本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者 何以为孤
以下文章来源于
https://blog.csdn.net/weixin_43908900/article/details/97960333 
爬虫之蜂鸟网图片爬取
今天分析一波蜂鸟网,话不多说,先来一波网址
url =“ http://image.fengniao.com/index.php#p=1首先一个美女图片瞧瞧,

分析一波网页,找到网站的分页特点,该网站请求方式为ajax请求,那么各位看官瞧仔细了,F12打开,鼠标轱辘往下翻,你会发现:
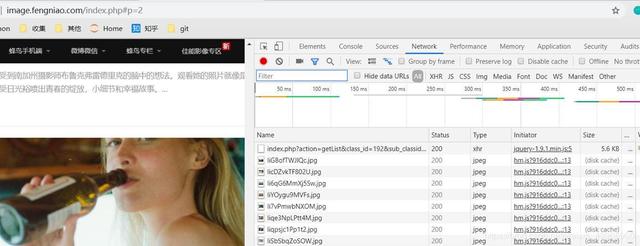
有什么发现么,页数变为2,还有一堆信息,点击右边第一个链接访问,一个新大陆在你眼前:
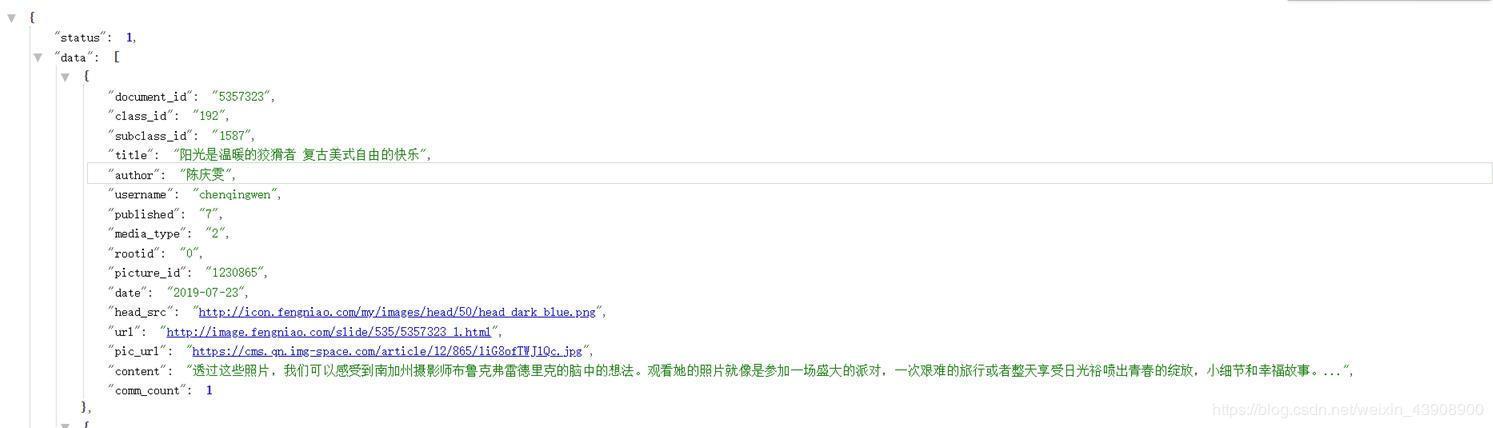
没错,该网页格式返回为json格式,还有一个高大上的名字====》该网站“API”,是不是有点小激动,相信如果学习过这方面知识的小伙伴可以自行发现搓掌敲代码了,好,今天就到此结束了。
你看到这里,小编甚是高兴!那么接下来还是搞事情的节奏,光有数据不行呀,我们需要的是图片。。。。
下面开始上代码:
最好有一些面型对象以及线程的知识,这样对下面代码好理解!
import threading
import time
import json
import re
import requests
import os
imgs_url_list = []
# 图片操作锁
imgs_lock = threading.Lock()
'''继承threading.Thread'''
class Product(threading.Thread):
'''初始化'''
def __init__(self):
super(Product, self).__init__(self)
self.__headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
"Referer": "http://image.fengniao.com/",
"Host": "image.fengniao.com",
"X-Requested-With": "XMLHttpRequest"
}
self.__start = "http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page={}¬_in_id={}"
def run(self):
index = 2 #起始页数
not_in = "5352384,5352410"
while index < 1000:
url = self.__start.format(index,not_in)
# print('开始操作:%s' %url)
print('开始操作:{}'.format(url))
index += 1
content = requests.get(url,headers = self.__headers).text
if content is None:
print('ok,没有你的东西了,客官请回。。。。。')
continue
time.sleep(3)
json_content = json.loads(content)
# print(json_content)
if json_content['status'] == 1:
for item in json_content['data']:
title = item['title']
child_url = item['url']
'''图片链接'''
img_content = requests.get(child_url,headers=self.__headers).text
#这里需要解释一下,为什么设置匹配pic_url_1920_b后面的,你可以自行print=>img_content,自会晓得
pattern = re.compile('"pic_url_1920_b":"(.*?)"')
imgs_json = pattern.findall(img_content)
# print(imgs_json)
if len(imgs_json) > 0:
imgs_lock.acquire()
'''查询的时候方便'''
imgs_url_list.append({'title': title, 'url': imgs_json})
imgs_lock.release()
class Consumer(threading.Thread):
def __init__(self):
super(Product, self).__init__(self)
self.__headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
"Referer": "http://image.fengniao.com/",
"Host": "image.fengniao.com",
"X-Requested-With": "XMLHttpRequest"
}
def run(self):
while True:
if len(img_list) <= 0:
continue # 进入下一次循环
if imgs_lock.acquire():
data = img_list[0]
del img_list[0] # 删除第一项
imgs_lock.release()
# print(data)
'''双\其实是转义后面斜杠,要不会报错'''
urls =[url.replace("\\","") for url in data["url"]]
# print(urls)
# 创建文件目录
os.makedirs('./image/', exist_ok=True)
for item_url in urls:
try:
# print(item_url)
# file = requests.get(item_url,headers = self.__headers,timeout=2)
file = requests.get(item_url)
time.sleep(2)
# print(file.status_code)
# print(item_url)
with open('./image/{}.jpg'.format(str(time.time())),'wb') as f:
f.write(file.content)
except Exception as e:
print(e)
if __name__ == '__main__':
p = Product()
p.start()
c = Consumer()
c.start()