python爬虫如何学习?汇集众多程序员学习经验总结出的爬虫最适合大多数人的学习路线分享!
爬虫的一周学习计划:
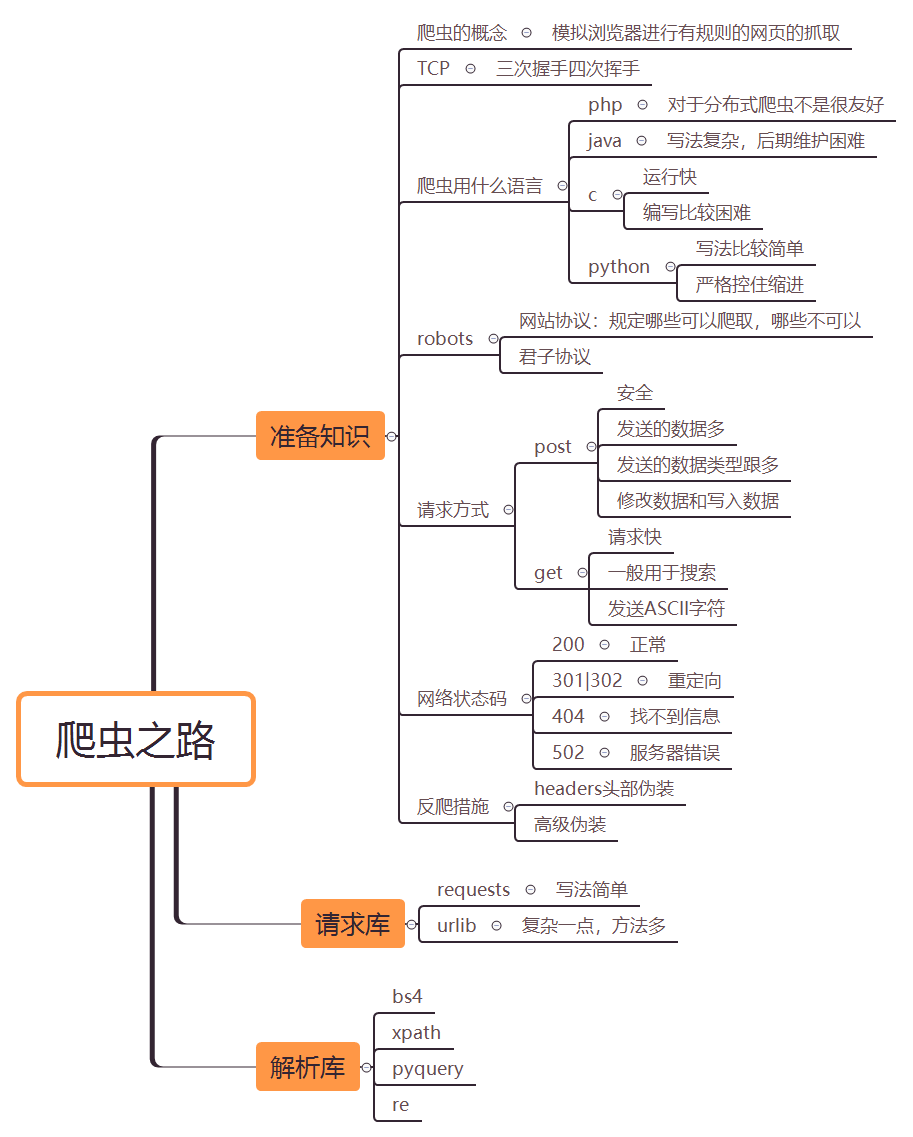
下图是爬虫的准备
爬虫爬取快代理案例:
网站的url=“https://www.kuaidaili.com/free/”
这里多说一句,如果缺少爬虫项目实战案例教程可以加我的python资源交流裙:巴衣久二五寺久寺二(数字的谐音转换下可以找到了),一起交流python资源,裙里还有阿里的大牛,还可以和阿里的大牛一起讨论,学习.
这次爬取我们采用的是requests第三方库
Requests 是一个 Python 的 HTTP 客户端库,我们可以用它得到HTML源码
import requests url="https://www.kuaidaili.com/free/" headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36" } #这里进行了头部的伪装 res=requests.get(url,headers=headers) res.encoding="utf-8" html=res.text
之后我们用xpath实现标签的遍历获取到我们需要的内容
e=etree.HTML(html) ip_list=e.xpath("//tr/td[1]/text()") port_list=e.xpath("//tr/td[2]/text()") #采用zip迭代的方式打印输出 for ip,port in zip(ip_list,port_list): str="ip:"+ip+"\t端口号:"+port print(str)
小结
本文主要讲解了网络爬虫的结构和应用,以及Python实现爬虫的案例。希望大家对本文中的网络爬虫工作流程和Requests实现HTTP请求的方式重点吸收消化。如果有还没有消化的可以进我的python学.习交.流扣.扣裙:巴衣久二五寺久寺二(数字的谐音转换下可以找到了)一起交流讨论,裙里还有2020最新python入门到高级项目实战视频教程和学习资料,进群就可以免费下载.
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。