环境准备:
事先安装好,pycharm
打开File——>Settings——>Projext——>Project Interpriter
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:623406465
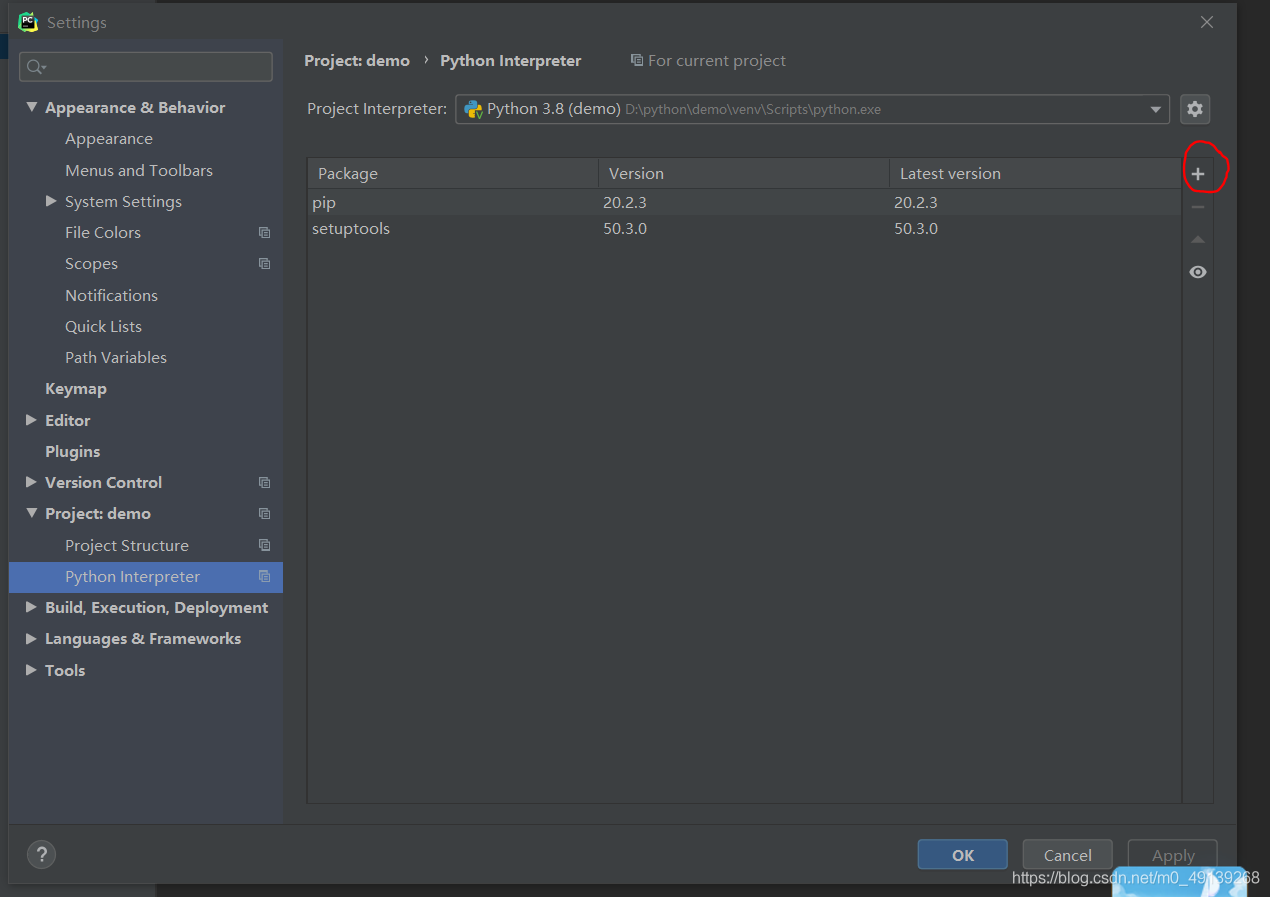
点击加号(图中红圈的地方)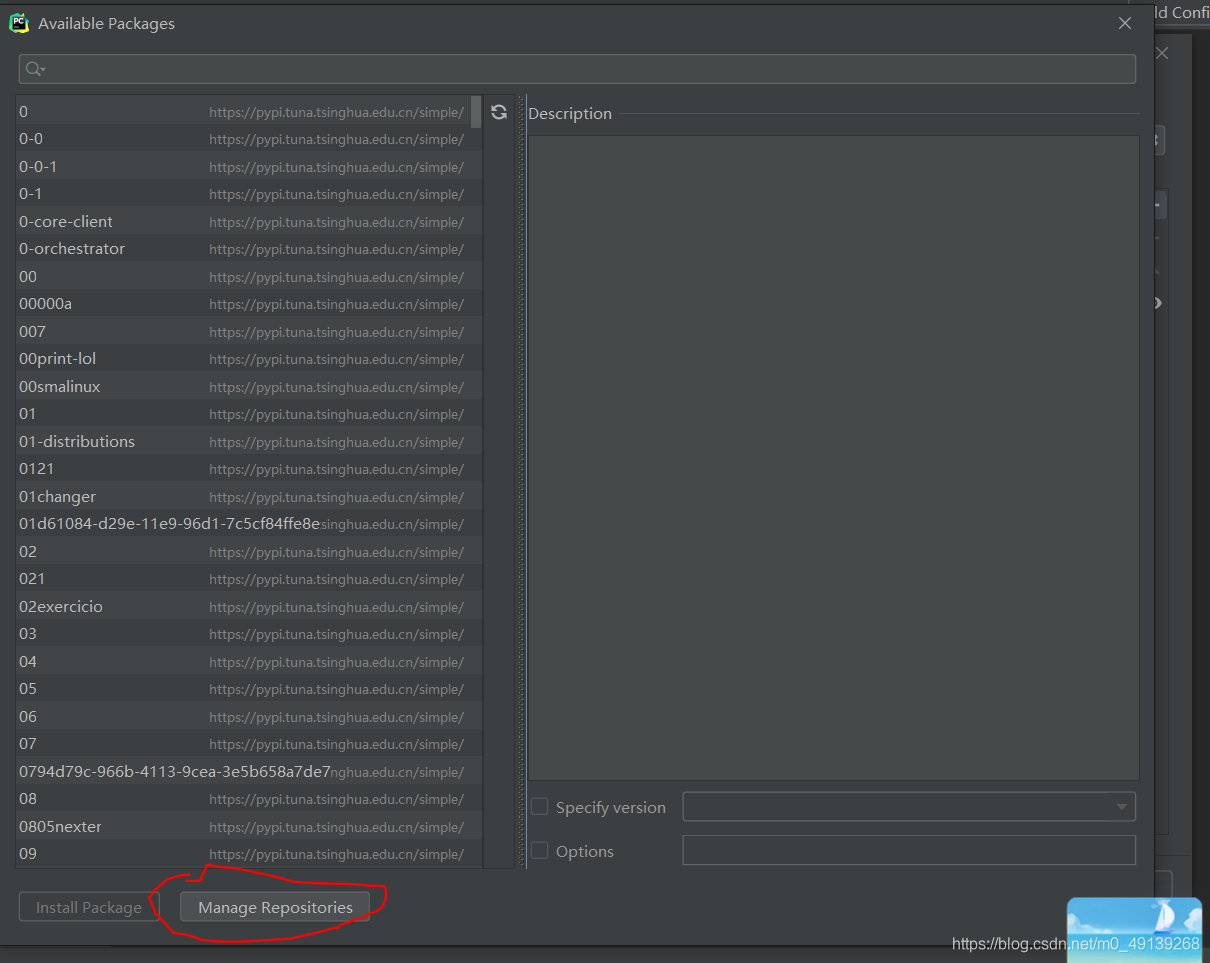
点击红圈中的按钮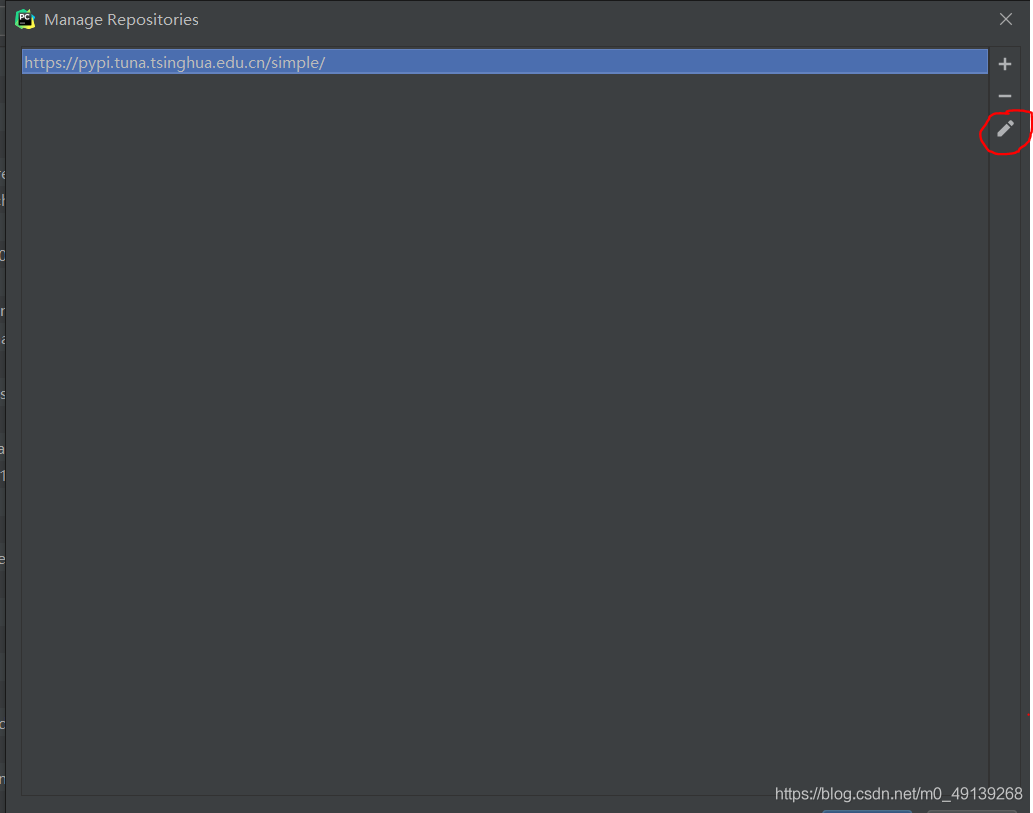
选中第一条,点击铅笔,将原来的链接替换为(这里已经替换过了):
https://pypi.tuna.tsinghua.edu.cn/simple/
点击OK后,输入requests-html然后回车
选中requests-html后点击Install Package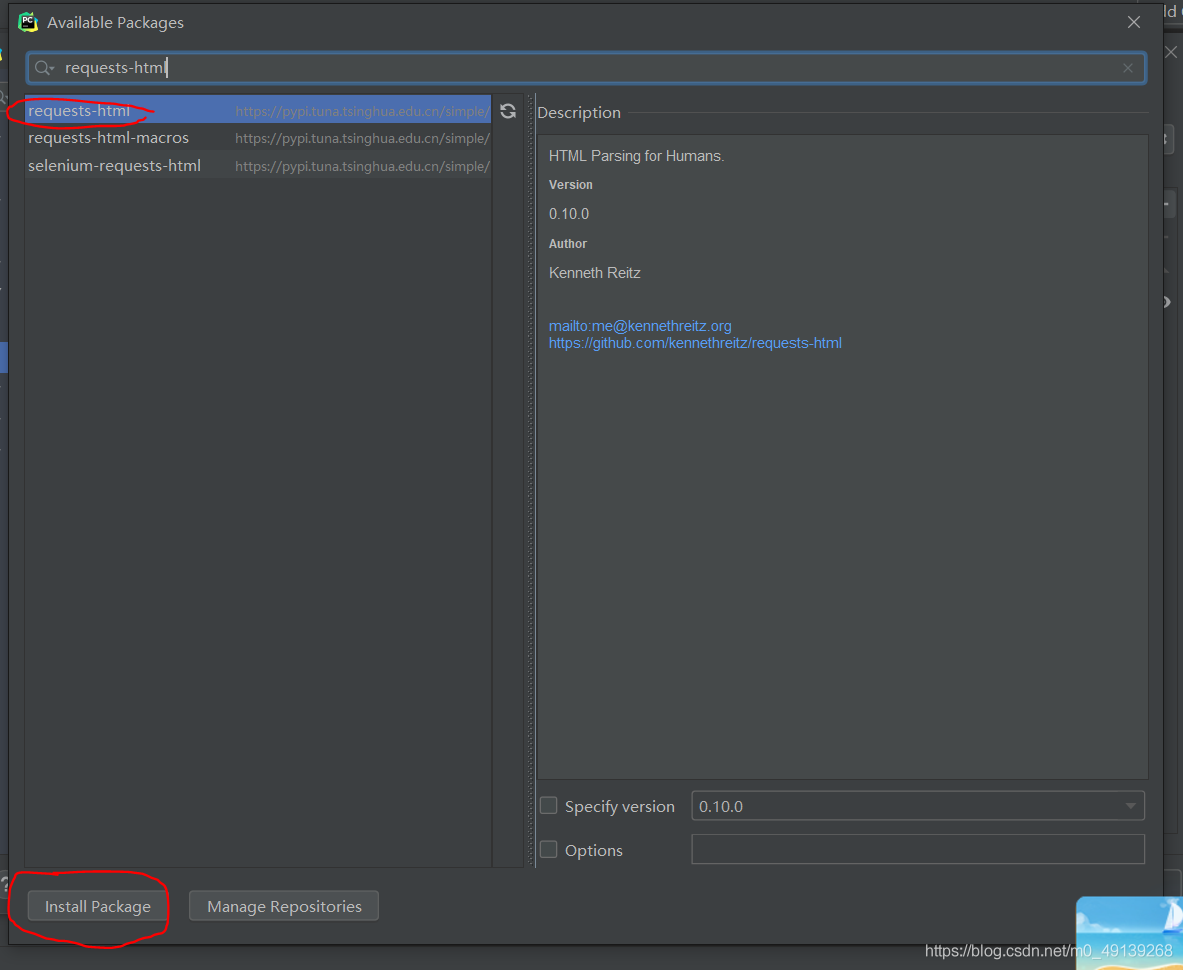
等待安装成功,关闭
通过解析网页源代码
实例内容:
从某博主的所有文章爬取想要的内容。
实例背景:
从(https://me.csdn.net/weixin_44286745)博主的所有文章获取各文章的标题,时间,阅读量。
- 导入requests_html中HTMLSession方法,并创建其对象
from requests_html import HTMLSession
session = HTMLSession()
- 使用get请求获取要爬的网站,得到该网页的源代码。
html = session.get("https://me.csdn.net/weixin_44286745").html
- 找到所有文章
allBlog=html.xpath("//dl[@class='tab_page_list']")
-
进入网站主页(本例: https://me.csdn.net/weixin_44286745)
-
文章空白处右键检查可以定位到这文章的标签
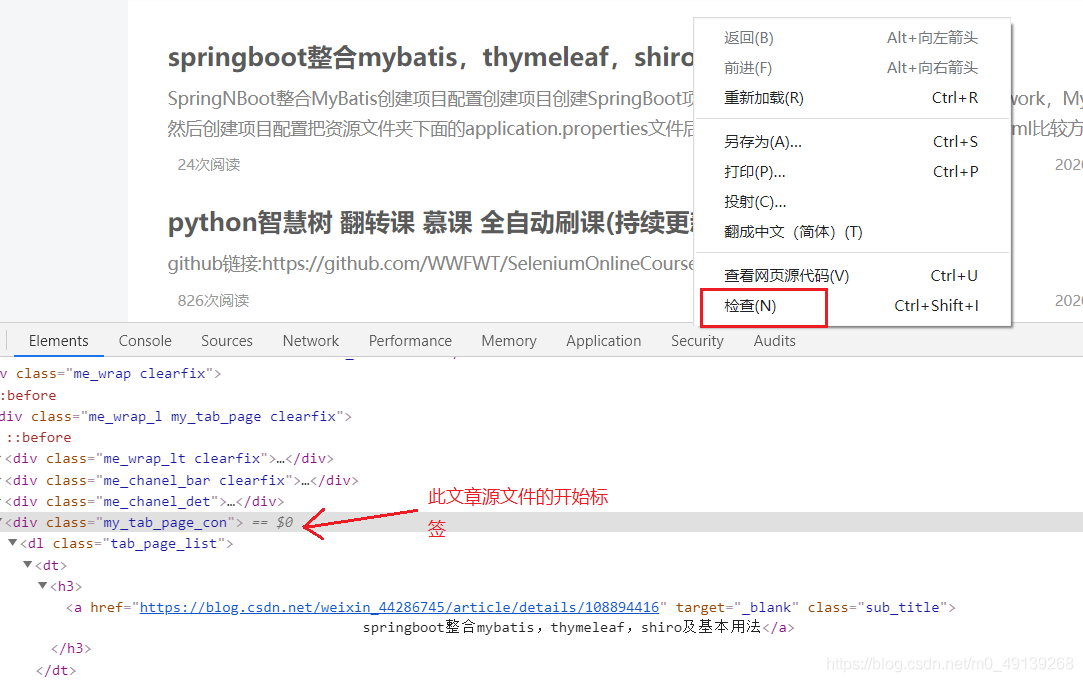
-
其他文章一样操作,然后找到所有文章共同的标记(这里所有文章的class都是‘my_tab_page_con’)
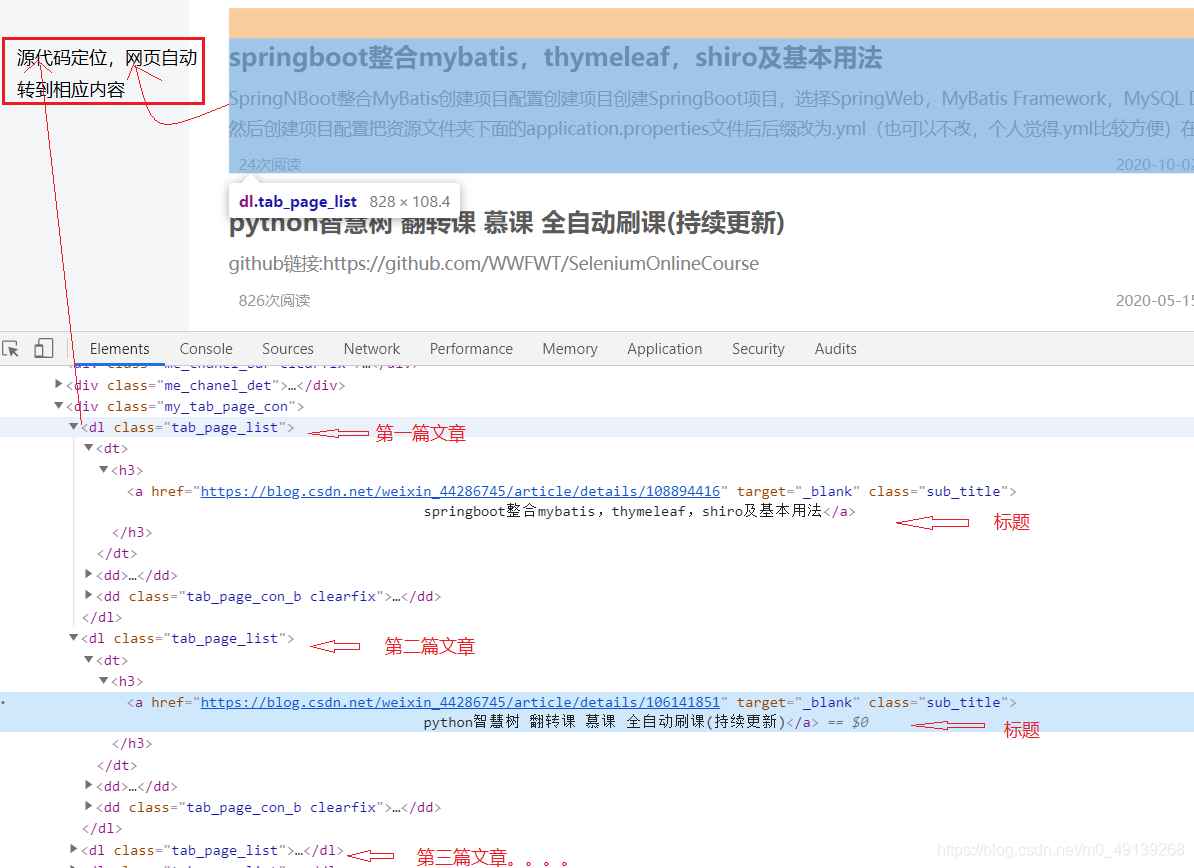
-
xpath 可以遍历html的各个标签和属性,来定位到我们需要的信息的位置,并提取。
-
网页分析获取标题,阅读量,日期。
for i in allBlog:
title = i.xpath("dl/dt/h3/a")[0].text
views = i.xpath("//div[@class='tab_page_b_l fl']")[0].text
date = i.xpath("//div[@class='tab_page_b_r fr']")[0].text
print(title +' ' +views +' ' + date )
网页分析:
-
因为有多篇文章,分别获取使用for循环,上述代码已得到所有文章所以i表示一篇文章
-
第二行代码获取文章标题,于获取文章类似,鼠标放到标题上右键检查,因为文章只有一个标题所以用绝对路径也可以按标签一层层进到标题位置。
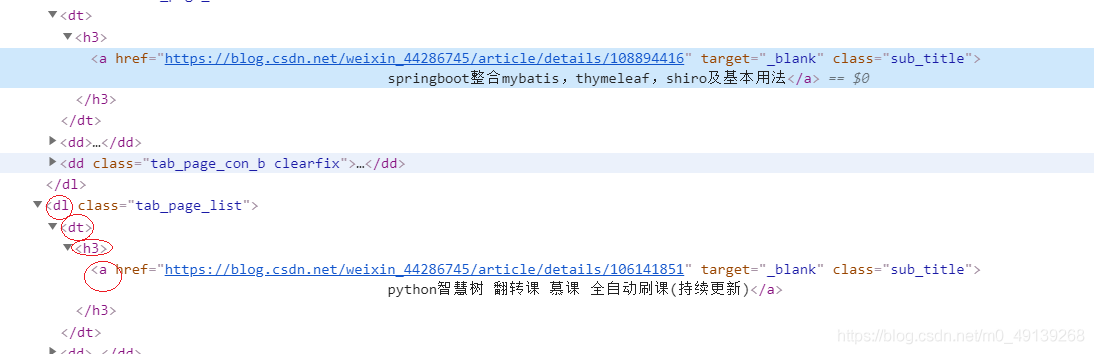
-
xpath返回的是列表,我们要第一个所以要加下标(列表里也只有一个元素),要输出的是文本,所以,text获取文本。
-
阅读量和时间也是重复的操作
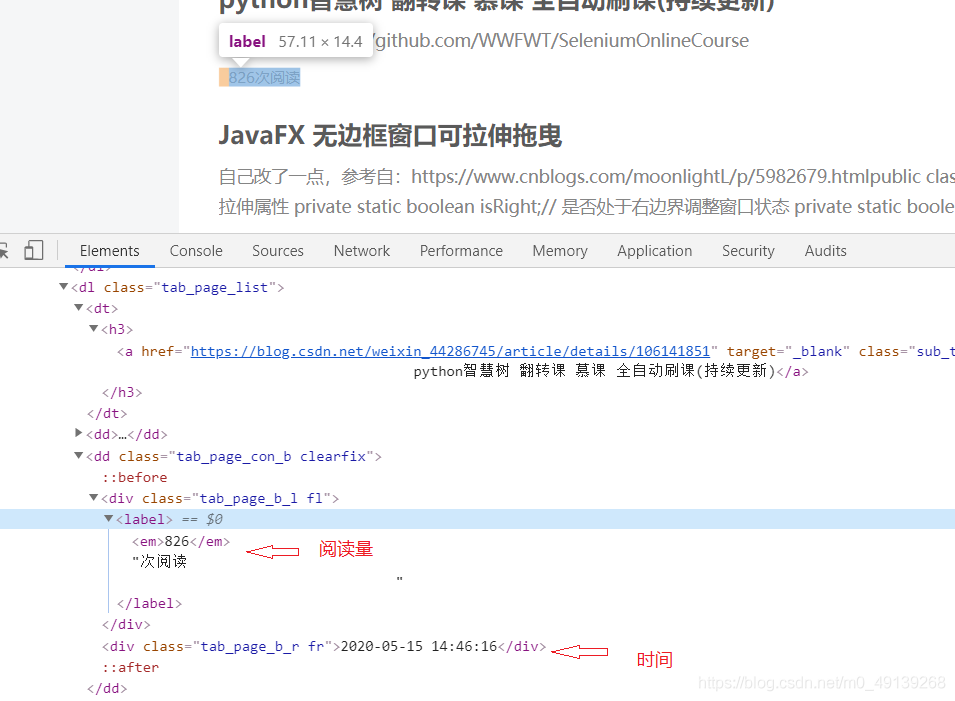
-
可以用相对路径也可以用绝对路径,一般都是用相对路径,格式仿照代码。
-
第五行代码,每得到一篇文章的信息就输出,遍历完就可以获得全部的信息。
完整代码:
from requests_html import HTMLSession
session = HTMLSession()
html = session.get("https://me.csdn.net/weixin_44286745").html
allBlog=html.xpath("//dl[@class='tab_page_list']")
for i in allBlog:
title = i.xpath("dl/dt/h3/a")[0].text
views = i.xpath("//div[@class='tab_page_b_l fl']")[0].text
date = i.xpath("//div[@class='tab_page_b_r fr']")[0].text
print(title +' ' +views +' ' + date )
可以自己爬其他东西,如文章图片,动手试试吧!!!