本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于大邓和他的Python ,作者:大邓
Python爬取知乎数据案例讲解视频
https://www.bilibili.com/video/BV1fz4y1Z7zz/
前言
问题链接
https://www.zhihu.com/question/432119474/answer/1597194524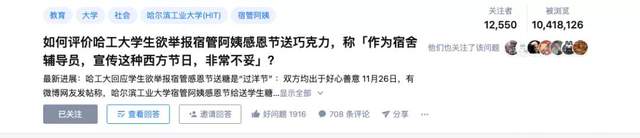

爬虫设计流程
探寻网址规则尝试对某些网页访问解析学术的数据存储到csv整理汇总代码
1.探寻网址规则
- 按F12键打开开发者工具,
- 进入网络面板,点击查看全部6217个回答
- 准备观察开发者工具中的监测到的网址
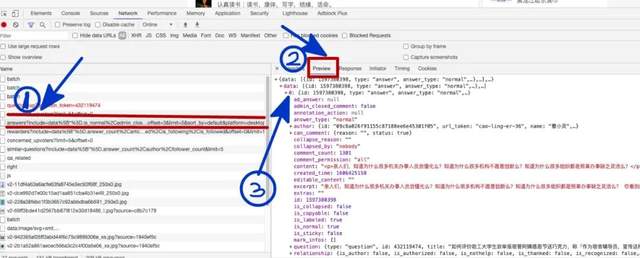
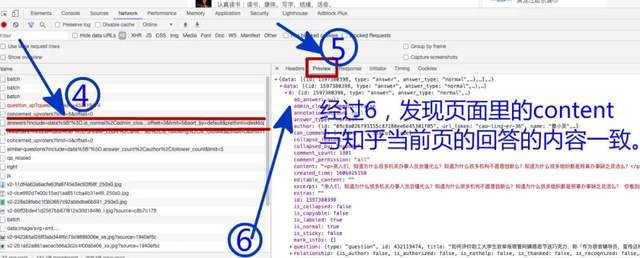
- 对每个网址经过下图456操作
- 点击预览
- 查看内容与当前页面的回答是否一致
- 最终发现网址如7中的红色方框,请求方式为GET方法
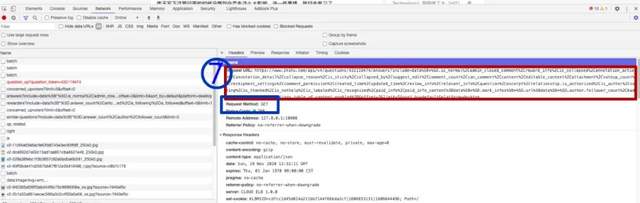
- 依旧是7位于的页面,滑动到最下方,可以看到offset和limit
发现的网址(注意最后一行的偏移)
https://www.zhihu.com/api/v4/questions/432119474/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bsettings.table_of_content.enabled%3B&offset=3&limit=5&sort_by=default&platform=desktop中也存在offset,该单词的意思是偏移量。
- offset我猜测该值数值页面页面数
- limit每个网址能展现多少个回答,至少5个。
网址模板(注意模板内最后一行偏移)
https://www.zhihu.com/api/v4/questions/432119474/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bsettings.table_of_content.enabled%3B&offset={offset}&limit=5&sort_by=default&platform=desktop当前回答一共有6200多个,每页5个,那么offset可以有1240页。
2.尝试对某些网页访问
import requests template = 'https://www.zhihu.com/api/v4/questions/432119474/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bsettings.table_of_content.enabled%3B&offset={offset}&limit=5&sort_by=default&platform=desktop' #for page in range(1, 1240): url = template.format(offset=1) headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36'} resp = requests.get(url, headers=headers) resp
<Response [200]>
我们注意到5种数据可以展开,大概率是json样式的数据。

所以尝试使用resp.json()来拿到格式化的字典数据。
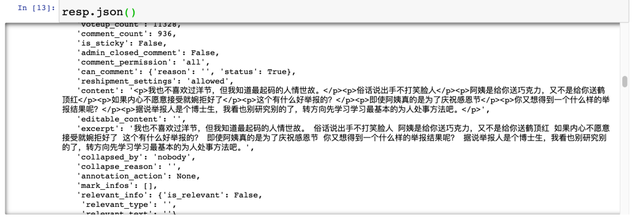
3.解析研究的数据
由于resp.json()返回的是字典,解析定位数据会很方便。
咱们就需求简单点,只采集作者,id,摘录三个变量。
其中作者内部含有很多更丰富的信息,研究的可以把作者再整理下,此处对作者不做过多清洗。
for info in resp.json()['data']: author = info['author'] Id = info['id'] text = info['excerpt'] data = {'author': author, 'id': Id, 'text': text} print(data) {'author': {'id': '10779c1a8b8de0b7f14bb6c217100680', 'url_token': 'da-mo-wang-81-18', 'name': '紧衣卫', 'avatar_url': 'https://pic2.zhimg.com/v2-ebdfa810ec26e81720b8bc14fc6c1d76_l.jpg?source=1940ef5c', 'avatar_url_template': 'https://pic3.zhimg.com/v2-ebdfa810ec26e81720b8bc14fc6c1d76.jpg?source=1940ef5c', 'is_org': False, 'type': 'people', 'url': 'https://www.zhihu.com/api/v4/people/10779c1a8b8de0b7f14bb6c217100680', 'user_type': 'people', 'headline': '梦想太大 心太执着', 'badge': [{'type': 'identity', 'description': '江苏省宝应县公安局 警察', 'topics': []}], 'badge_v2': {'title': '江苏省宝应县公安局 警察', 'merged_badges': [{'type': 'identity', 'detail_type': 'identity', 'title': '认证', 'description': '江苏省宝应县公安局 警察', 'url': 'https://www.zhihu.com/account/verification/intro', 'sources': [], 'icon': '', 'night_icon': ''}], 'detail_badges': [{'type': 'identity', 'detail_type': 'identity_people', 'title': '已认证的个人', 'description': '江苏省宝应县公安局 警察', 'url': 'https://www.zhihu.com/account/verification/intro', 'sources': [], 'icon': 'https://pic1.zhimg.com/v2-235258cecb8a0f184c4d38483cd6f6b6_l.png', 'night_icon': 'https://pic3.zhimg.com/v2-45e870b8f0982bcd7537ea4627afbd00_l.png'}], 'icon': 'https://pic4.zhimg.com/v2-235258cecb8a0f184c4d38483cd6f6b6_l.png', 'night_icon': 'https://pic3.zhimg.com/v2-45e870b8f0982bcd7537ea4627afbd00_l.png'}, 'gender': 1, 'is_advertiser': False, 'follower_count': 3914, 'is_followed': False, 'is_privacy': False}, 'id': 1597225705, 'text': '我也不喜欢过洋节,但我知道最起码的人情世故。俗话说出手不打笑脸人 阿姨是给你送巧克力,又不是给你送鹤顶红 如果内心不愿意接受就婉拒好了 这个有什么好举报的?即使阿姨真的是为了庆祝感恩节 你又想得到一个什么样的举报结果呢?据说举报人是个博士生,我看也别研究别的了,转方向先学习学习最基本的为人处事方法吧。'} {'author': {'id': '09c8a026f91155c87188ee6e45301f05', 'url_token': 'cao-ling-er-36', 'name': '曹小灵', 'avatar_url': 'https://pic1.zhimg.com/v2-942365af26ff3abd44f6c75c9899306e_l.jpg?source=1940ef5c', 'avatar_url_template': 'https://pic2.zhimg.com/v2-942365af26ff3abd44f6c75c9899306e.jpg?source=1940ef5c', 'is_org': False, 'type': 'people', 'url': 'https://www.zhihu.com/api/v4/people/09c8a026f91155c87188ee6e45301f05', 'user_type': 'people', 'headline': '伪商业分析*抽风式咨询*个人成长', 'badge': [{'type': 'identity', 'description': 'Backbase 管理分析咨询师', 'topics': []}], 'badge_v2': {'title': 'Backbase 管理分析咨询师', 'merged_badges': [{'type': 'identity', 'detail_type': 'identity', 'title': '认证', 'description': 'Backbase 管理分析咨询师', 'url': 'https://www.zhihu.com/account/verification/intro', 'sources': [], 'icon': '', 'night_icon': ''}], 'detail_badges': [{'type': 'identity', 'detail_type': 'identity_people', 'title': '已认证的个人', 'description': 'Backbase 管理分析咨询师', 'url': 'https://www.zhihu.com/account/verification/intro', 'sources': [], 'icon': 'https://pic1.zhimg.com/v2-235258cecb8a0f184c4d38483cd6f6b6_l.png', 'night_icon': 'https://pic1.zhimg.com/v2-45e870b8f0982bcd7537ea4627afbd00_l.png'}], 'icon': 'https://pic2.zhimg.com/v2-235258cecb8a0f184c4d38483cd6f6b6_l.png', 'night_icon': 'https://pic2.zhimg.com/v2-45e870b8f0982bcd7537ea4627afbd00_l.png'}, 'gender': 1, 'is_advertiser': False, 'follower_count': 412637, 'is_followed': False, 'is_privacy': False}, 'id': 1597380398, 'text': '亲人们,知道为什么很多机关办事人员会僵化么?知道为什么很多机构不愿意创新么?知道为什么很多组织都是照章办事缺乏灵活么?你看到的这个案例,就是原因。很多事情,你不做,就不会错;做了,取得的回报很少,但是承担的风险很高。你永远不知道什么地方会突然飞过来一泡口水,把你的好意扭曲为恶意,把你的行为定性为「不妥」。如果是在影视行业,不断在边缘疯狂的试探,还可以理解,这样可以给观众带来新的刺激,换来一句…'} {'author': {'id': 'a82cf4ad4be905dbc044297e70e3b382', 'url_token': 'alyssa-song', 'name': '貂丝女婶教授', 'avatar_url': 'https://pic4.zhimg.com/v2-2b1a52a861aecec566a3c2c4f00a5e06_l.jpg?source=1940ef5c', 'avatar_url_template': 'https://pic2.zhimg.com/v2-2b1a52a861aecec566a3c2c4f00a5e06.jpg?source=1940ef5c', 'is_org': False, 'type': 'people', 'url': 'https://www.zhihu.com/api/v4/people/a82cf4ad4be905dbc044297e70e3b382', 'user_type': 'people', 'headline': '985副教授,少女型大妈,生化环材', 'badge': [], 'badge_v2': {'title': '', 'merged_badges': [], 'detail_badges': [], 'icon': '', 'night_icon': ''}, 'gender': 0, 'is_advertiser': False, 'follower_count': 10200, 'is_followed': False, 'is_privacy': False}, 'id': 1597237844, 'text': '我从前就住在哈工大的17公寓。宿管阿姨们真的非常好,非常温暖。我当时有一段生病天天待在寝室,阿姨们白天巡寝的时候还经常问我好点了没有,用不用帮我从楼下带盒饭上来。对我这种从小就缺爱的人,阿姨真的就像自己的亲人一样,让我从内心深处感觉到了家的温暖。住在17公寓的日子真的超级美好。当年哈工大的后勤管理还有一点很好,就是每一届毕业的学生把不穿也不带走的旧大衣捐给学校,新一届本科生入校时候,贫困生可以每人…'} {'author': {'id': 'e6bbeff00614e94be5225c9fb401f989', 'url_token': 'zai-yi-qi-61-23', 'name': '精分的曹小灵', 'avatar_url': 'https://pic4.zhimg.com/v2-d3325d2f1d7de8511a5e9a328c75a539_l.jpg?source=1940ef5c', 'avatar_url_template': 'https://pic2.zhimg.com/v2-d3325d2f1d7de8511a5e9a328c75a539.jpg?source=1940ef5c', 'is_org': False, 'type': 'people', 'url': 'https://www.zhihu.com/api/v4/people/e6bbeff00614e94be5225c9fb401f989', 'user_type': 'people', 'headline': '头脑中存在两种截然相反的思想,开始精分', 'badge': [], 'badge_v2': {'title': '', 'merged_badges': [], 'detail_badges': [], 'icon': '', 'night_icon': ''}, 'gender': 1, 'is_advertiser': False, 'follower_count': 4997, 'is_followed': False, 'is_privacy': False}, 'id': 1597348175, 'text': '啊…又来了。对这种道德高地站的稳的学生,张博洋曾经发出过灵魂质问:[图片] [图片] 宿管阿姨明确的说了:这是西方的节日,自己是借着这个节日的机会,感谢同学们对工作的支持。现在很多女生找各种借口过节,很多男生找各种借口送礼,怎么就不能让宿管阿姨给你一个不想奋斗的机会呢?这种人,不配当个男人,至少不配当一个新时代的以阿姨包养为梦想的好男人。你背叛了你的阶级!手动差评!要上纲上线,别急,咱们一层一层的来。先讲历…'} {'author': {'id': '0ba346aab1e8761d12e8d1cf28fce8f8', 'url_token': 'xia-xiao-qi-61', 'name': '瞄小七.sunshine', 'avatar_url': 'https://pic2.zhimg.com/v2-fc018e46c81d7828e65d34613f62425c_l.jpg?source=1940ef5c', 'avatar_url_template': 'https://pic4.zhimg.com/v2-fc018e46c81d7828e65d34613f62425c.jpg?source=1940ef5c', 'is_org': False, 'type': 'people', 'url': 'https://www.zhihu.com/api/v4/people/0ba346aab1e8761d12e8d1cf28fce8f8', 'user_type': 'people', 'headline': '三甲医院手术室护师/护理学穿搭博主', 'badge': [], 'badge_v2': {'title': '', 'merged_badges': [], 'detail_badges': [], 'icon': '', 'night_icon': ''}, 'gender': 0, 'is_advertiser': False, 'follower_count': 9792, 'is_followed': False, 'is_privacy': False}, 'id': 1598254838, 'text': '[图片] 举报这个事,小题大做。本来是一件在寒冬天里温暖人心的好事,也不知道是触动了一个脑回路清奇之人的哪根敏感神经?这位举报爱好者就这样愤愤地向宿管阿姨发出了最后通牒。我心里还在想呢,这么有爱的宿管阿姨,果然是别人学校的宿管阿姨。没想到,有这样的宿舍阿姨,有些同学非但不知珍惜,还要上纲上线举报她。那位举报阿姨的同学,平时心里应该很苦嘴巴才这么毒吧?是自己生活过的太平淡无为才用这种方式在善良的宿管阿…'}
4.存储到csv
设置三个细分,存储到csv。
注意现在只是对某些页面的数据进行的存储。
import csv csvf = open('zhihu.csv', 'a+', encoding='utf-8', newline='') fieldnames = ['author', 'id', 'text'] writer = csv.DictWriter(csvf, fieldnames=fieldnames) writer.writeheader() for info in resp.json()['data']: author = info['author'] Id = info['id'] text = info['excerpt'] data = {'author': author, 'id': Id, 'text': text} writer.writerow(data) csvf.close()
5.整理汇总代码
将1234代码合并整理,就是一个对知乎问题回答的批量采集爬虫。
注意复制标签代码,要注意层次关系,上下变量名要对应衔接接。
import requests import csv import time #新建csv,存储数据 csvf = open('zhihu.csv', 'a+', encoding='utf-8', newline='') fieldnames = ['author', 'id', 'text'] writer = csv.DictWriter(csvf, fieldnames=fieldnames) writer.writeheader() #伪装头,用于反爬 headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36'} #网址模板 template = 'https://www.zhihu.com/api/v4/questions/432119474/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bsettings.table_of_content.enabled%3B&offset={offset}&limit=5&sort_by=default&platform=desktop' #批量采集, #目前可爬1240+页数据 #这里仅抓取前100页 for page in range(1, 100): #对第page页进行访问 url = template.format(offset=page) resp = requests.get(url, headers=headers) #解析定位第page页的数据 for info in resp.json()['data']: author = info['author'] Id = info['id'] text = info['excerpt'] data = {'author': author, 'id': Id, 'text': text} #存入csv writer.writerow(data) #降低爬虫对知乎的访问速度 time.sleep(1) #关闭csvf csvf.close()
测试
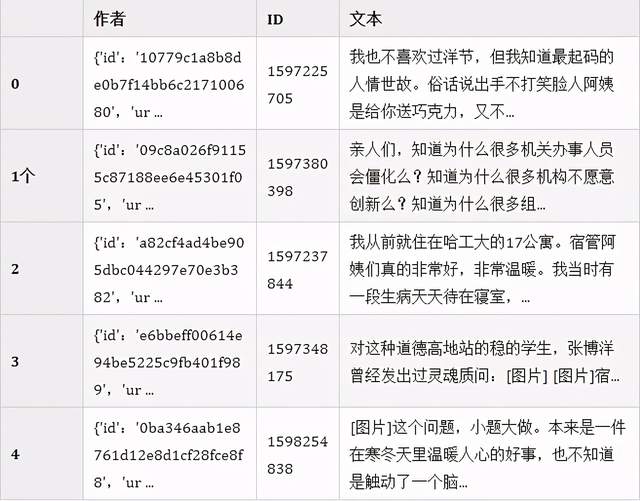
采集完毕后,我们检查下zhihu.csv,看看是否采集到的数据。
import pandas as pd df = pd.read_csv('zhihu.csv') df.head()
词云图
找出所有回答的内容文本,制作词云图,可以看到知乎用户对哈工大感恩节事件的看法。
import jieba import json from pyecharts import options as opts from pyecharts.charts import WordCloud text_contents = ''.join(df['text']) words = jieba.lcut(text_contents) words = [w for w in words if len(w)>1] wordfreqs = [(w, words.count(w)) for w in set(words)] c = ( WordCloud() .add("", wordfreqs, word_size_range=[10, 70]) .set_global_opts(title_opts=opts.TitleOpts(title="哈工大感恩节")) .render_notebook() )
