前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
以下文章来源于爬取你的深度神经网络,作者阿浩
转载地址
https://blog.csdn.net/fei347795790?t=1今天给大家展示Python中正则表达式在爬虫中的应用,并用xlwt模块存入到excel中,掌握这个技能后,就能从一些简单的网站爬取想要的数据信息并存入到自己的数据库中了。


正则表达式基础语法
1.普通字符:
字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是“普通字符”。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
2.简单的转义字符:

3.标准字符集合:
能够与'多种字符' 匹配的表达式
注意区分大小写,大写是相反的意思

4.自定义字符集合:
[ ]方括号匹配方式,能够匹配方括号中任意一个字符

例如:[2-8a-n] 匹配2至8的数和a至n的数
注意:
正则表达式的特殊符号,被包含到中括号中,则失去特殊意义,除了^,-之外
标准字符集合,除小数点外,如果被包含于中括号,自定义字符集合将包含该集合。
比如:[\d.\-+]将匹配:数字(\d)、小数点(.)、+(\+)、-(\-)
5.量词:
修饰匹配次数的特殊符号

例:\d{6} 匹配6个数字的
\d{0,1} 匹配0个数字或者1个数字
注意:
- 匹配次数中的贪婪模式(匹配字符越多越好,默认!)
- 匹配次数中的非贪婪模式(匹配字符越少越好,修饰匹配次数的特殊符号后再加上一个"?"号)
例:
\d{3,6} 匹配3-6个数字的(默认:贪婪式)
\d{3,6}?匹配3-6个数字(非贪婪模式)
6.字符边界
标记匹配的不是字符而是位置,符合某种条件的位置

注:\b匹配这样一个位置:前面的字符和后面的字符不全是\w
7.选择符和分组(常常与8联用)

8.反向引用(\nnn)
每一对()会分配一个编号,使用()的捕获根据左括号的顺序从1开始自动编号。
通过反向引用,可以对分组已捕获的字符串进行引用。
注意:根据左括号为准编号!
例:goto gogo toto dodo todo 只想匹配gogo toto dodo---->([a-z]{2})\1 : 匹配(a-z){2}后再匹配1次
9.预搜索

例:[a-z]+(?=ing) 表示:匹配字母开头,ing结尾的字符(不包括ing)
下面以豆瓣的出版社提供方网站(https://read.douban.com/provider/all)为例进行爬取,爬取所有的出版社网址、出版社名称、出版社logo网址以及在售作品数量。
首先导入需要的模块
from urllib.request import urlopen, Request import re,xlwt,datetime
然后抓取网页源代码内容,这里网站设置了反爬虫机制,因此要模拟浏览器访问,直接爬取会被拦截。这里设置了请求头为浏览器访问模式。
url="https://read.douban.com/provider/all" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}ret = Request(url, headers=headers)html=urlopen(ret).read() #读取网页源代码内容wzgz="<a href=\"/provider/(.*?)\" class=\"provider-item\"><div class=\"col-media\"><div class=\"cm-left avatar\"><div class=\"avatar\"><img src=\"(.*?)\"/></div></div><div class=\"cm-body\"><div class=\"name\">(.*?)</div><div class=\"works-num\">(.*?) 部作品在售</div></div></div></a>" xx=re.compile(wzgz).findall(str(html,"utf-8")) #通过正则表达式匹配在网页源代码中提取所需内容print(xx)
得到如下结果,这是一个包含了每个出版社信息的列表,每个列表元素是一个元组,元组包含了出版社网址参数、出版社名称、出版社logo网址以及在售作品数量等信息:

接下来利用xlwt模块将爬取到的信息存入到excel中。
#创建workbook和sheet对象 workbook = xlwt.Workbook()sheet1 = workbook.add_sheet('sheet1',cell_overwrite_ok=True) #初始化excel样式style = xlwt.XFStyle()#为样式创建字体font = xlwt.Font()font.name = 'Times New Roman' #字体样式 font.bold = True #字体粗细#设置样式的字体style.font = font#在sheet1表的第1行设置字段名称并写入数据 sheet1.write(0,0,"序号",style) sheet1.write(0,1,"出版社-URL",style) sheet1.write(0,2,"LOGO-URL",style) sheet1.write(0,3,"出版社名称",style) sheet1.write(0,4,"在售作品数量",style)
利用for循环将前述爬取的信息存入到设置好的excel中
a=0 #定义行号初始值 h=0 #定义在售数量初始值 for i in xx: #print(str(a+1),i[0]) sheet1.write(a+1,0,a+1,style) #在第a+1行第1列写入序号 sheet1.write(a+1,1,"https://read.douban.com/provider/"+str(i[0]),style) #在第a+1行第2列写入出版社URL sheet1.write(a+1,2,i[1],style) #在第a+1行第3列写入LOGO-URL sheet1.write(a+1,3,i[2],style) #在第a+1行第4列写入出版社名称 sheet1.write(a+1,4,int(i[3]),style) #在第a+1行第5列写入在售数量 h+=int(i[3]) #在售数量累计求和 a+=1 if a==a: #判断XX列表是否遍历结束,并在sheet1表尾行写入在售数量求和的值 t=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") t1=datetime.datetime.now().strftime("%Y%m%d%H%M%S") sheet1.write(a+1,3,"合计",style) #在sheet1表尾行写入“合计” sheet1.write(a+1,4,h,style) #在sheet1表尾行写入在售数量累计值 sheet1.write(a+2,3,"采集时间",style) #在sheet1表尾行写入数据采集时间 sheet1.write(a+2,4,t,style) #在sheet1表尾行写入数据采集时间 workbook.save("D:/python study/week2/"+str(t1)+".xls") #保存该excel文件,有同名文件时无法直接覆盖 print("数据写入excel文件完毕!") print("在售书数量合计:"+str(h))
程序运行结果:

最终得到的Excel文件:
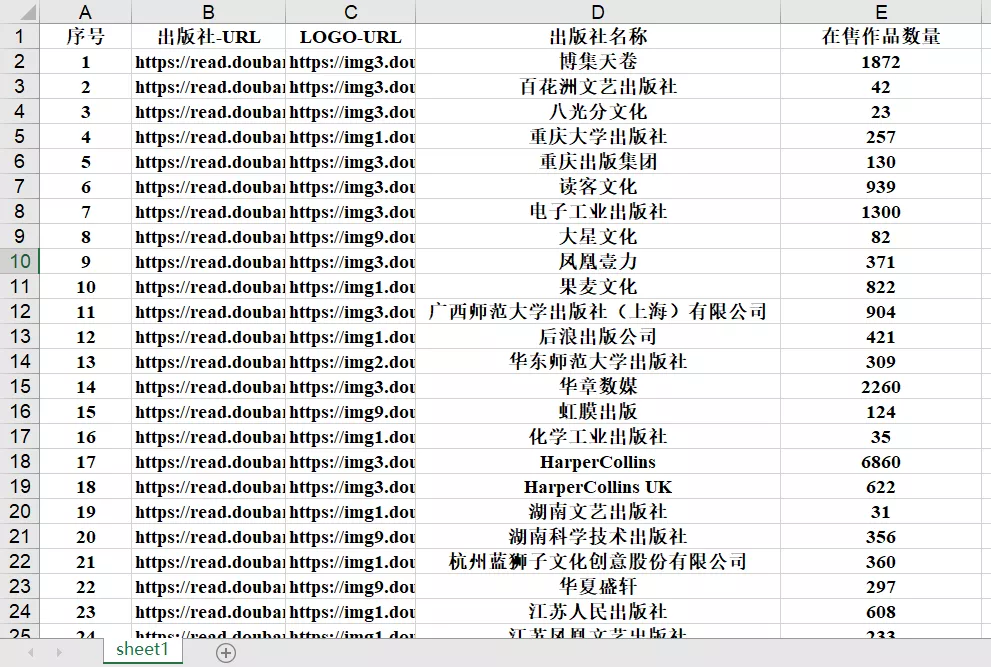
到这里就大功告成啦,快把你的数据用起来吧!