本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本品文章来自腾讯云 作者:孤独的明月
内容概览
python3简单爬取百度首页的热搜榜信息
爬取的页面如下: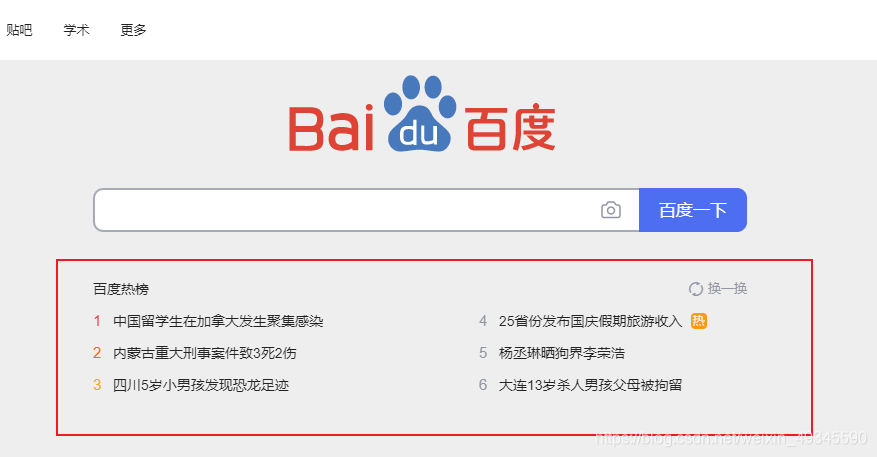
代码如下:
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from datetime import datetime headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36 " } response = requests.get("https://www.baidu.com/", headers=headers) # 解析 bsObj = BeautifulSoup(response.text) # 获取 response header时间 resDate = response.headers.get('Date') print(resDate) # 找到热搜榜 nameList = bsObj.findAll("li", {"class": {"hotsearch-item odd", "hotsearch-item even"}}) # 添加热搜榜的内容 tests = [] for name in nameList: tests.append(name.getText()) # 排序 tests.sort() for news in tests: news = news[0:1] + " : " + news[1:] print(news)
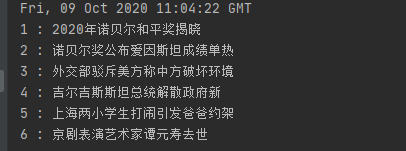
打印出的结果如下: