本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章一级AI入门学习 ,作者小伍哥
刚接触Python的新手、小白,可以复制下面的链接去免费观看Python的基础入门教学视频
https://v.douyu.com/author/y6AZ4jn9jwKW
前言
正则表达式(Regular Expression),就是具有一定规则的表达式。通过正则表达式引擎,将这些规则转换为正则表达式对象,然后再去文本中搜索能够与之匹配的字符串。
正则表达式的语法都是一样的,只是不同编程语言的实现不同,大部分都是师从Perl。
对Perl语言有所了解的朋友,学习python正则应该是手到擒来。
正则表达式入门
Python中的re模块提供了强大的正则表达式功能。
而第三方模块regex提供了与标准库re模块兼容的API接口, 同时还提供了额外的功能和更全面的Unicode支持。

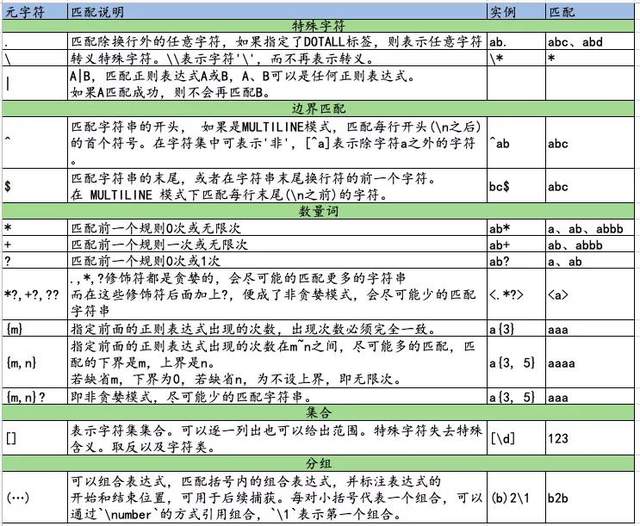
匹配字符
大多数字母和字符只会匹配自身,例如:python只会匹配自己,不会匹配Python。
但是有一些字符串,它们不表示自身,而是具有一些特殊含义,只能通过\转义之后才表示自身。
这些字符包括:
. ^ $ * + ? { } [ ] \ | ( )
【.】
在默认模式中,匹配除换行外所有字符,如果指定了DOTALL标签,则表示任意字符
import re """ re.findall(pattern, string, flags=0) pattern: 匹配规则,字符串 string: 需要去匹配的字符串 从左到右进行扫描,匹配按找到的顺序返回。如果样式里存在一个或多个组,就返回一个组合列表 """ re.findall('ab.', 'abc') # Out[1]: ['abc'] re.findall('ab.', 'ab\n') # Out[2]: [] re.findall('ab.', 'ab\n', re.DOTALL) # Out[3]: ['ab\n']
【^】
匹配字符串的开头, 如果是MULTILINE模式,匹配每行开头(\n之后)的首个符号。
在字符集中可表示'非',[^a]表示除字符a之外的字符。
re.findall('^ab', 'abcda\nabddd') # Out[4]: ['ab'] re.findall('^ab', 'abcda\nabddd', re.MULTILINE) # Out[5]: ['ab', 'ab'] re.findall('[^a]', 'aaa\nbbb') # Out[6]: ['\n', 'b', 'b', 'b']
【$】
匹配字符串的末尾,或者在字符串末尾换行符的前一个字符。
在 MULTILINE 模式下匹配每行末尾(\n之前)的字符。
re.findall('ab$', 'abcdab\nabdab') # Out[7]: ['ab'] # 上面结果中的 ab 是 \n 前面的还是后面的呢?进行如下测试,发现是后面的 ab 被匹配了 re.findall('ab.$', 'abcdab1\nabdab2') # Out[8]: ['ab2'] # 在 MULTILINE 模式下,两个都被匹配了 re.findall('ab$', 'abcdab\nabdab', re.MULTILINE) # Out[9]: ['ab', 'ab'] # 而对 $ 在换行结尾的字符串中匹配时,会得到两个空字符,一个在换行符之前,一个在字符串的末尾 re.findall('$', 'abcdab1\n') # Out[10]: ['', '']
【*】
匹配前一个规则0次或无限次
re.findall('ab*', 'a') # Out[11]: ['a'] re.findall('ab*', 'ab') # Out[12] ['ab'] re.findall('ab*', 'abbbbbbbbbbbbbb') # Out[13] ['abbbbbbbbbbbbbb']
【+】
匹配前一个规则1次或无限次
re.findall('ab+', 'a') # Out[14]: [] re.findall('ab+', 'ab') # Out[15] ['ab'] re.findall('ab+', 'abbbbbbbbbbbbbb') # Out[16] ['abbbbbbbbbbbbbb']
【?】
匹配前一个规则0次或1次
re.findall('ab?', 'a') # Out[17]: ['a'] re.findall('ab?', 'ab') # Out[18] ['ab'] re.findall('ab?', 'abbbbbbbbbbbbbb') # Out[19] ['ab']
【.?,*?,??】
.,*,?修饰符都是贪婪的,会尽可能的匹配更多的字符串
贪婪的我,当然是赞越多越好呀。
而在这些修饰符后面加上?,便成了非贪婪模式,会尽可能少的匹配字符串
re.findall('<.*>', '<a>bcd>') # Out[20] ['<a>bcd>'] re.findall('<.*?>', '<a>bcd>') # Out[21] ['<a>']
{m}
指定前面的正则表达式出现的次数,出现次数必须完全一致。
re.findall('a{3}', 'aa') # Out[22]: [] re.findall('a{3}', 'aaaaa') # Out[23]: ['aaa']
{m, n}
指定前面的正则表达式出现的次数在m~n之间,尽可能多的匹配,匹配的下界是m,上界是n。
若缺省m,下界为0,若缺省n,为不设上界,即无限次。
re.findall('a{3, 5}', 'aaaa') # Out[24]: [] # 3,5 之间不能添加空格 re.findall('a{3,5}', 'aaaa') # Out[25]: ['aaaa'] re.findall('a{3,}', 'aaaa') # Out[26]: ['aaaa'] re.findall('a{,5}', 'aaaa') # Out[27] ['aaaa', '']
{m, n}?
- 即非贪婪模式,尽可能少的匹配字符串。
re.findall('a{3,}?', 'aaaaa') # Out[28] ['aaa']
【\】
- 转义特殊字符。如'\.'只表示.,而不再是表示任意字符。
- 匹配\字符需要转义,用\\表示
re.findall('\.', 'aa') # Out[29] [] re.findall('\.', 'aa.') # Out[30] ['.']
反斜杠灾难:反斜杠具有转义作用,如果需要匹配的字符串中存在多个\,就需要调加相应数量的\来转义
re.findall('\\\\ab', '\\abc') # ['\\ab'] """ 在反复使用反斜杠的正则中,这会导致大量重复的反斜杠, 并使得生成的字符串难以理解。 解决方案: 使用 Python 的原始字符串表示法来表示正则表达式; 'r' 为前缀的字符串,反斜杠不再表示转义 """ re.findall(r'\\ab', '\\abc') # ['\\ab'] re.findall(r'\n', '\n') # ['\n']
[]
表示字符集集合。匹配该字符需要转义\[,\]
# 1、单独列出,匹配 a、b 或 c re.findall('[abc]', 'ab.') # Out[31]: ['a', 'b'] """ 2、字符范围: [a-j]: 表示小写字母 a~j [1-6]:表示数字 1~6 转义: 如 [a\-z] 或者它的位置在首位或者末尾([-a] 或 [a-]),它就只表示普通字符 '-'。 """ re.findall('[a\-z]', '-') # Out[32]: ['-'] re.findall('[-a]', '-') # Out[33]: ['-'] re.findall('[a-]', '-') # Out[34]: ['-'] """ 3、特殊字符失去特殊含义 比如 [(+*)] 只会匹配这几个字符 '(', '+', '*', or ')'。 """ re.findall('[(+*)]', '+-*/()') # Out[35] ['+', '*', '(', ')'] """ 4、字符类 可以使用字符类:\w,\S 等,它们可以匹配的字符由 ASCII 或者 LOCALE 模式决定。 """ re.findall('[\w]', 'abfagg-/*-') # Out[36] ['a', 'b', 'f', 'a', 'g', 'g'] """ 5、取反 如果集合首字符是 '^' ,所有不在集合内的字符将会被匹配 [^^] 将匹配所有字符,除了 '^'. ^ 如果不在集合首位,就没有特殊含义。 """ # 非 \w 定义的字母 re.findall('[^\w]', 'abfagg-/*-') # Out[37] ['-', '/', '*', '-'] """ 6、匹配字符 ']' 两种方法 加上反斜杠 放到集合首位 """ # 加上反斜杠 re.findall('\]', 'abc]') # Out[38] [']'] # 放到集合首位 re.findall('[]{}]', ']abc') # Out[39] [']']
【|】
或。A|B,匹配正则表达式A或B,A、B可以是任何正则表达式。
如果A匹配成功,则不会再匹配B。
匹配|字符需要转义,\|或[|]
re.findall('a|b', 'acb') # Out[40] ['a', 'b'] re.findall('[|]', 'ab|c') # Out[41] ['|']
(...)
小括号,可以组合表达式,匹配括号内的组合表达式,并标注表达式的开始和结束位置,可用于后续捕获
每对小括号代表一个组合,可以通过\number的方式引用组合,\1表示第一个组合。
要匹配字符 ( 或者 ), 用 \( 或 \), 或者放在字符集合里: [(], [)]。
re.findall('a(b+)', 'abbb') # Out[42] ['bbb'] 。 re.findall(r'(b)a\1', 'bab') # Out[43] ['b']
总结