本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
以下文章来源于欺骗大师 ,作者 魔术师
本次任务背景:
https://www.shixiseng.com爬取一下实习僧IT互联网的Python实习信息
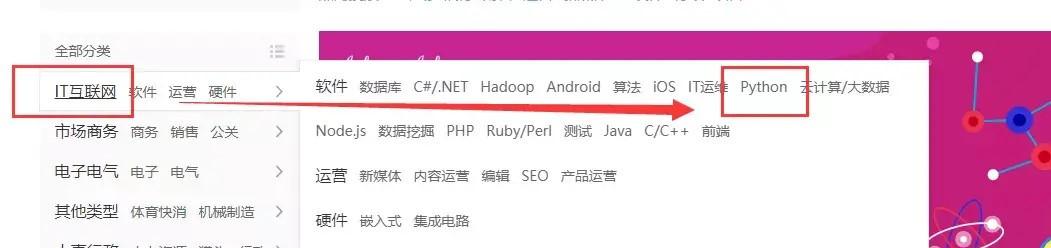
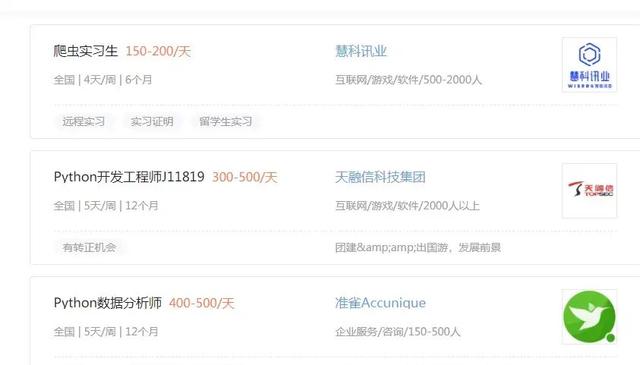

然后看一下网址规律

从上面的网址可以看出,只有page=?这里变化了
接着再点进去,查看相应的详细数据:https://www.shixiseng.com/intern/inn_1k3vhcwwguaf?pcm=pc_SearchList
然后再查看相应源代码的属性
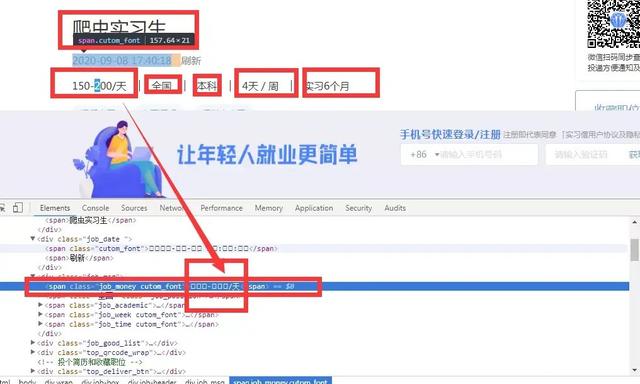
如上图所示,该字段的数据看不见,可能它不希望你很简单的就获得它网站的这些数据,这些数据对他来说比较重要,所以启用了反爬技巧
如果直接运行,这些数据是爬取不下来的,如下图:
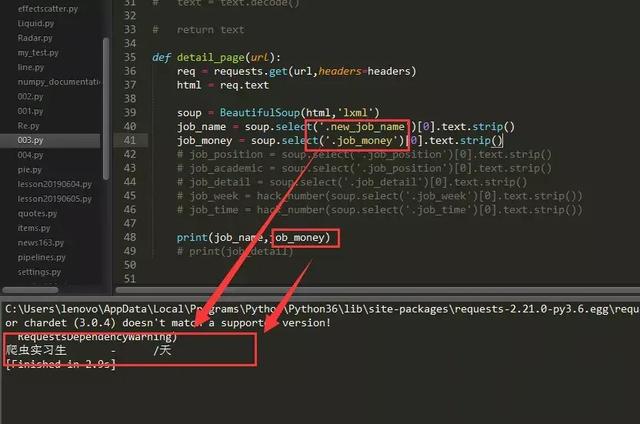
反反爬技巧:实际上这是编码问题,我们只要用一种编码方式,比如“utf-8”编码来表现这些数据,然后再用你选的编码方式来替换相应的数据部分,如下图:
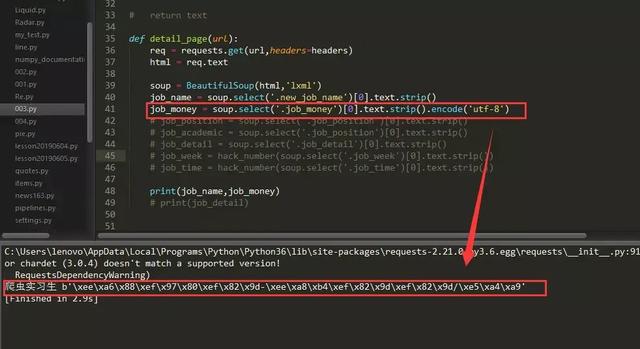
如上图,相关数据已经以“utf-8”编码的方式呈现出来
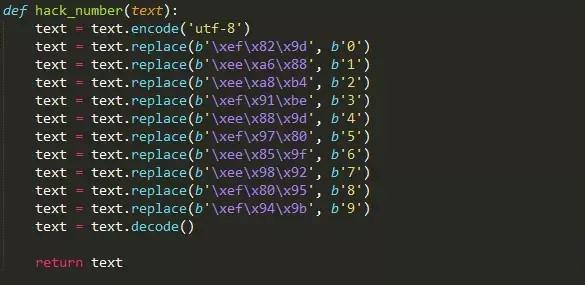
创建函数hack_number(),用于解码数字
然后再观察一下点进去的网址:

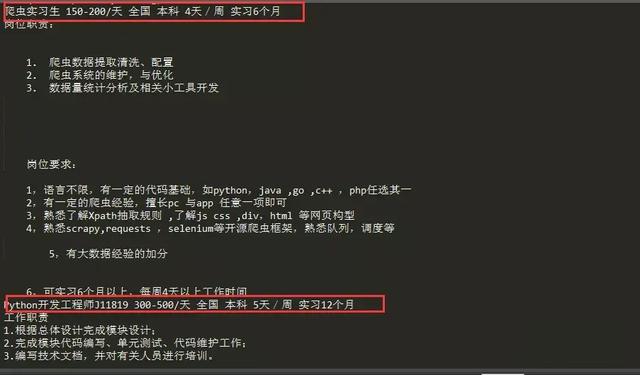
编写好相关代码之后,查看运行结果
完整代码如下:
import requests from bs4 import BeautifulSoup headers = {"user-agent":"Mozilla/5.0"} def hack_number(text): text = text.encode('utf-8') text = text.replace(b'\xef\x82\x9d', b'0') text = text.replace(b'\xee\xa6\x88', b'1') text = text.replace(b'\xee\xa8\xb4', b'2') text = text.replace(b'\xef\x91\xbe', b'3') text = text.replace(b'\xee\x88\x9d', b'4') text = text.replace(b'\xef\x97\x80', b'5') text = text.replace(b'\xee\x85\x9f', b'6') text = text.replace(b'\xee\x98\x92', b'7') text = text.replace(b'\xef\x80\x95', b'8') text = text.replace(b'\xef\x94\x9b', b'9') text = text.decode() return text def detail_page(url): req = requests.get(url,headers=headers) html = req.text soup = BeautifulSoup(html,'lxml') job_name = soup.select('.new_job_name')[0].text.strip() job_money = hack_number(soup.select('.job_money')[0].text.strip()) job_position = soup.select('.job_position')[0].text.strip() job_academic = soup.select('.job_academic')[0].text.strip() job_detail = soup.select('.job_detail')[0].text.strip() job_week = hack_number(soup.select('.job_week')[0].text.strip()) job_time = hack_number(soup.select('.job_time')[0].text.strip()) print(job_name,job_money,job_position,job_academic,job_week,job_time) print(job_detail) #detail_page('https://www.shixiseng.com/intern/inn_1k3vhcwwguaf?pcm=pc_SearchList') #detail_page('https://www.shixiseng.com/intern/inn_uk1lm380lngh?pcm=pc_SearchList') #detail_page('https://www.shixiseng.com/intern/inn_fr1o1nii5knw?pcm=pc_SearchList') for pages in range(1,3): url = f'https://www.shixiseng.com/interns?page={pages}&keyword=Python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E8%B4%B5%E9%98%B3&internExtend=' req = requests.get(url,headers=headers) html = req.text soup = BeautifulSoup(html,'lxml') for item in soup.select('a.title ellipsis font'): detail_url = f"https://www.shixiseng.com{item.get('href')}" detail_page(detail_url)