前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理

本次目标
爬取去哪了湖南旅游景点信息
https://piao.qunar.com/ticket/list.htm?from=mpshouye_hotdest_more&keyword=%E6%B9%96%E5%8D%97&page=1

环境
- Python3.6
- pycharm
爬虫代码
导入工具
import requests
import parsel
import csv
import time请求网站
url = 'https://piao.qunar.com/ticket/list_%E5%BC%A0%E5%AE%B6%E7%95%8C.html?from=mps_search_suggest_c&keyword=%E5%BC%A0%E5%AE%B6%E7%95%8C&page={}'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)解析网站数据
for page in range(1, 11):
time.sleep(1)
for li in lis:
title = li.css('.sight_item_caption a::attr(title)').get() # 景区名字
dit['景区名字'] = title
level = li.css('.sight_item_info .level::text').get() # 景区等级
dit['景区等级'] = level
area = li.css('.area a::attr(title)').get() # 地区
dit['地区'] = area
address = li.css('.address span::attr(title)').get() # 地址
dit['地址'] = address
string = li.css('.product_star_level em::attr(title)').get() # 热度
star_level = float(string.strip('热度: '))
dit['热度'] = star_level
intro = li.css('.intro::attr(title)').get() # 简介
dit['简介'] = intro
price = li.css('.sight_item_price em::text').get() # 价格
dit['价格'] = price
hot_num = li.css('.hot_num::text').get() # 月销
dit['月销'] = hot_num
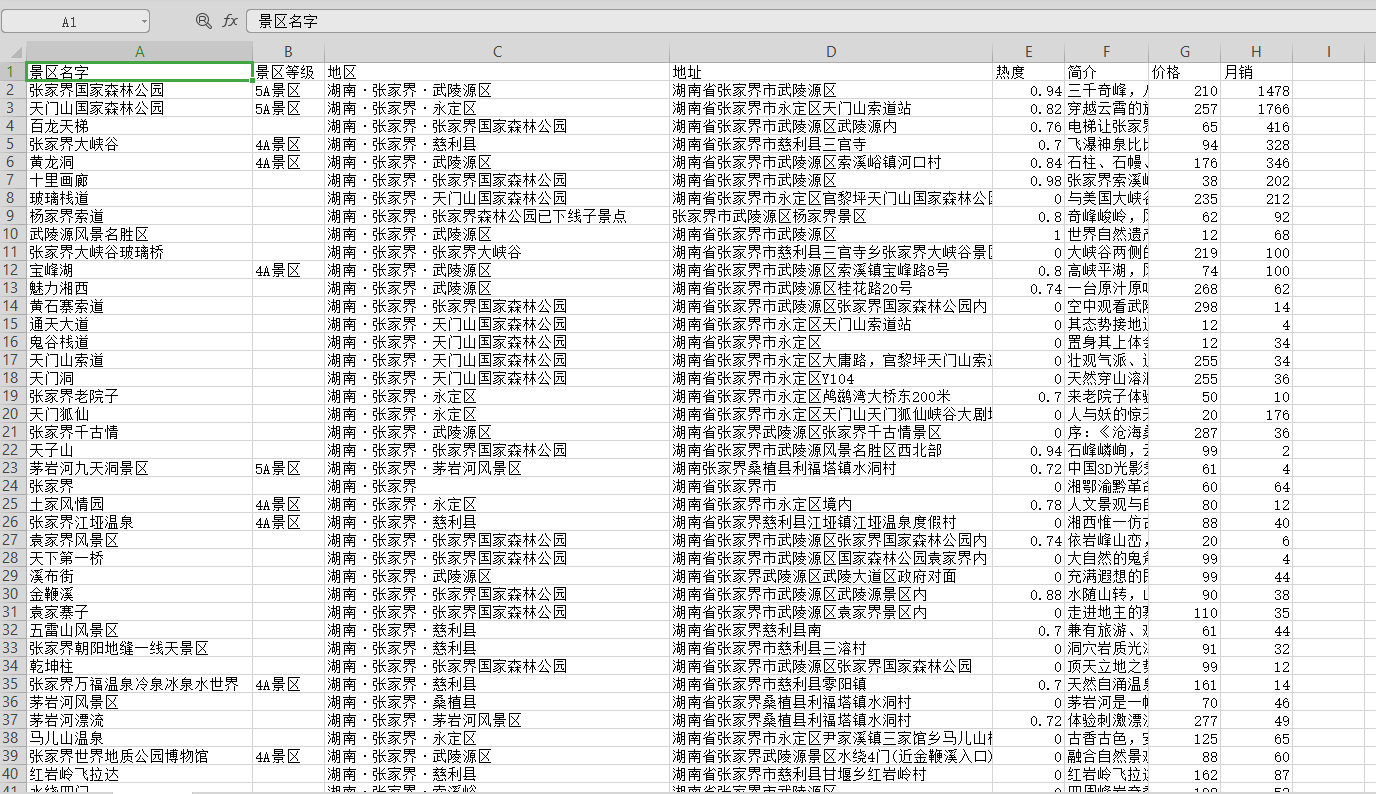
csv_writer.writerow(dit)保存数据
f = open('旅游景点.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['景区名字', '景区等级', '地区', '地址', '热度', '简介', '价格', '月销'])
csv_writer.writeheader()
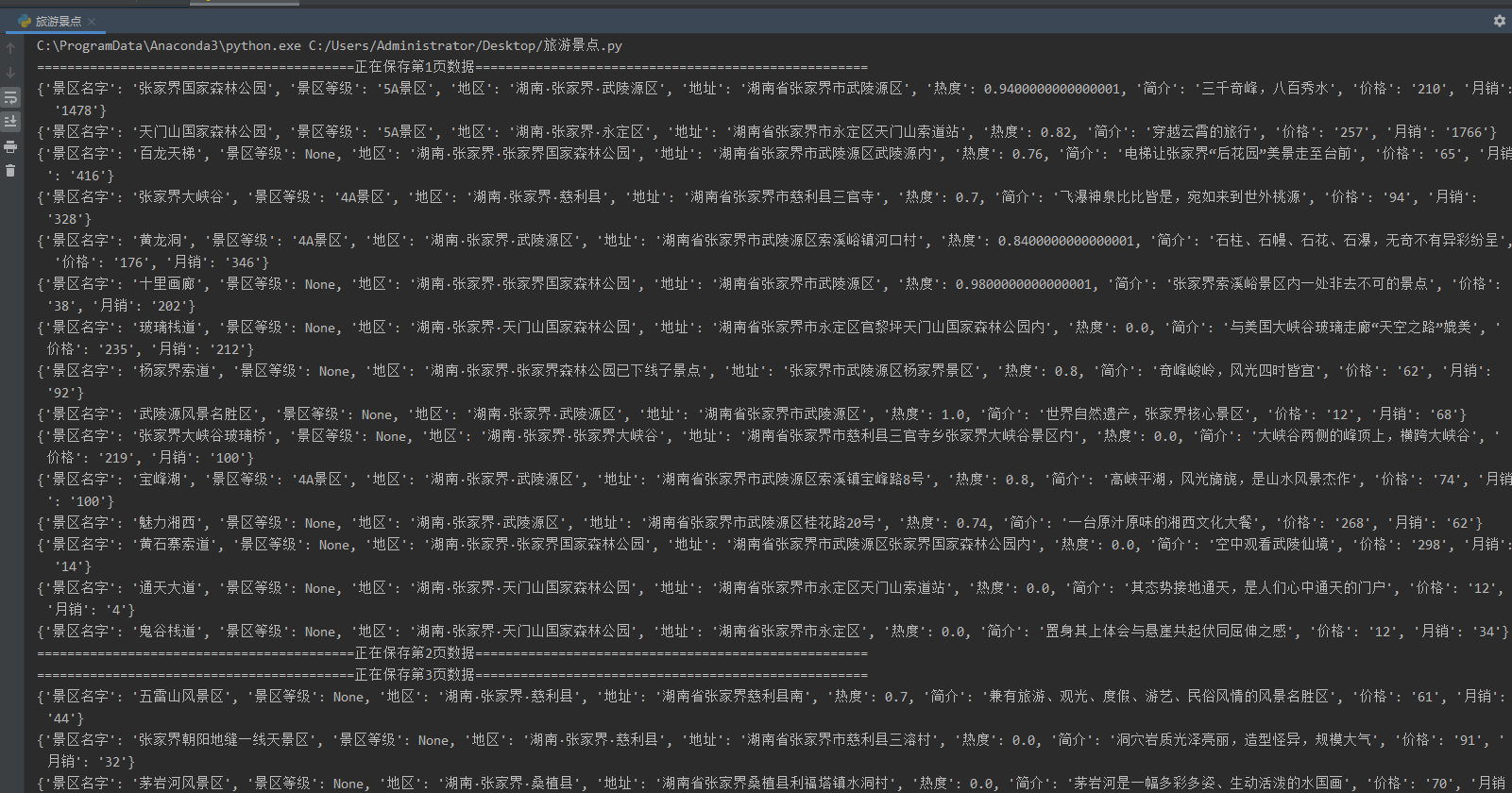
print(dit)运行代码,效果如下图