本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章源于明日IT部落 ,作者明日科技
刚接触Python的新手、小白,可以复制下面的链接去免费观看Python的基础入门教学视频
https://v.douyu.com/author/y6AZ4jn9jwKW
前言

最近,由张一山主演的新版《鹿鼎记》被骂上了热搜。这部剧制作班底可以说很厉害,那么为什么评价是这样的?
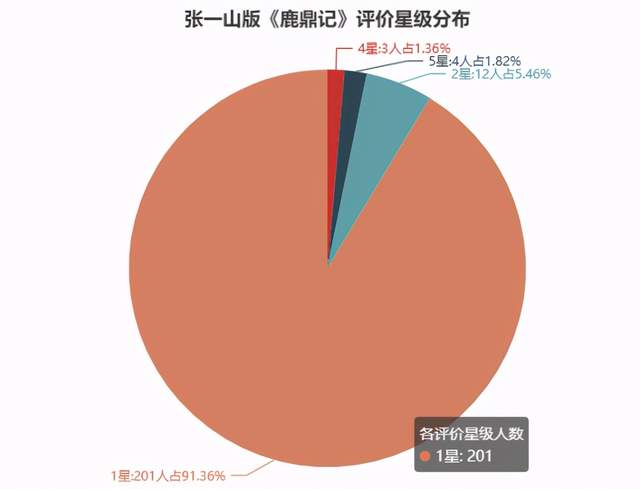
1星居然占到91.36%。
下面再看看评价内容也是五花八门,评价较多的是演技浮夸。

干货来了!下面我们用Python分析新版《鹿鼎记》短评数据,关键代码如下:
import pandas as pd from pyecharts.charts import Pie from pyecharts import options as opts # 导入Excel文件 df = pd.read_excel('ldj.xlsx') # 数据清洗替换评价分值 df.loc[df[df['score'] == 'allstar10 rating'].index,['score']]='1星' df.loc[df[df['score'] == 'allstar20 rating'].index,['score']]='2星' df.loc[df[df['score'] == 'allstar30 rating'].index,['score']]='3星' df.loc[df[df['score'] == 'allstar40 rating'].index,['score']]='4星' df.loc[df[df['score'] == 'allstar50 rating'].index,['score']]='5星' # 按评价星级分组统计并重新设置索引 df1=df.groupby('score').size().reset_index() x_data=df1['score'] y_data=df1[0] # 将数据转换为列表加元组的格式([(key1, value1), (key2, value2)]) data=[list(z) for z in zip(x_data, y_data)] # 数据排序 data.sort(key=lambda x: x[1]) pie=Pie() #创建饼形图 # 为饼形图添加数据 pie.add( series_name="各评价星级人数", # 序列名称 data_pair=data, # 数据 ) pie.set_global_opts( # 饼形图标题居中 title_opts=opts.TitleOpts( title="张一山版《鹿鼎记》评价星级分布", pos_left="center"), # 不显示图例 legend_opts=opts.LegendOpts(is_show=False), ) pie.set_series_opts( # 序列标签 label_opts=opts.LabelOpts( # 标签格式化 formatter="{b}:{c}人占{d}%", ), ) # 渲染图表到HTML文件,存放在程序所在目录下 pie.render("ldj.html")
注:pyecharts模块建议安装1.7.1版本。
使用pip工具安装,命令如下:
pip install pyecharts==1.7.1