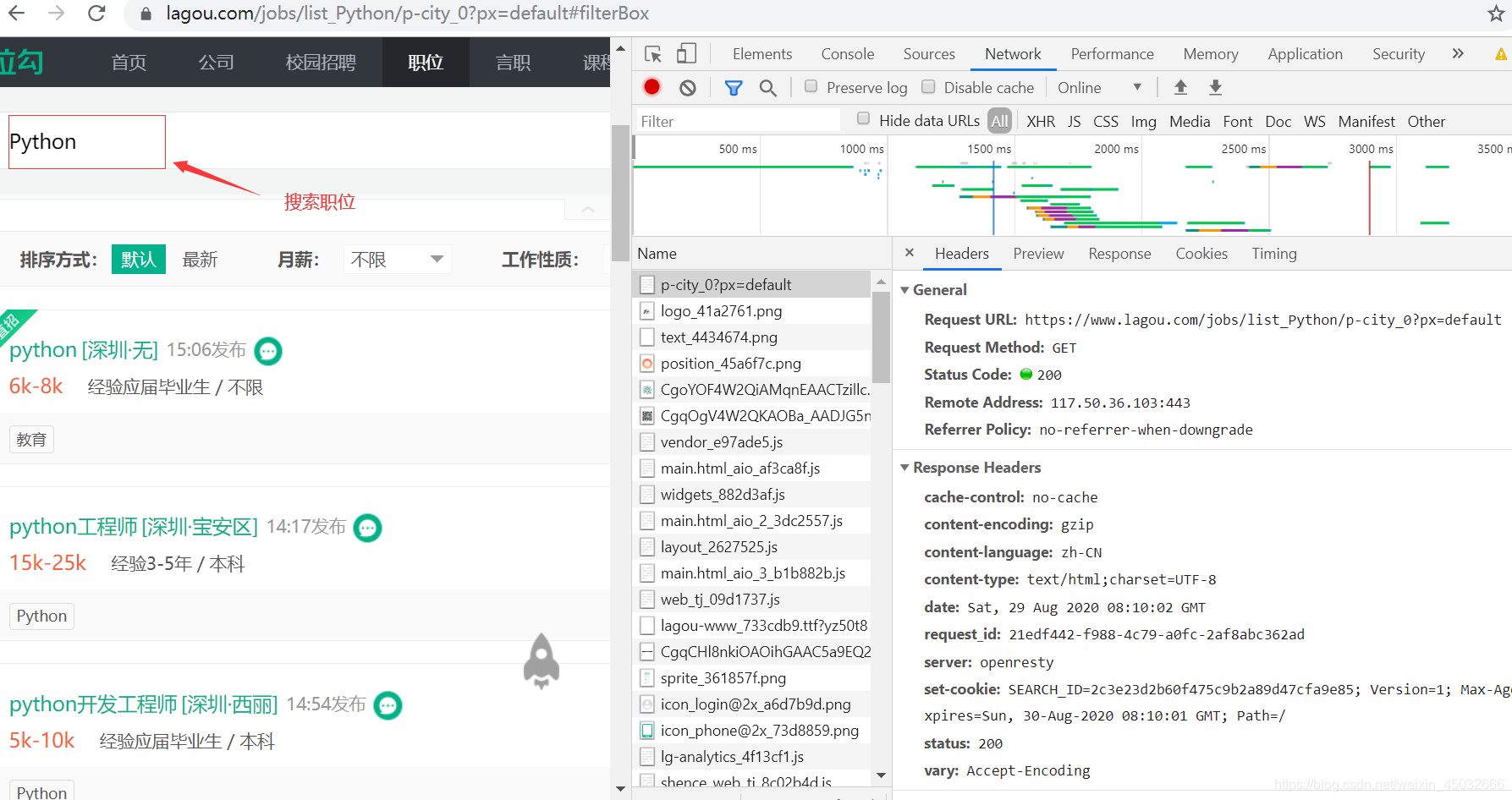
3.1、请求数据
分析好网页,开始写程序代码,首先导入需要的库以及设置请求头伪造身份,而post请求需要用到的data参数需要重复使用到,则定义一个from_data函数构建data参数,以便调用它。
# 导入需要的库
import requests
import json
import parsel
import openpyxl
import re
headers = { # 请求头,伪造身份
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
}
'''构建data表单'''
def from_data(kd,pn):
json_data = {
'first': 'false',
'pn': str(pn), # 页数
'kd': kd # 职位名
}
return json_data
'''请求数据'''
def get_data(json_url):
data = from_data('python','1')# 获取表单数据
# 请求接口链接
response = requests.post(url=json_url,headers=headers,data=data)
print(response.text)
if __name__ == '__main__':
# json接口链接
json_url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false'
get_data(json_url) # 获取数据
输出结果为"您操作太频繁,请稍后再访问",出现这情况表示拉钩服务器已识别这次请求为爬虫程序。一开始我以为是请求头参数没有加齐,随后将Headers里的origin与referer参数加上还是没有解决问题。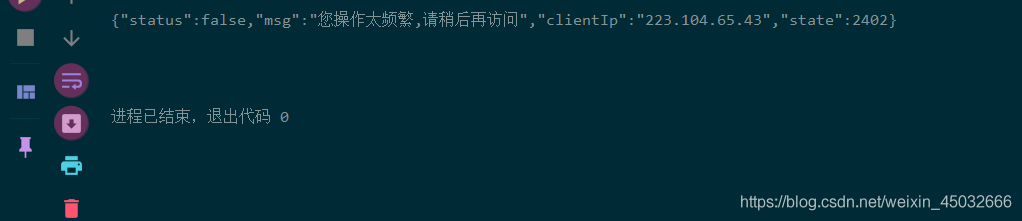
后面一想,会不会是爬虫请求频率过快,导致被拉钩服务器限制识别到了?而后我利用time模块设置延迟time.sleep(5)睡眠五秒,依然还是“操作频繁”的结果,脑瓜疼。
3.2、解决反爬
研究了三四个小时,依旧没有成。随后咨询了大佬,大佬一下给出了两个方案:
一、利用session保持会话登录提取数据;
二、请求搜索关键词链接的cookies信息,将其加入到json接口链接post请求中。
这次小编采取了第二种方案:定义一个get_cookies函数,用于请求关键字页面的cookies身份信息,以便post请求的调用。此外,重新定义两个请求头信息,分别用于获取cookie的get请求和获取json职位数据的post请求。
cookie_headers = { # cookie请求头,伪造身份
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'referer':'https://www.lagou.com/jobs/list_Python/p-city_213?&cl=false&fromSearch=true&labelWords=&suginput='
}
json_headers = { # json数据请求头
'Host': 'www.lagou.com',
"origin": "https://www.lagou.com",
"referer": "referer: https://www.lagou.com/jobs/list_Python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36",
}
'''请求cookies值'''
def get_cookies(cookies_url):
# allow_redirects重定向
response = requests.get(url=cookies_url, headers=headers, allow_redirects=False)
cookies = response.cookies # get请求获取cookies值
return cookies
'''请求数据'''
def get_data(json_url):
# for pn in range(1,3,1):
# 搜索关键字链接
cookies_url = 'https://www.lagou.com/jobs/list_Python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
cookies = get_cookies(cookies_url) # 获取cookie
json_data = from_data('1','Python') # 获取表单数据
# 请求接口链接
response = requests.post(url=json_url,headers=json_headers,cookies=cookies,data=json_data)
print(response.text)
这里测试一页,输出结果中有Python的职位名,获取的数据无误,反爬解决成功!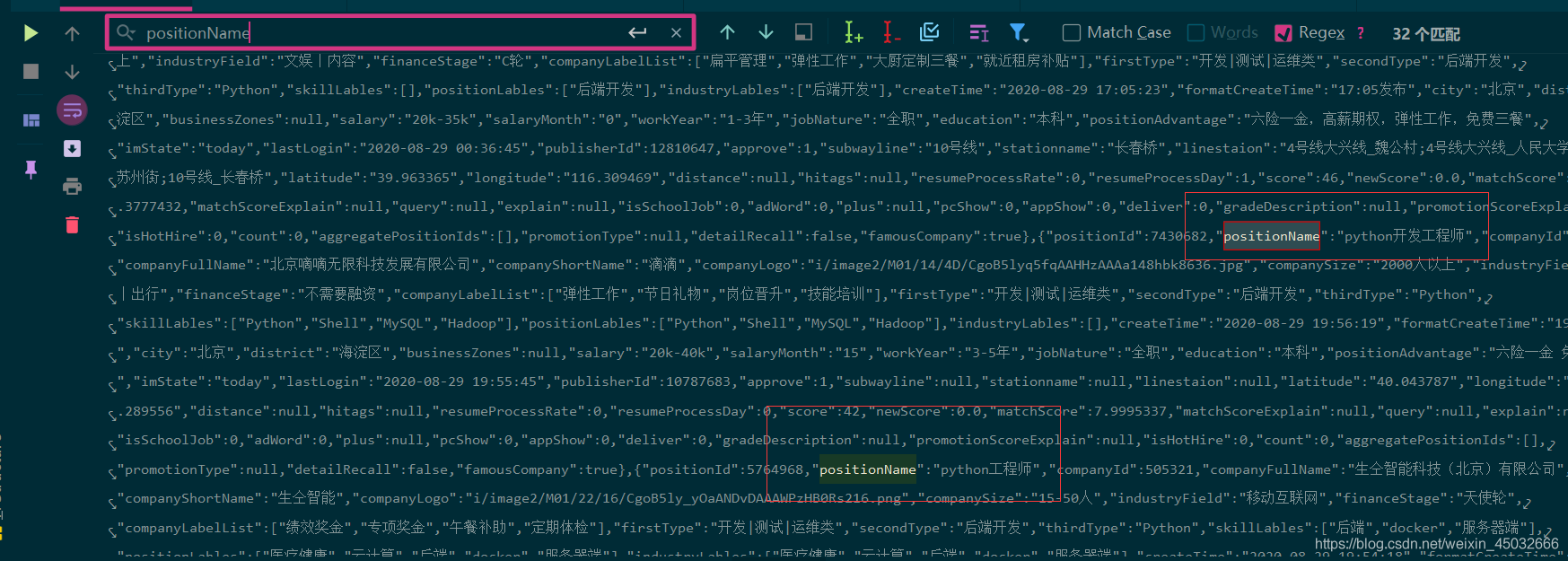
4、翻页
搜索关键字职位页面,每个职位固定显示30页。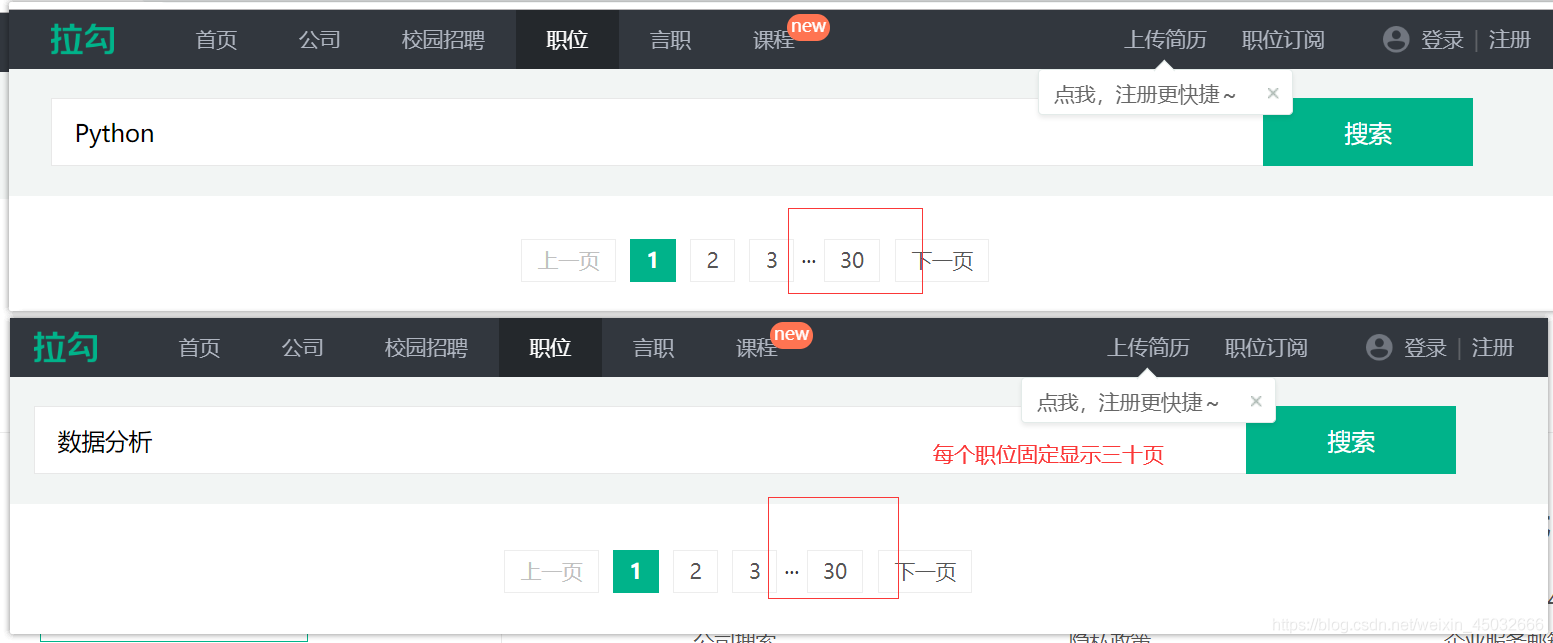
由于数据是ajax加载,应该在职位链接接口返回数据里查看总的数据量。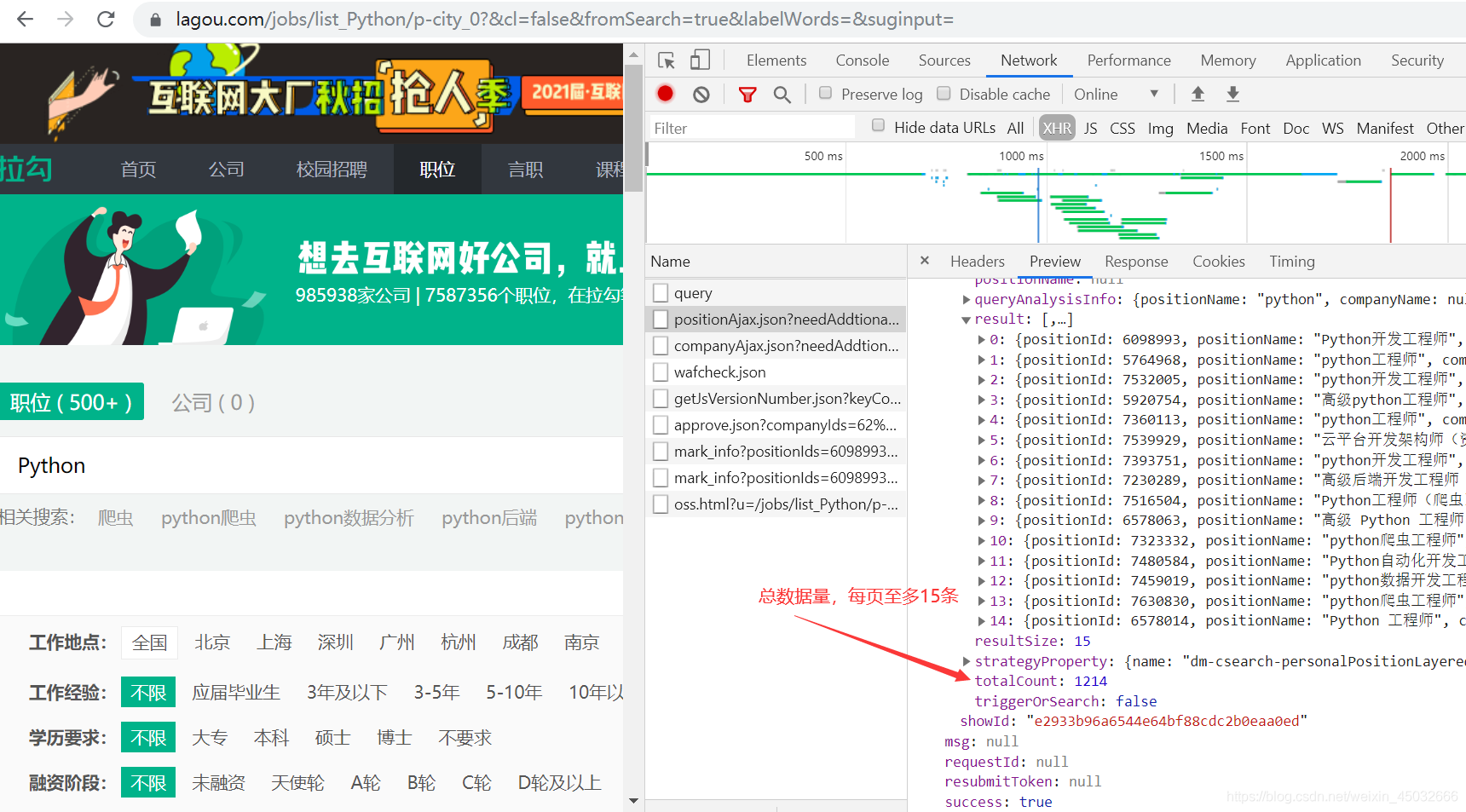
分析得知,有些职位超过几百页甚至上千页数据,但过了200都是空的数据,即某些职位至多可爬到200页。
4.1、for循环翻页
for循环翻页即手动设置翻页页数,这样只适合单个职位爬取方式,简单有效。
for pn in range(1,10,1): # for循环翻页
# 搜索关键字链接
cookies_url = 'https://www.lagou.com/jobs/list_Python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
cookies = get_cookies(cookies_url) # 获取cookie
json_data = from_data(str(pn),'Python') # 获取表单数据
# 请求接口链接
response = requests.post(url=json_url,headers=json_headers,cookies=cookies,data=json_data)
print(len(response.text))
这里代码测试十页,len()返回长度成功!:
4.2、while循环翻页
自定义每页总的职位数量,while True无限循环,每循环一次加每页总的职位数量,直到自定义的职位数量大于获取到的总职位量,便结束循环、结束翻页。
提取相关的职位字段数据。
replace:替换
‘’.join():合并
'''请求数据'''
def get_data(json_url):
data_list = [] # 定义一个空列表,用于填充获取到的字段数据
pn = 15
while True:
# 搜索关键字链接
cookies_url = 'https://www.lagou.com/jobs/list_Python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
cookies = get_cookies(cookies_url) # 获取cookie
json_data = from_data(int(pn / 15),'Python') # 获取表单数据
# 请求接口链接
response = requests.post(url=json_url,headers=json_headers,cookies=cookies,data=json_data)
results = response.json()['content']['positionResult']['result']
for result in results:
id = result['positionId'] # id
positionName = result['positionName'] # 职位名称
city = result['city'] # 城市
companyFullName = result['companyFullName'] # 公司名称
pub_time = result['createTime'] # 发布时间
education = result['education'] # 学历
firstType = result['firstType'] # 职位类型
firstType = firstType.replace('|', '-')
salary = result['salary'] # 薪资
workYear = result['workYear'] # 工作经验
companySize = result['companySize'] # 公司规模
skillLables = result['skillLables'] # 学识要求
skillLables = '-'.join(skillLables)
companyLabelList = '-'.join(result['companyLabelList']) # 公司福利
# 输出获取到的字段数据
print(id, positionName, city, companyFullName, pub_time, education,
firstType, salary, workYear, companySize, skillLables, companyLabelList)
data_list.append([id, positionName, city, companyFullName, pub_time, education,
firstType, salary, workYear, companySize, skillLables, companyLabelList])
pn += 15 # 每循环一次增加一页
if pn > response.json()['content']['positionResult']['totalCount'] + 15:
break # 超过总职位数便结束循环
return data_list
代码输出部分结果:
5、存入Excel
存excel表格需要用到openpyxl,import openpyxl导入,下载即pip install openpyxl
5.1、Excel表头
openpyxl.Workbook(): 创建一个excel薄
create_sheet(): 选择簿名
cell: 操作某行某列的某个值
row: 行
column: 列
value: 值
# 创建一个excel薄
wb = openpyxl.Workbook()
sheet1 = wb.create_sheet('position')
# 写入excel表头
sheet1.cell(row=1, column=1, value='id')
sheet1.cell(row=1, column=2, value='职位名称')
sheet1.cell(row=1, column=3).value = '城市'
sheet1.cell(row=1, column=4).value = '公司名称'
sheet1.cell(row=1, column=5).value = '发布时间'
sheet1.cell(row=1, column=6).value = '学历'
sheet1.cell(row=1, column=7).value = '职位类型'
sheet1.cell(row=1, column=8).value = '薪资'
sheet1.cell(row=1, column=9).value = '工作经验'
sheet1.cell(row=1, column=10).value = '公司规模'
sheet1.cell(row=1, column=11).value = '职位要求'
sheet1.cell(row=1, column=12).value = '公司福利'
wb.save('拉勾招聘岗位信息.xlsx')
5.2、保存函数
定义一个save_excel函数用于将数据存入Excel表格。
data_list:数据列表
'''保存为excel文件'''
def save_excel(data_list):
wb = openpyxl.load_workbook('拉勾招聘岗位信息.xlsx')
sheet = wb['position']
for d in data_list:
sheet.append(d) # 写入数据
wb.save('拉勾招聘岗位信息.xlsx') # 保存
共获取一千二百多条数据,程序成功运行完毕!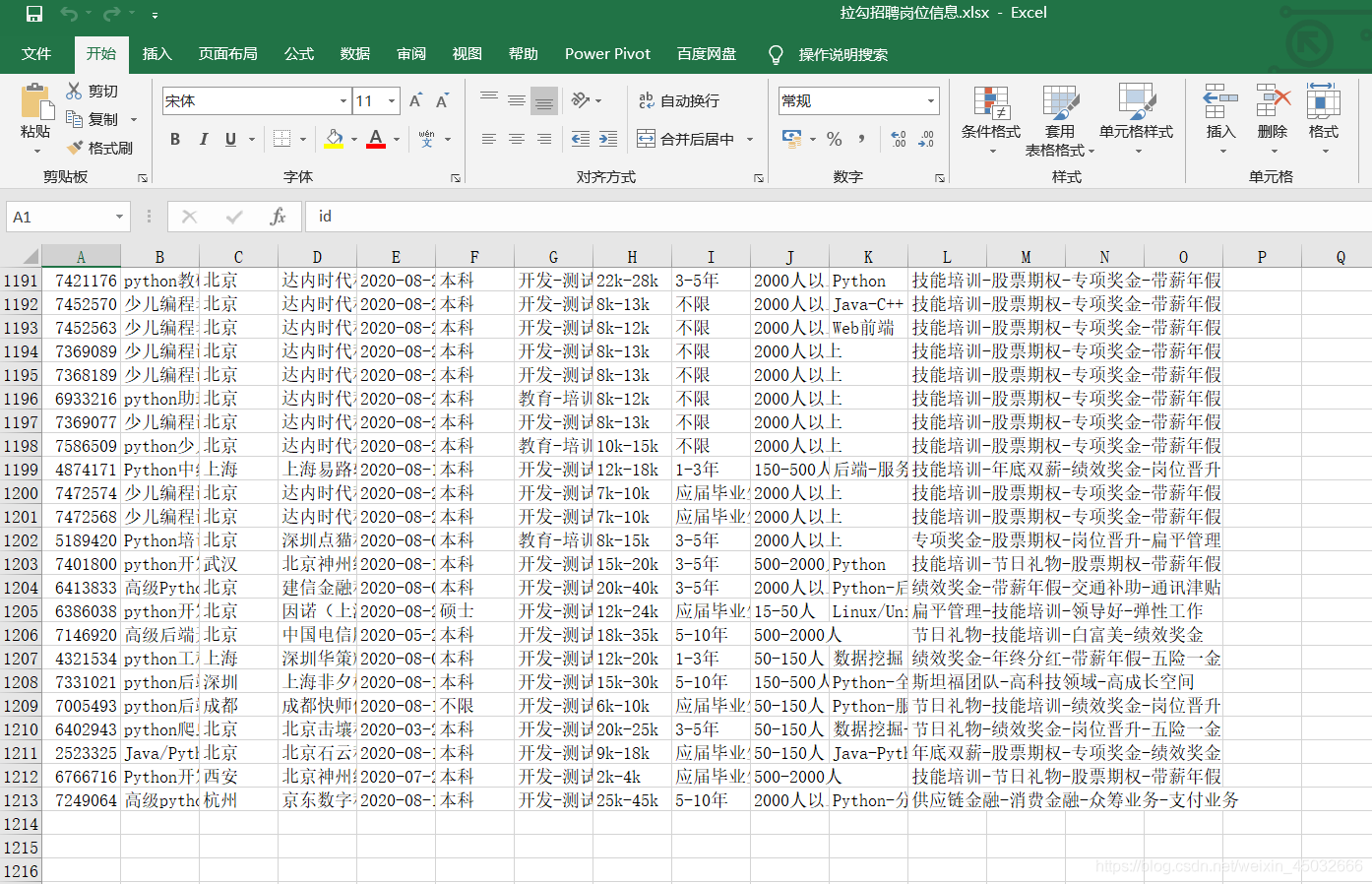
六、项目总结
本次项目只爬取了一个Python职位信息,若想继续爬取更多的职位信息,可以定义一个职位列表,将需要爬取的职位名写入其中即可。
但需要注意的地方有两点:
6.1、填充问题
爬取相应的职位需要注意请求头referer参数填充职位名以及请求cookies的链接填充与data表单kd参数的职位名。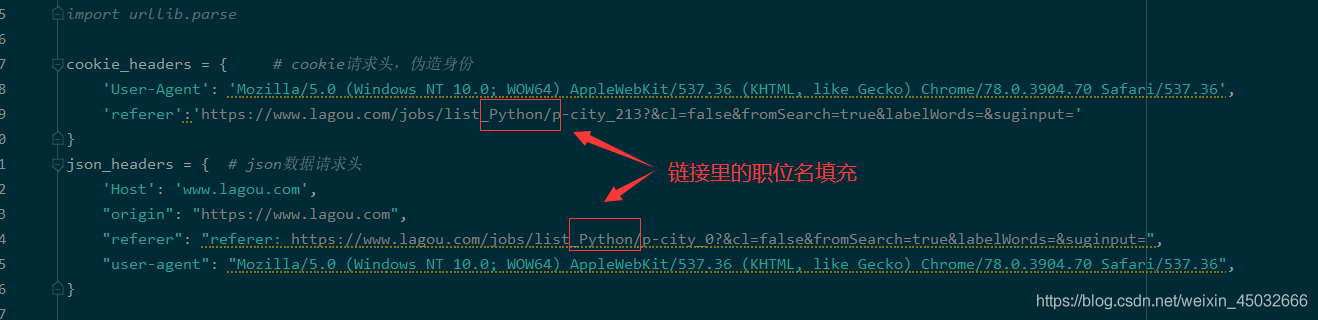

由上图可看出若爬取多个职位名信息的情况下,使用while循环获取每个职位的总页数是非常明智的选择。
6.2、汉字职位填充问题
职位名填充有些特殊,若只是Python、java等英文字母组成的职位名则无需转码,而若是大数据、数据分析等汉字组成的职位名时,需要转码成前端适合的编码格式才能获取数据。例如:数据分析 —> %E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90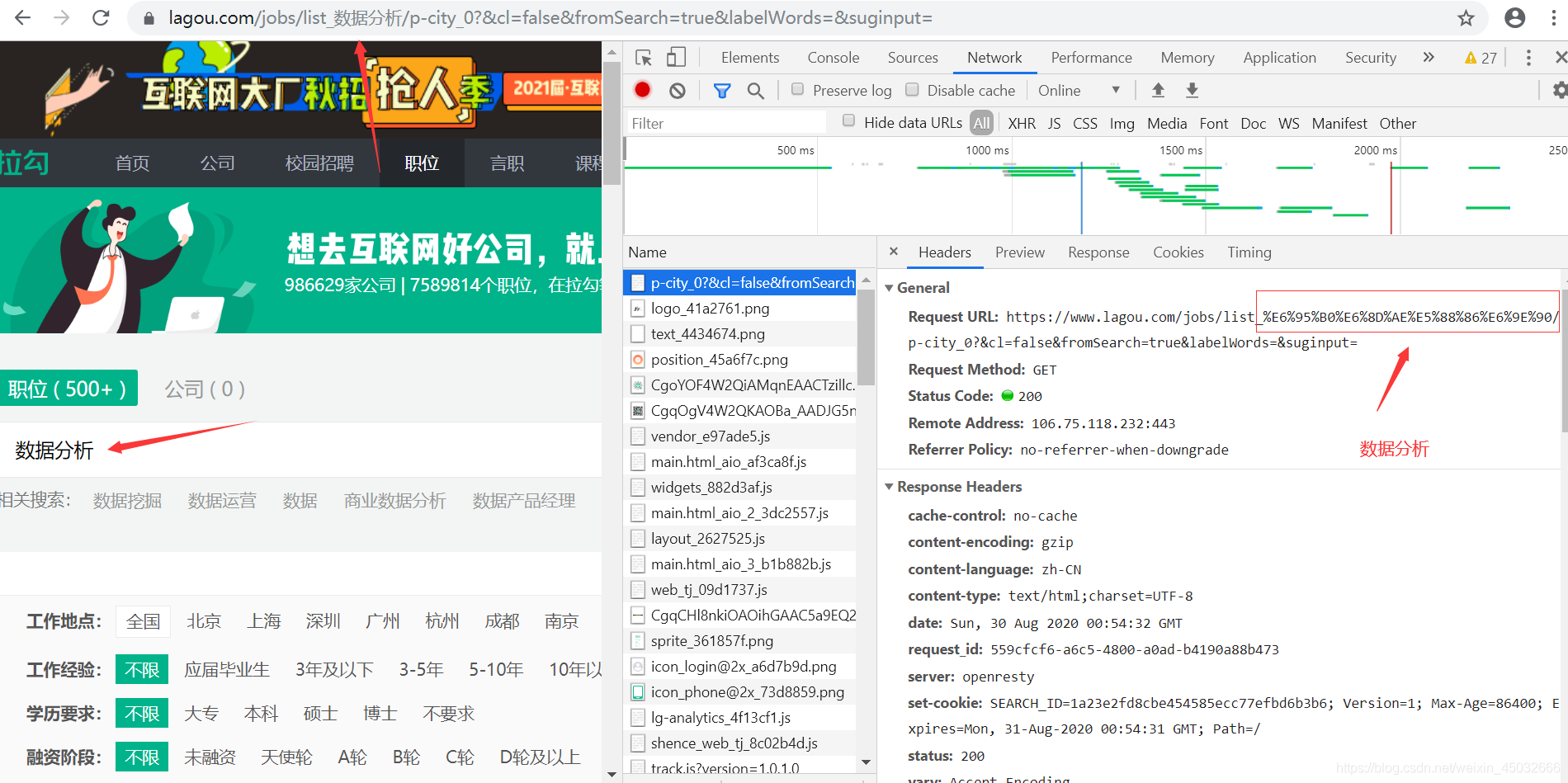
转化为前端适合的编码格式,需要用到urllib内置库里的parse函数,直接导入即可import urllib.parse 。
import urllib.parse
kd = '数据分析'
position_html = urllib.parse.quote(kd)
print('转化为前端适合的编码格式:',position_html)
# 执行position_html结果为:转化为前端适合的编码格式: %E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90
position = urllib.parse.unquote(position_html)
print('转化为Python程序适合的编码:',position)
# 执行position结果为:转化为Python程序适合的编码: 数据分析
如代码所示,链接填充用position_html即可,若data表单里的kd职位名参数用position即可。