本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
以下文章来源于CSDN ,作者嗨学编程
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
最近新上映的电影《花木兰》,评分还是有点低
今天咱们就爬取一下花木兰这个电影评价,看看大家都是怎么评价的

基本环境配置
- python 3.6
- pycharm
- requests
- parsel

pip install requests
pip install parsel
一、分析网页
https://movie.douban.com/subject/26357307/reviews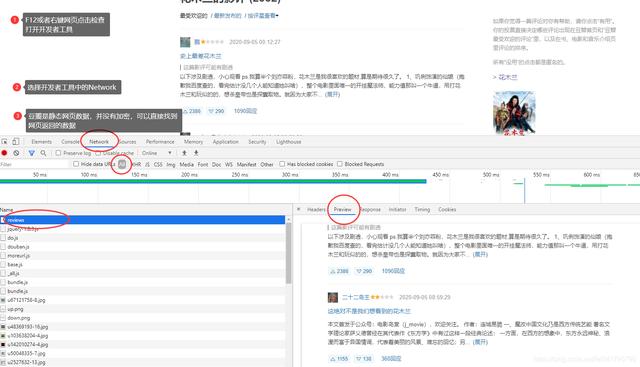
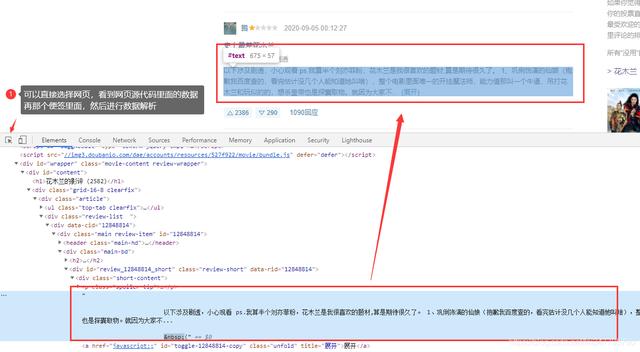
爬虫代码
import requests import parsel url = 'https://movie.douban.com/subject/26357307/reviews' headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Host': 'movie.douban.com', 'Referer': 'https: // movie.douban.com / subject / 26754233 / reviews?start = 140', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', } response = requests.get(url=url, headers=headers) selector = parsel.Selector(response.text) data = selector.css('#content .article .review-list .short-content::text').getall() for i in data: a = i.strip().replace('\n', '').replace(')', '').replace('(', '') with open('花木兰影评' + '.txt', mode='a', encoding='utf-8') as f: f.write(a) f.write('\n') print(a)
实现效果
词云代码
import jieba import wordcloud import imageio # 导入imageio库中的imread函数,并用这个函数读取本地图片,作为词云形状图片 py = imageio.imread(r"G:\python\demo\案例\花木兰豆瓣影评\木兰.png") # 读取文件内容 f = open(r'G:\python\demo\案例\花木兰豆瓣影评\花木兰影评.txt', encoding='utf-8') txt = f.read() # print(txt) # jiabe 分词 分割词汇 txt_list = jieba.lcut(txt) string = ' '.join(txt_list) # 词云图设置 wc = wordcloud.WordCloud( width=1000, # 图片的宽 height=700, # 图片的高 background_color='white', # 图片背景颜色 font_path='msyh.ttc', # 词云字体 mask=py, # 所使用的词云图片 scale=15, stopwords={' ', '没有', '真的', '还是', '就是', '如果', '花木兰', '木兰', '花木', '不是', '什么', '一个', '这部', '但是', '觉得', '有点', '虽然', '我们'}, # contour_width=5, # contour_color='red' # 轮廓颜色 ) # 给词云输入文字 wc.generate(string) # 词云图保存图片地址 wc.to_file(r'G:\python\demo\案例\花木兰豆瓣影评\花木兰.png')

