本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
以下文章来源于上海php自学中心 ,作者汪春波
一、Redis数据库
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。[来自百度百科]
Redis是一个非关系型数据库,是key-value数据结构,每一条数据都是一个键值对。
键的类型是字符串。
值的类型分为五种:
- 字符串 string
- 哈希 hash
- 列表 list
- 集合 set
- 有序集合 zset
redis的默认端口:6479

二、scrapy_redis分布式原理
Scrapy_redis :Redis-based components for Scrapy.
Github地址:https://github.com/rmax/scrapy-redis
安装:
pip install scrapy-redis
scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
- 请求对象的持久化
- 去重的持久化
- 实现分布式
scrapy-redis只是替换了redis的几个组件,不是一个新的框架。
三、 scrapy_redis的原理分析
3.1 回顾scrapy的流程
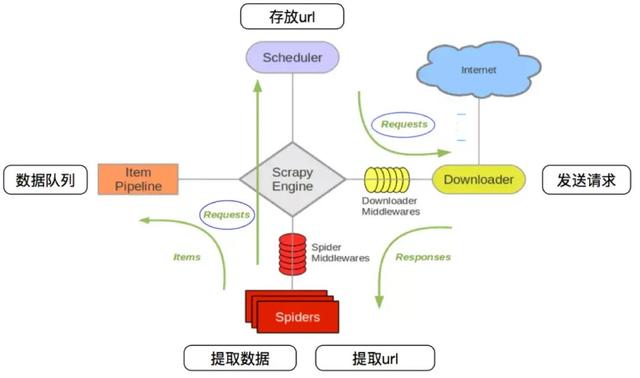
那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫
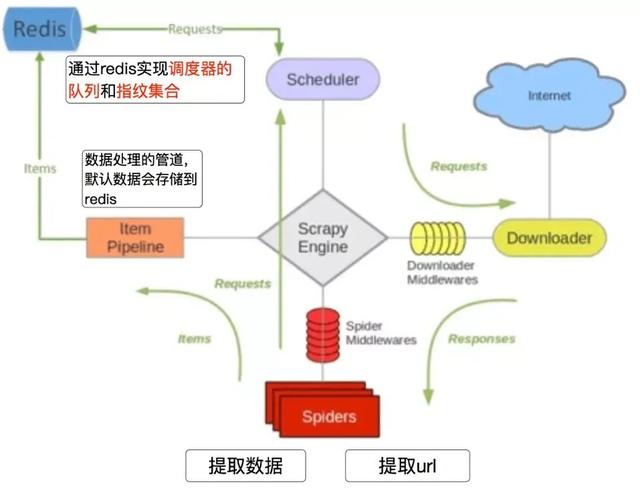
3.2 scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器共用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
具体流程如下:
3.3 Scrapy-Redis分布式策略:
假设有三台电脑:Windows 10、Ubuntu 16.04、Windows 10,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
1、 Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储。
2、 Slaver端(爬虫程序执行端) :使用 Ubuntu 16.04、Windows 10,负责执行爬虫程序,运行过程中提交新的Request给Master。
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
四、scrapy_redis实现分布式爬虫
前面使用scrapy框架获取果壳网问答的问题和高赞答案,如果使用分布式爬虫需要对setting.py以及wenda.py文件进行修改。
在setting.py中修改和添加的内容
# 把scrapy中默认的去重组件替换为scrapy-redis中的去重组件 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 把scrapy中默认的调度器替换成scrapy-redis中的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 任务持久化 SCHEDULER_PERSIST = True # 添加scrapy-redis管道 ITEM_PIPELINES = { # 'guoke.pipelines.GuokePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, } # 添加redis数据库的连接URL # REDIS_URL = 'redis://127.0.0.1:6379' REDIS_HOST = 'localhost' REDIS_PORT = 6379 REDIS_PARAMS = {} REDIS_PARAMS['password'] = '12345'
wenda.py添加的内容
from scrapy_redis.spiders import RedisSpider # class WendaSpider(scrapy.Spider): # 继承RedisSpoder类 class WendaSpider(RedisSpider): name = 'wenda' allowed_domains = ['guokr.com'] #添加redis库,当redis中没有这个键的时候,程序会处于监听等待状态 redis_key = 'python'