本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。

民以食为天,不知道大家注意到没有最近土豆便宜了!当然,年轻的同学并不关注这些。重点是我们用Python爬取了“北京新发地市场”2020年1月至9月的土豆数据,并进行了分析,效果如图1和图2所示。
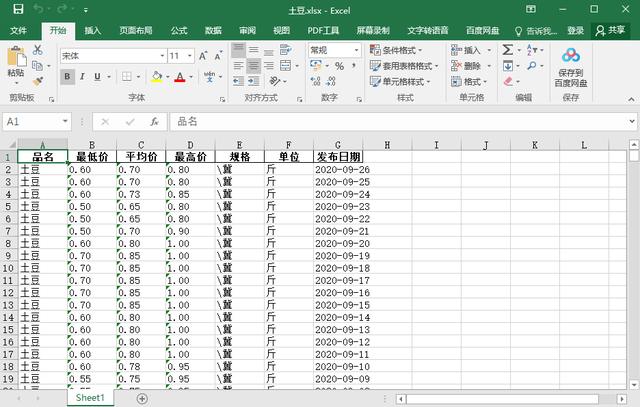
图1 爬取后的数据
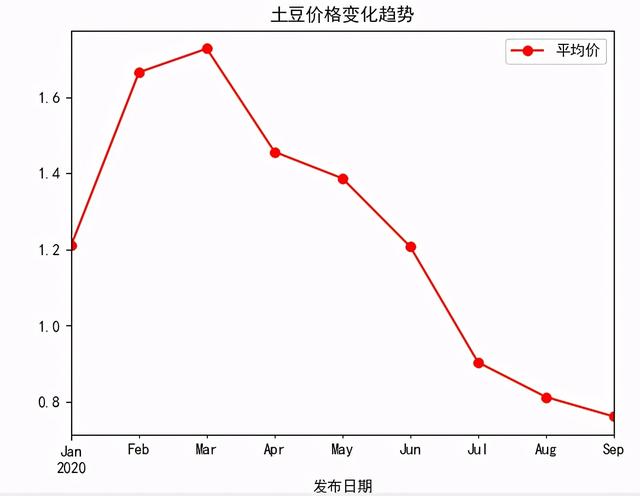
图2 土豆价格变化趋势分析图表
具体实现步骤如下:
用Python实现简单爬取数据可以使用Pandas模块,前提是表格网页数据(即含有表格标签<table>…</table>),右键单击网页中的表格,在弹出的菜单中选择“检查元素”,查看代码中是否含有表格标签<table>…</table>的字样,如图3所示。
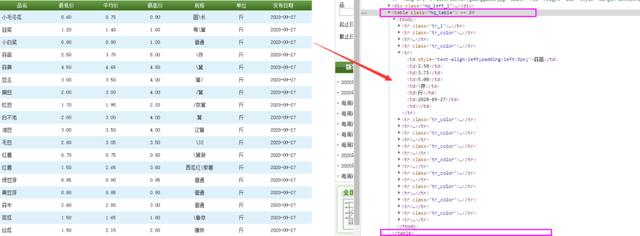
图3 检查元素
确定后在程序中使用Pandas模块的read_html()方法即可轻松实现简单爬虫。
完整程序代码如下:
importpandas as pd import matplotlib.pyplot as plt # 创建空的DataFrame对象 df =pd.DataFrame() # 创建空列表 url_list=[] # 遍历网页的所有页 for i in range(1, 19): url = 'http://www.xinfadi.com.cn/marketanalysis/0/list/'+str(i)+'.shtml?prodname=%E5%9C%9F%E8%B1%86&begintime=2020-01-01&endtime=2020-09-27' url_list.append(url) # 遍历网页中的table读取网页表格数据 for url in url_list: df= df.append(pd.read_html(url)) # 数据清洗删除无用数据第0行和第8列 df.drop(index=0,inplace=True) df.drop(columns=7,inplace=True) df.columns=['品名','最低价','平均价','最高价','规格','单位','发布日期'] # 导出Excel数据 df.to_excel('土豆.xlsx',index=False) # 将平均价转换为浮点类型 df['平均价'] = df['平均价'].astype(float) df['发布日期']=pd.to_datetime(df['发布日期']) df1=df.set_index('发布日期') df_month=df1.resample('M').mean() # 绘制图表 plt.rcParams['font.sans-serif'] = ['SimHei'] df_month.plot(kind='line',marker='o',color='r',title='土豆价格变化趋势') plt.show()
以上通过一个简单的例子介绍了从数据爬取——数据处理——数据可视化——数据分析的一个过程。那么,通过以上方法还可以分析其他蔬菜、水果、粮油等等,感兴趣的小伙伴可以尝试!

以上文章来源于明日IT部落,作者 明日科技
转载地址
https://blog.csdn.net/fei347795790?t=1