CSDN个人主页: 高智商白痴
原文地址: https://blog.csdn.net/qq_44700693/article/details/109124334?utm_source=app
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:623406465
日常跳转:
导入
前段时间我已经将B站的爬取方法做了一个总结:Python爬虫:哔哩哔哩(bilibili)视频下载。
这一次,我将继续分享 AcFun 视频网站的解析,其实相对于B站,A站的反爬机制更为简单:
为了能够方便的解析与说明,就肯定会拿一个例子来才好的哇:
【仙女UP特辑】AcFun Family Party ——成都站(今天又是
lsp的一天呢~~)
直接在浏览器端打开并抓包该链接发现,在 XHR 的数据下,第一条(又或者某一次)的请求就加载了视频的真实请求链接: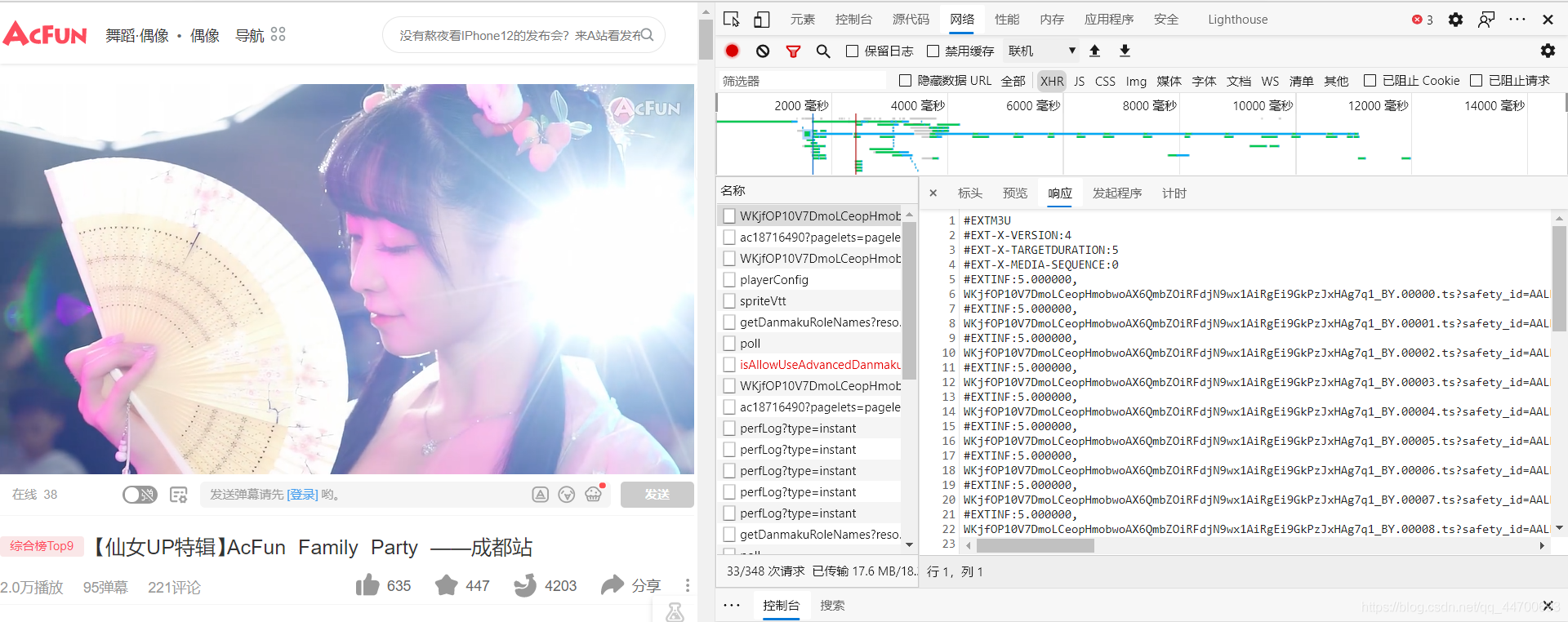
虽然本身仅仅是一个 m3u8 文件,不过我们还是有办法处理的,我们在此之前先必须要找到该文件的亲亲贵是从哪里发出来的,又或者能够在哪里找到这个链接。
在找遍了 XHR 数据无果后,我决定去看一看网页源码:
当我用 m3u8 文件的请求链接在网页源码中搜索后发现,链接就出现在源码中:
因为在源码中是以 JSON 数据存放的:
所以我们需要将数据格式化,方便我们进行数据提取: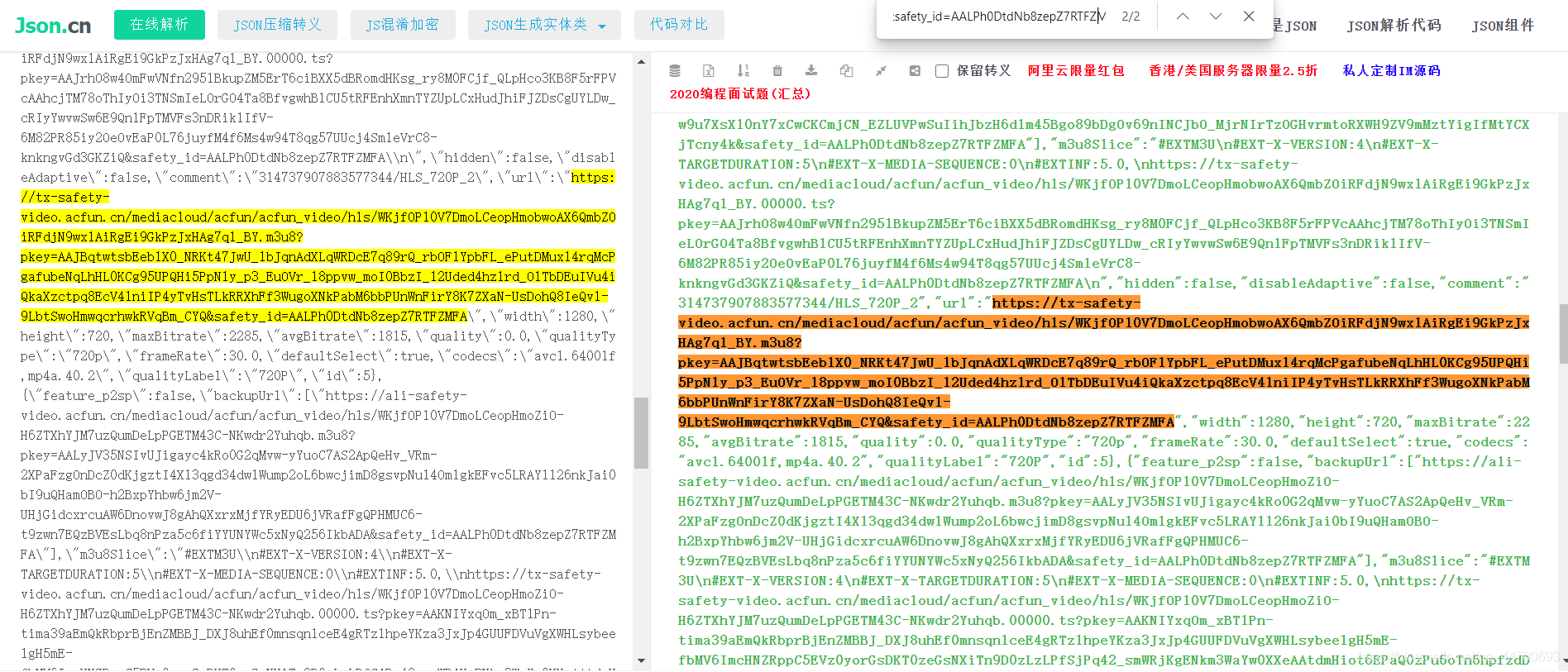
虽然我将该数据格式化以后发现,有一个字段的值居然也是一个 JSON 数据的格式,所以我们再对第二层的 JSON 数据进行格式化后可以看到以下信息: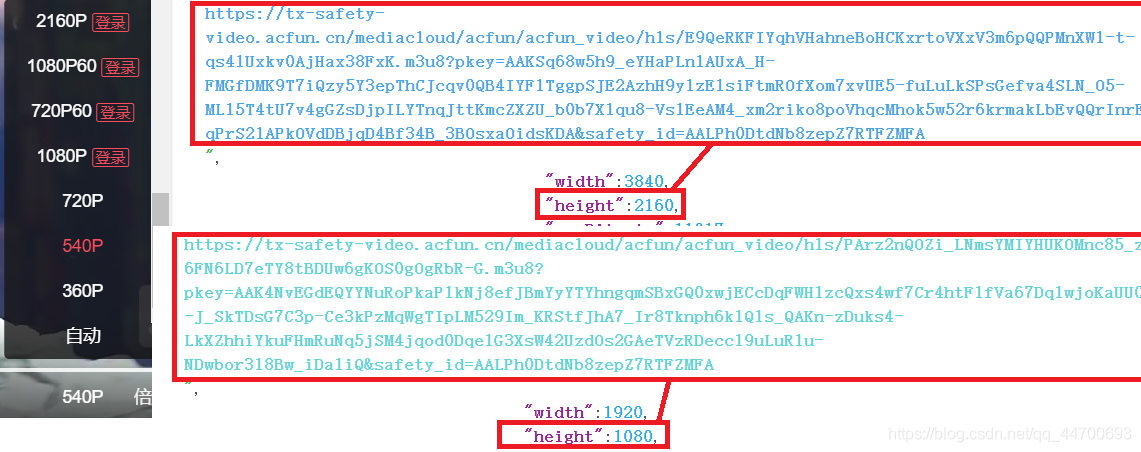
对于未登录时的状态,即使网页端不能直接播放,但是 “ 后台 ” 早已经给我们准备好了播放链接(B站则是加载当前账户或着未登录时能观看的最大清晰度),所以我们可以在未登陆的情况下 白嫖 超高清资源~~
class m3u8_url():
def __init__(self, f_url):
self.url = f_url
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.*? = (.*?)};', html)[0] + '}', strict=False)
name = first_json['title'].strip().replace("|",'')
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0]['representation']
为了后续能够选择清晰度,所以我还进行了清晰度的爬取:
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
print(Label)
choice = int(input("请选择清晰度: "))
到此,我们已经可以拿到视频的 m3u8 文件的地址,那么现在就来开始解决之前遗留的一个小问题:如何通过 m3u8 文件下载视频?
首先,我们拿到一个 m3u8 文件来作为案例:
为了方便,在这里我手动的写了一个 m3u8 文件来作为例子。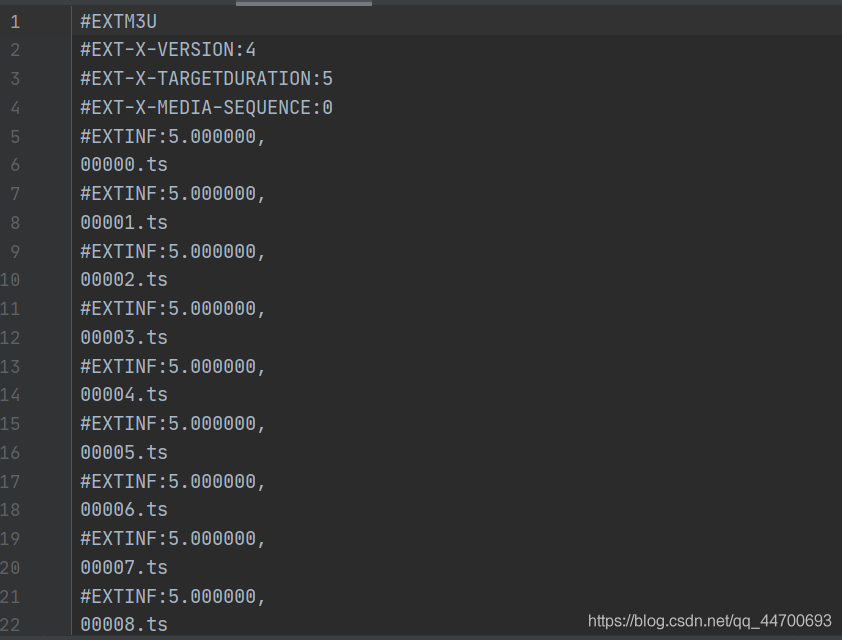
我们知道,在 m3u8 文件中的视频链接都是 .ts 的分段格式,所以我们必须要先想办法将所有的 .ts 链接都拿出来,并且加上前缀,拼装成视频的真实完整的链接:(在这里假设视频原前缀为 https://www.acfun.cn/)
urls=[] # 用于保存视频的分段链接
def get_ts_urls():
with open('123.m3u8',"r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
print("https://www.acfun.cn/"+line)
通过以上方法,我们就可以通过 m3u8 文件来获取每一段的视频链接了,接下来,我们再将下载的功能进行完善:
下载的基本思路还是和我以前的一篇文章的思路一样:Python爬虫:用最普通的方法爬取ts文件并合成为mp4格式
class Download():
urls = [] # 用于保存视频的分段链接
def __init__(self, name, m3u8_url, path):
'''
:param name: 视频名
:param m3u8_url: 视频的 m3u8文件 地址
:param path: 下载地址
'''
self.video_name = name
self.path = path
self.f_url = str(m3u8_url).split('hls/')[0] + 'hls/'
with open(self.path + '/{}.m3u8'.format(self.video_name), 'wb')as f:
f.write(requests.get(m3u8_url, headers={'user-agent': 'Chrome/84.0.4147.135'}).content)
def get_ts_urls(self):
with open(self.path + '/{}.m3u8'.format(self.video_name), "r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
self.urls.append(self.f_url + line.replace('\n', ''))
def start_download(self):
self.get_ts_urls()
for url in tqdm(self.urls, desc="正在下载 {} ".format(self.video_name)):
movie = requests.get(url, headers={'user-agent': 'Chrome/84.0.4147.135'})
with open(self.path + '/{}.flv'.format(self.video_name), 'ab')as f:
f.write(movie.content)
os.remove(self.path + '/{}.m3u8'.format(self.video_name))
代码注解:
- 1、为了最后得到的只有视频,所以在视频下载完后,自动的将当前视频的 m3u8 文件进行了删除操作。
- 2、
line.replace('\n', '')的原因:读取到的 m3u8 文件的每一行结尾都含有一个 " \n "。
终于,到现在我们已经可以整合代码并运行看一看了:
import os
import re
import json
import requests
from tqdm import tqdm
path = './'
headers = {
'referer': 'https://www.acfun.cn/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83'
}
class m3u8_url():
def __init__(self, f_url):
self.url = f_url
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.videoInfo = (.*?)};', html)[0] + '}', strict=False)
name = first_json['title'].strip().replace("|",'')
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0]['representation']
Label = {}
num = 0
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
print(Label)
choice = int(input("请选择清晰度: "))
Download(name + '[{}]'.format(Label[choice]), video_info[choice - 1]['url'], path).start_download()
class Download():
urls = []
def __init__(self, name, m3u8_url, path):
'''
:param name: 视频名
:param m3u8_url: 视频的 m3u8文件 地址
:param path: 下载地址
'''
self.video_name = name
self.path = path
self.f_url = str(m3u8_url).split('hls/')[0] + 'hls/'
with open(self.path + '/{}.m3u8'.format(self.video_name), 'wb')as f:
f.write(requests.get(m3u8_url, headers={'user-agent': 'Chrome/84.0.4147.135'}).content)
def get_ts_urls(self):
with open(self.path + '/{}.m3u8'.format(self.video_name), "r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
self.urls.append(self.f_url + line.replace('\n', ''))
def start_download(self):
self.get_ts_urls()
for url in tqdm(self.urls, desc="正在下载 {} ".format(self.video_name)):
movie = requests.get(url, headers={'user-agent': 'Chrome/84.0.4147.135'})
with open(self.path + '/{}.flv'.format(self.video_name), 'ab')as f:
f.write(movie.content)
os.remove(self.path + '/{}.m3u8'.format(self.video_name))
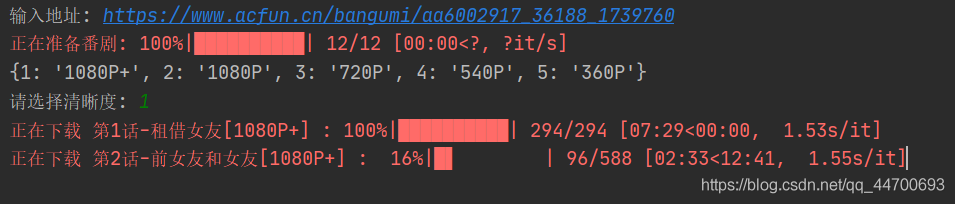
url1 = input("输入地址: ")
m3u8_url(url1).get_m3u8()
效果:
哦豁~ 起飞~~

既然要从番剧入手,那肯定就还是拿一个例子来说明吧:
租借女友 (又是
lsp的呢~~)
针对这部番剧,我们直接从单个视频解析方式来获取经验 -----> 直接从网页源码开始:
果然也在源码中找到了与单个视频类似的 JSON 数据,我们继续将这些数据进行格式化: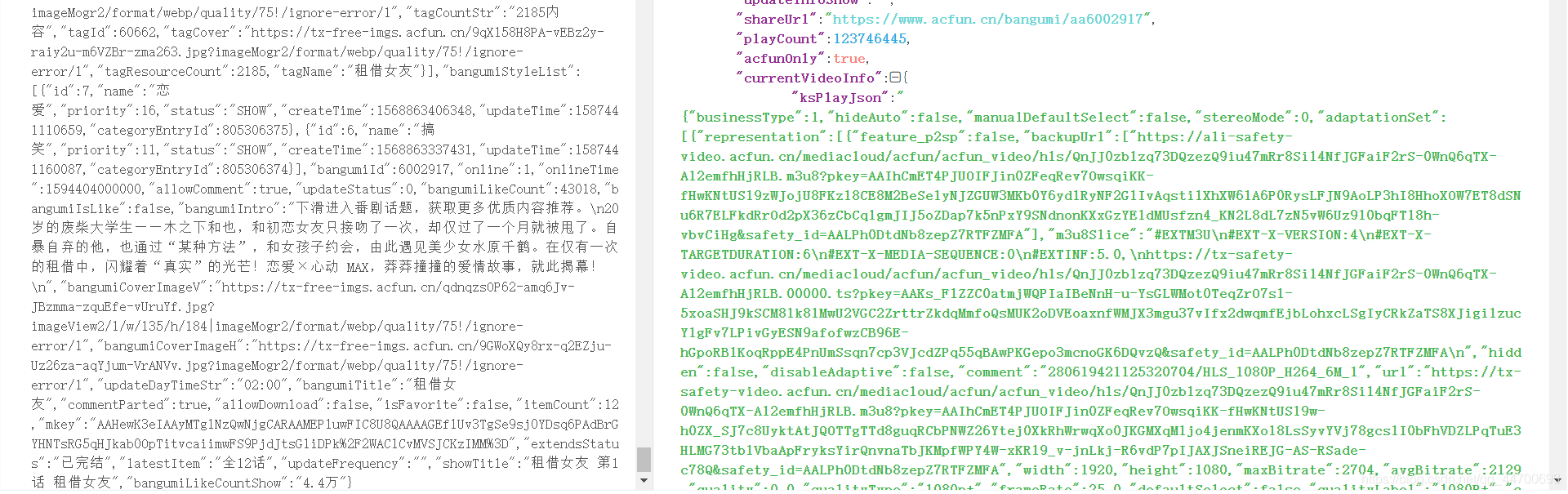
结果视频的 存放方式 和 存放的字段 和单个视频 一摸一样,为了减少最后的代码量,我们可以将两种方式都适配到一个类中:
class m3u8_url():
def __init__(self, f_url, name=""):
'''
:param f_url: 当前视频的链接
:param name: 番剧名,默认为空
'''
self.url = f_url
self.name = name
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.*? = (.*?)};', html)[0] + '}', strict=False)
if self.name == '':
name = first_json['title'].strip().replace("|",'')
else:
name = self.name
rel_path = path + first_json['bangumiTitle'].strip()
if os.path.exists(rel_path):
pass
else:
os.makedirs(rel_path)
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0]['representation']
Label = {}
num = 0
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
if flag:
print(Label)
choice = int(input("请选择清晰度: "))
flag = False
qua = choice
Download(name + '[{}]'.format(Label[choice]), video_info[choice - 1]['url'], path).start_download()
else:
Download(name + '[{}]'.format(Label[qua]), video_info[qua - 1]['url'], rel_path).start_download()
代码注解:
- flag :用于判断是否已经选择了下载时的清晰度。
- qua : 保存选择的清晰度。
- rel_path :更改番剧下载的位置(番剧名的文件夹下)。
- first_json = json.loads(re.findall(‘window.pageInfo = window.? = (.?)};’, html)[0] + ‘}’, strict=False) :更改视频信息的匹配正则表达式,可以同时用来匹配单个视频和番剧视频。
知道了某一集怎么下载,总不可能要每一集都要去手动输入链接吧!!!遇到只有几集的番剧还好,要是遇到这样的:
你来???
同样的,我们还是从网页源码出发: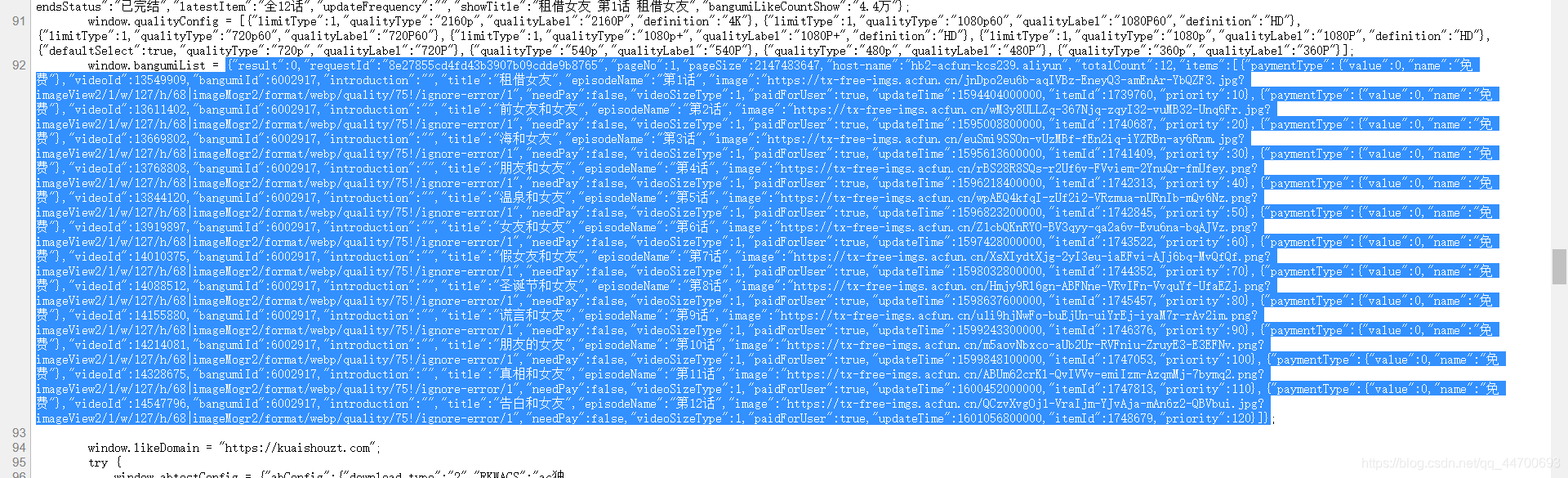
虽然我们能在源码中找到番剧的所有信息,但是,并不是所有的都是我们需要的,我们还要先去看看哪些信息是我们必须要拿到的:
当我点击第二集时,浏览器地址栏的地址发生了变化:
我们很容易的就可以发现:
- https://www.acfun.cn/bangumi/aa6002917 :番剧的主页链接。
- 36188 :一串不知道有什么用的数字,不过我发现它并没有什么用,都是固定的:
举几个例子:
租借女友 :第2话 前女友和女友:https://www.acfun.cn/bangumi/aa6002917_36188_1740687
租借女友 :第3话 海和女友:https://www.acfun.cn/bangumi/aa6002917_36188_1741409
镇魂街 :第2话:https://www.acfun.cn/bangumi/aa5020166_36188_232386
…
同样的点回第一集时也可以看到第一集的链接也可以写成:
镇魂街 :第1话:https://www.acfun.cn/bangumi/aa5020166_36188_232383
租借女友 :第1话 租借女友:https://www.acfun.cn/bangumi/aa6002917_36188_1739760
…
- 1740687 :每一集的 ID ,在源码中以 itemId 字段保存。
于是,我们就可以写出获取每一集视频链接的代码:
class Pan_drama():
def __init__(self, f_url):
'''
:param f_url: 视频主页的链接
'''
self.aa = len(str(f_url).split('/')[-1])
if self.aa == 7:
self.url = f_url
elif self.aa > 7:
self.url = str(f_url).split('_')[0]
def get_info(self):
video_info = {}
html = requests.get(self.url, headers=headers).text
all_item = json.loads(re.findall('window.bangumiList = (.*?);', html)[0])['items']
for item in tqdm(all_item, desc="正在准备番剧"):
video_info[item['episodeName'] + '-' + item['title']] = self.url + '_36188_' + str(item['itemId'])
for name in video_info.keys():
m3u8_url(video_info[name],name).get_m3u8()
代码注解:
- self.aa :为了更好的适应性,简单的解决一下,传入某一集的链接,但是可以下载全番剧的情况。
全部源码:
import os
import re
import json
import requests
from tqdm import tqdm
path = './'
headers = {
'referer': 'https://www.acfun.cn/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83'
}
flag = True
qua = 0
class m3u8_url():
def __init__(self, f_url, name=""):
'''
:param f_url: 当前视频的链接
:param name: 番剧名,默认为空
'''
self.url = f_url
self.name = name
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.*? = (.*?)};', html)[0] + '}', strict=False)
if self.name == '':
name = first_json['title'].strip().replace("|", '')
rel_path=path
else:
name = self.name
rel_path = path + first_json['bangumiTitle'].strip()
if os.path.exists(rel_path):
pass
else:
os.makedirs(rel_path)
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0][
'representation']
Label = {}
num = 0
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
if flag:
print(Label)
choice = int(input("请选择清晰度: "))
flag = False
qua = choice
Download(name + '[{}]'.format(Label[choice]), video_info[choice - 1]['url'], rel_path).start_download()
else:
Download(name + '[{}]'.format(Label[qua]), video_info[qua - 1]['url'], rel_path).start_download()
class Pan_drama():
def __init__(self, f_url):
'''
:param f_url: 视频主页的链接
'''
self.aa = len(str(f_url).split('/')[-1])
if self.aa == 7:
self.url = f_url
elif self.aa > 7:
self.url = str(f_url).split('_')[0]
def get_info(self):
video_info = {}
html = requests.get(self.url, headers=headers).text
all_item = json.loads(re.findall('window.bangumiList = (.*?);', html)[0])['items']
for item in tqdm(all_item, desc="正在准备番剧"):
video_info[item['episodeName'] + '-' + item['title']] = self.url + '_36188_' + str(item['itemId'])
for name in video_info.keys():
m3u8_url(video_info[name],name).get_m3u8()
class Download():
urls = []
def __init__(self, name, m3u8_url, path):
'''
:param name: 视频名
:param m3u8_url: 视频的 m3u8文件 地址
:param path: 下载地址
'''
self.video_name = name
self.path = path
self.f_url = str(m3u8_url).split('hls/')[0] + 'hls/'
with open(self.path + '/{}.m3u8'.format(self.video_name), 'wb')as f:
f.write(requests.get(m3u8_url, headers={'user-agent': 'Chrome/84.0.4147.135'}).content)
def get_ts_urls(self):
with open(self.path + '/{}.m3u8'.format(self.video_name), "r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
self.urls.append(self.f_url + line.replace('\n', ''))
def start_download(self):
self.get_ts_urls()
for url in tqdm(self.urls, desc="正在下载 {} ".format(self.video_name)):
movie = requests.get(url, headers={'user-agent': 'Chrome/84.0.4147.135'})
with open(self.path + '/{}.flv'.format(self.video_name), 'ab')as f:
f.write(movie.content)
os.remove(self.path + '/{}.m3u8'.format(self.video_name))
url1 = input("输入地址: ")
if url1.split('/')[3] == 'v':
m3u8_url(url1).get_m3u8()
elif url1.split('/')[3] == 'bangumi':
Pan_drama(url1).get_info()
效果示例: