前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本次目标
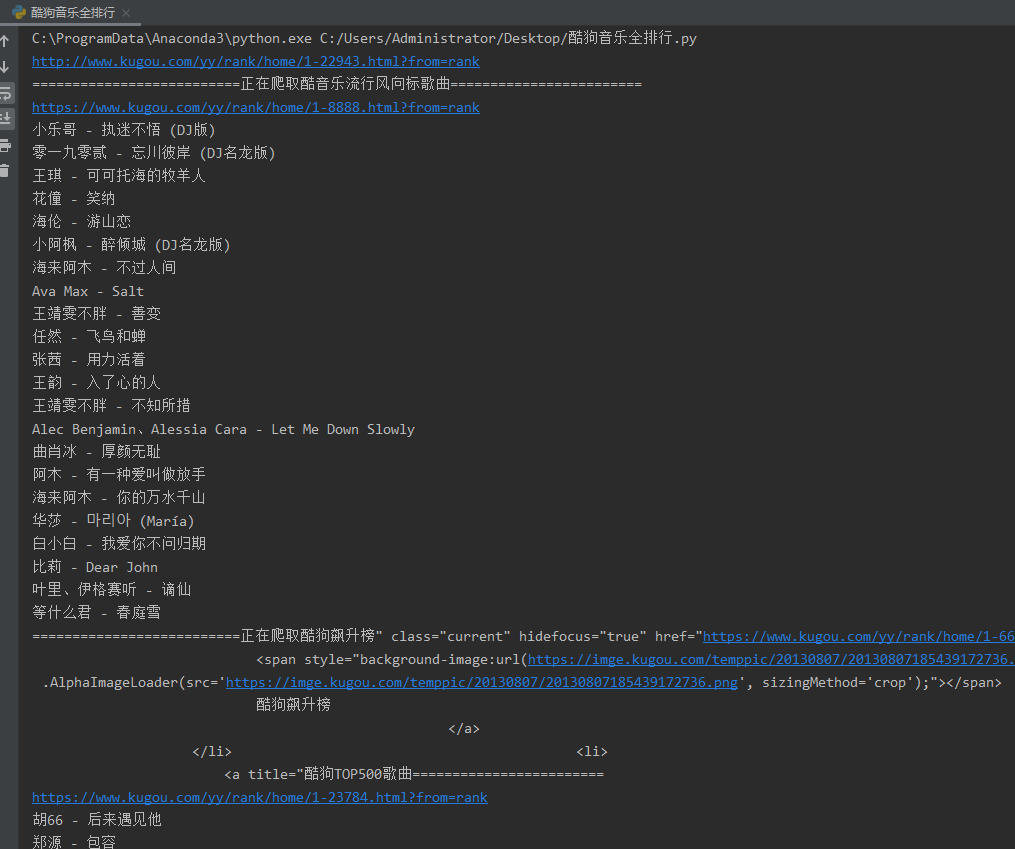
爬取酷狗音乐全站排行榜歌曲

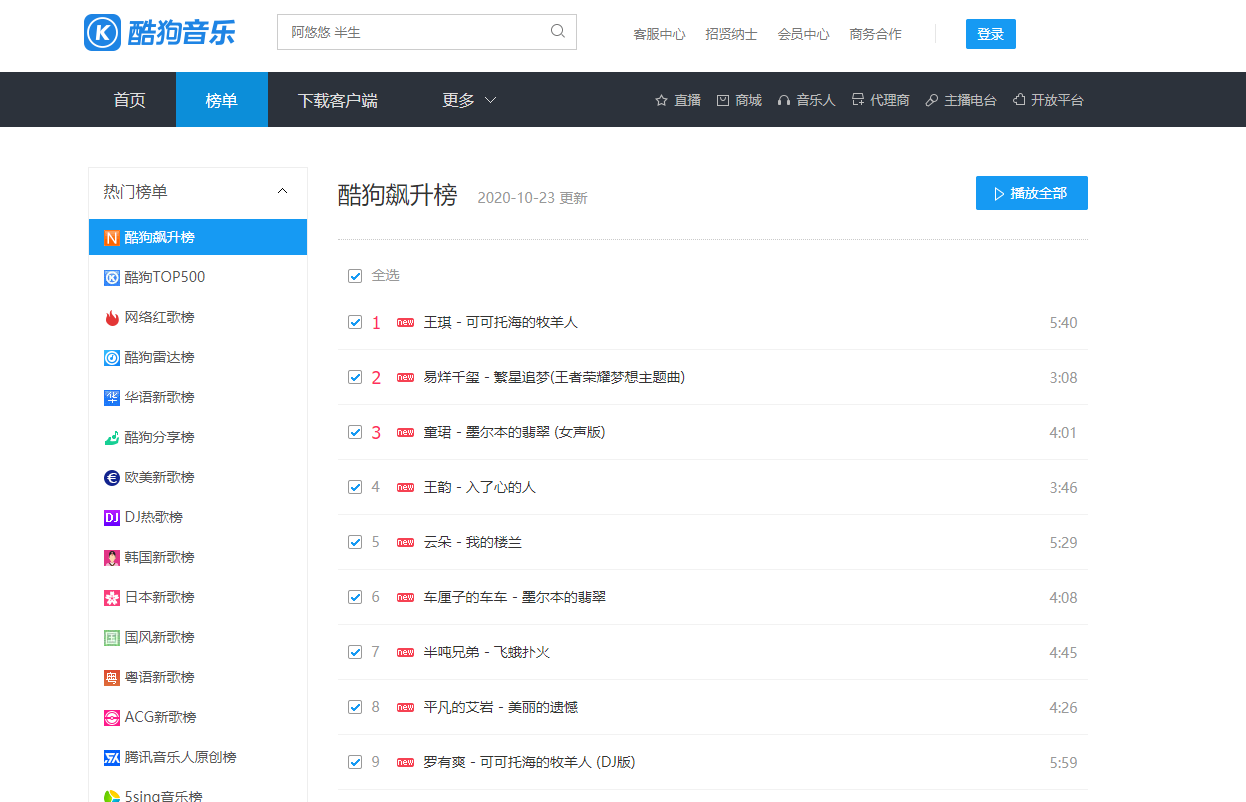
目标地址
https://www.kugou.com/yy/html/rank.html?from=homepage
环境
Python3.6.5
pycharm

爬虫代码
调入工具
import requests import re import parsel
请求网站
headers = { 'authority': 'wwwapi.kugou.com', 'cookie': 'kg_mid=ac3836df72c523f46a85d8a5fd90fe59; kg_dfid=3ve7aQ2XyGmN0yE3uv3WcaHs; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600260110,1602312707; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; kg_mid_temp=ac3836df72c523f46a85d8a5fd90fe59; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1602312738', 'referer': 'https://www.kugou.com/song/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', } url = 'https://www.kugou.com/yy/html/rank.html' response = requests.get(url=url, headers=headers)
解析网站数据
def func(url): response = requests.get(url=url, headers=headers) response.encode = response.apparent_encoding hashs = re.findall('"Hash":"(.*?)"', response.text, re.S) album_ids = re.findall('"album_id":(.*?),"', response.text, re.S) FileNames = re.findall('"FileName":"(.*?)"', response.text, re.S) data = zip(hashs, album_ids, FileNames) for i in data: hash = i[0] album_ids = i[1] FileName = i[2].encode('utf-8').decode('unicode_escape') # print(hash, album_ids, FileName) download_url = 'https://wwwapi.kugou.com/yy/index.php' params = { 'r': 'play/getdata', 'callback': 'jQuery19107150201841602037_1602314563329', 'hash': '{}'.format(hash), 'album_id': '{}'.format(album_ids), 'dfid': '3ve7aQ2XyGmN0yE3uv3WcaHs', 'mid': 'ac3836df72c523f46a85d8a5fd90fe59', 'platid': '4', '_': '1602312793005', } for i in html_data: page_url = i[0] name = i[1] print(page_url) func(page_url) print('==========================正在爬取{}歌曲========================'.format(name))
保存数据
def download(url, title): filename = '保存地址' + title + '.mp3' response = requests.get(url=url, headers=headers) with open(filename, mode='wb') as f: f.write(response.content) print(title)
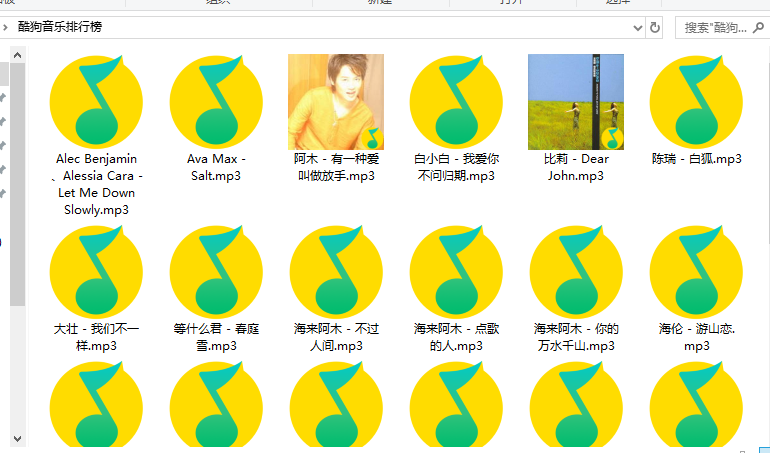
运行代码,效果如下图