爬虫遇到验证码应该怎么解决?Python反反爬教学
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理

一 前言
中国知网的注册页面使用的是这种验证码,页面如下:
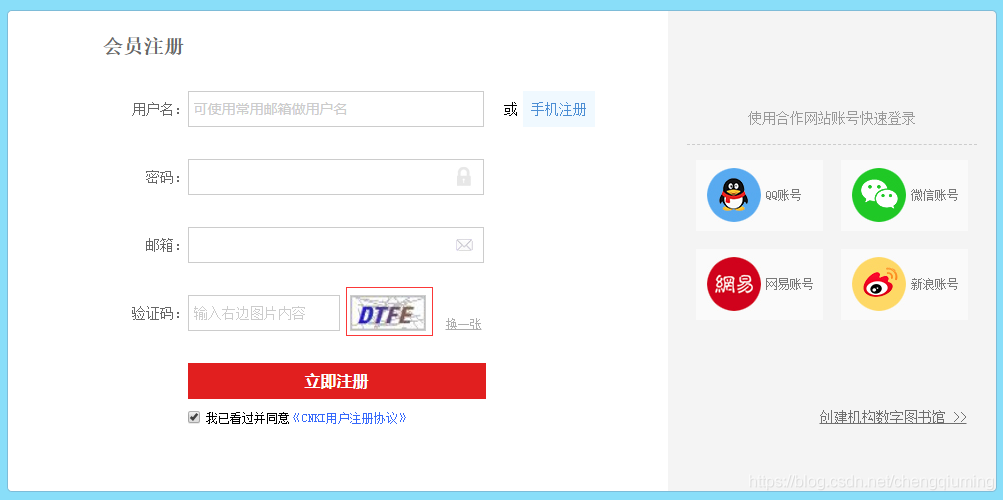
二 准备工作
1 目标
以知网的验证码为例,利用OCR(Optical Character Recognition 光学字符识别)技术识别图形验证码。
2 安装tesseract
2.2 下载tesseract-ocr-setup-3.05.01.exe
2.3 安装注意事项
勾选Additional language data(download)选项,这样可以识别多国语言。
3 安装tesserocr
pip install tesserocr pillow
安装好的Tesseract-OCR后,从D:\Program Files (x86)\Tesseract-OCR目录下,将tessdata文件夹拷贝到下面目录
E:\WebSpider\venv\Scripts
4 获取验证码
将验证码图形 保存到本地,命名为code.jpg

三 实战
1 实战
1.1 代码
import tesserocr
from PIL import Image
image = Image.open('code.jpg')
result = tesserocr.image_to_text(image)
print(result)
image = Image.open('code1.jpg')
result = tesserocr.image_to_text(image)
print(result)
image = Image.open('code2.jpg')
result = tesserocr.image_to_text(image)
print(result)
1.2 效果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/8_1.py
DTKD
JR42
PFRT
1.3 说明
code.jpg是DTKT
code1.jpg是JR42
code2.jpg是PFRT
将结果和实际图片进行比较,正确率还是比较高的。
2 实战2
2.1 代码
import tesserocr
print(tesserocr.file_to_text('code.jpg'))
print(tesserocr.file_to_text('code1.jpg'))
print(tesserocr.file_to_text('code2.jpg'))
2.2 效果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/8_1.py
DTKD
.ll?42
FFKT
2.3 说明
code.jpg是DTKT
code1.jpg是JR42
code2.jpg是PFRT
将结果和实际图片进行比较,正确率并不是很高。
3 实战3
3.1 代码
import tesserocr
from PIL import Image
image = Image.open('code2.jpg')
image = image.convert('L')
threshold = 127
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '1')
image.show()
result = tesserocr.image_to_text(image)
print(result)
3.2 效果
E:\WebSpider\venv\Scripts\python.exe E:/WebSpider/8_1.py
PFRT