前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
目标
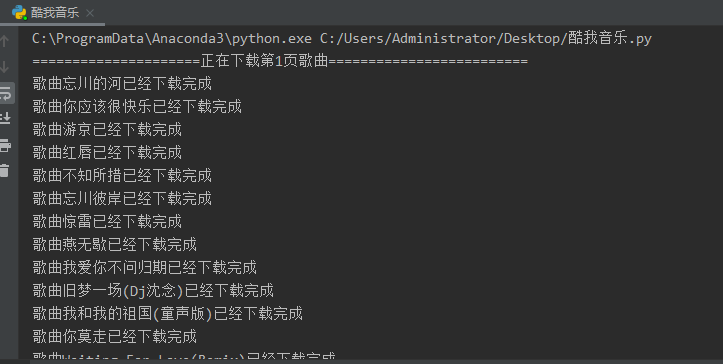
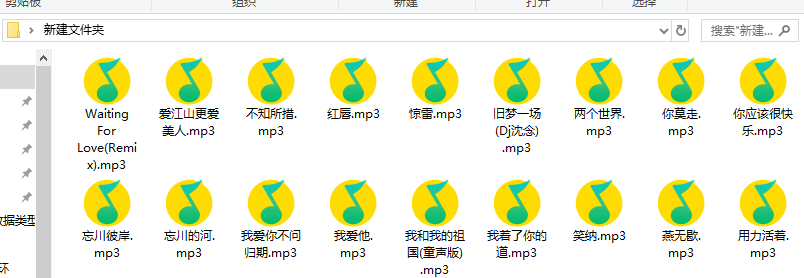
今天来爬酷我音乐
受害者地址
http://www.kuwo.cn/
开发工具
- python 3.6.5
- pycharm
开始爬虫代码
导入模块
import requests
import time解析网页
接口数据参数
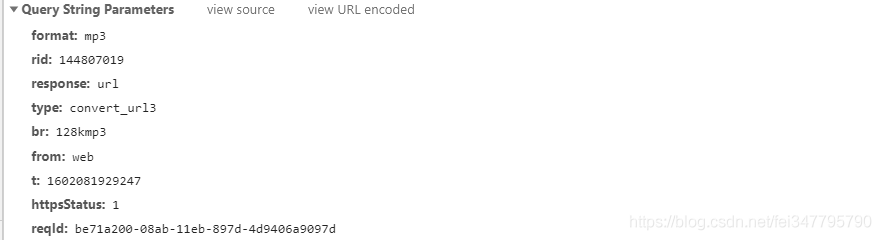
每个歌曲的 rid 、t 、reqld 三个参数是会改变的
- rid:歌曲的id
- t:时间戳
- reqid:不知道啥可以当作不变
获取歌曲真实地址
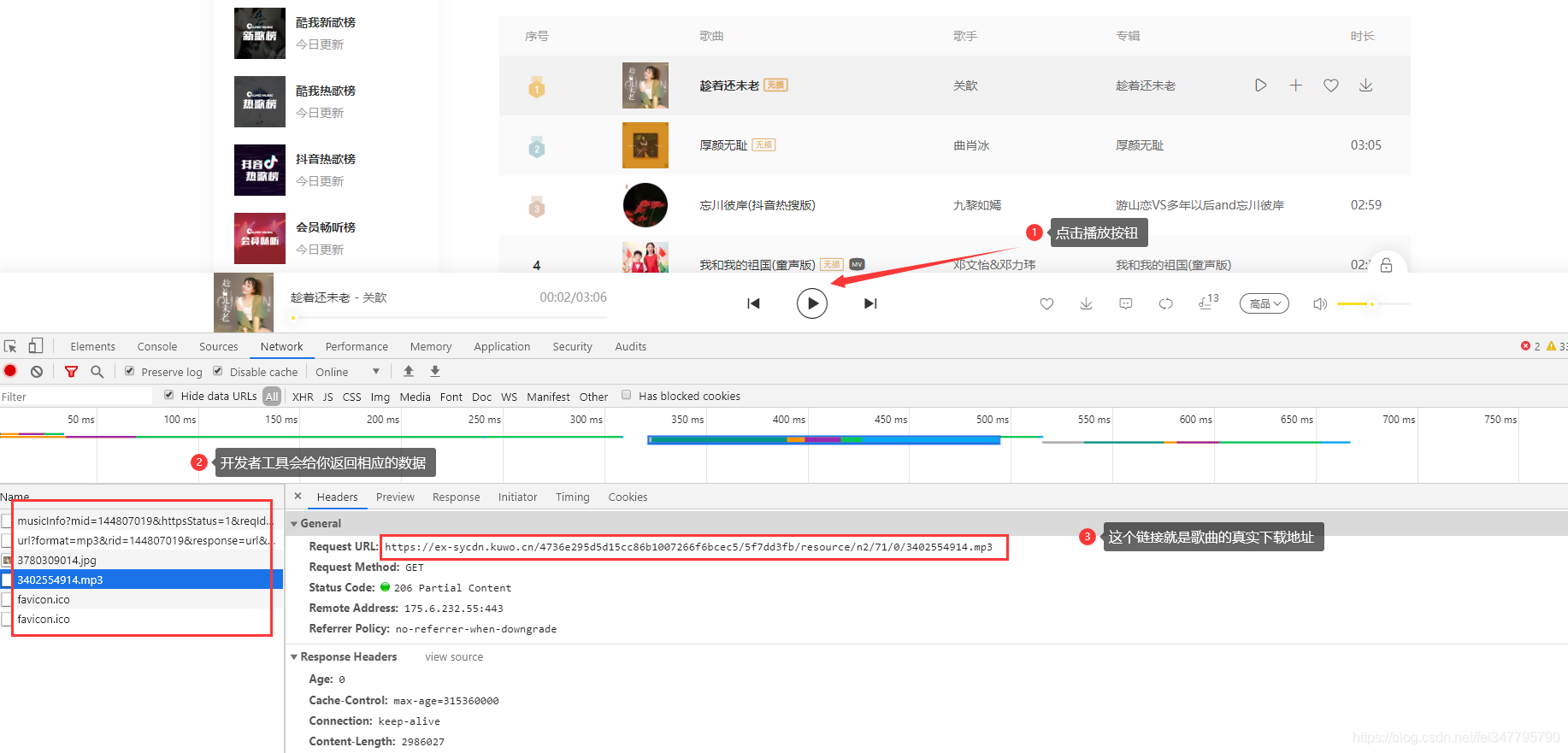
1import requests 2for page in range(1, 11): 3 print('=====================正在下载第{}页歌曲========================='.format(page)) 4 url = 'https://www.kuwo.cn/api/www/bang/bang/musicList?bangId=93&pn={}&rn=30&httpsStatus=1&reqId=d6378280-089a-11eb-84db-b5d33ec180f3'.format(page) 5 response = requests.get(url=url, headers=headers) 6 html_data = response.json() 7 result = html_data['data']['musicList'] 8 9 for i in result: 10 rid = i['rid'] 11 name = i['name']
保存数据
1page_url = 'https://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3&br=128kmp3&from=web&t=1602074319463&httpsStatus=1&reqId=06a89771-089a-11eb-84db-b5d33ec180f3'.format(rid) 2response_2 = requests.get(url=page_url, headers=headers) 3page_data = response_2.json() 4download_url = page_data['url'] 5def download(url, name): 6 filename = 'D:\\python\\demo\\酷我音乐\\音乐\\' + name + '.mp3' 7 response_3 = requests.get(url=url) 8 with open(filename, mode='wb') as f: 9 f.write(response_3.content) 10 print('歌曲{}已经下载完成'.format(name)) 11# 想要完整代码请关注微信公众号:松鼠爱吃饼干 12# 发送信息‘酷我’即可获取