前言
本文的文字及图片过滤网络,可以学习,交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于青灯编程 ,作者:清风
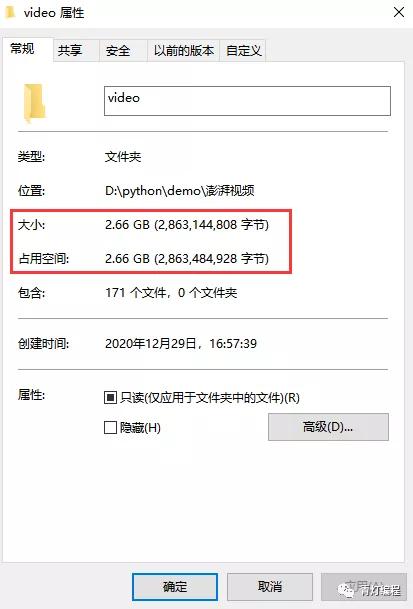


如上图所示,爬取171个视频,共计2.6G的内存大小,用时仅有88秒,还不到一分半。
基本开发环境
- Python 3.6
- 皮查姆
相关模块的使用
import re import time import requests import concurrent.futures
相关模块pip安装即可。
完整代码
import re import time import requests import concurrent.futures def get_response(html_url): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'} response = requests.get(url=html_url, headers=headers) return response def save(video_url, video_title): filename = 'video\\' + video_title + '.mp4' video_data = get_response(video_url).content with open(filename, mode='wb') as f: f.write(video_data) print('正在保存:', video_title) def main(html_url): html_data = get_response(html_url).text lis = re.findall('<div id="(\d+)" class="newslv_share">', html_data) for li in lis: page_url = f'https://www.thepaper.cn/newsDetail_forward_{li}' page_data = get_response(page_url).text video_url = re.findall('<source src="(.*?)" type="video/mp4"/>', page_data)[0] video_title = re.findall('<h2>(.*?)</h2>', page_data)[0] save(video_url, video_title) end_time = time.time() use_time = end_time - start_time print('总共耗时:', use_time) if __name__ == '__main__': start_time = time.time() executor = concurrent.futures.ThreadPoolExecutor(max_workers=5) for page in range(1, 11): url = f'https://www.thepaper.cn/load_video_chosen.jsp?channelID=26916&pageidx={page}' executor.submit(main, url) executor.shutdown()
完整代码已经给了,自己的感受〜,我这还是使用的5个线程,你给10个线程效率会更高,可以一分钟不到就可以爬完了
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542