本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
作者:努力学习的渣渣哦
来源:胆小鬼
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542

前言
前段时间的《大江大河2》非常火,但是由于《大江大河1》我没有看过,也就激不起我想看的欲望。但是最近更新的《山海情》,我周五晚上点进去,然后一口气看了6集原声版的,22点开始看,每集40min,问几点睡?
该剧讲述了二十世纪九十年代以来,在国家扶贫政策的引导下,在福建的对口帮扶下,西海固的人民群众移民搬迁,不断克服各种困难,探索脱贫发展办法,将风沙走石的“干沙滩”建设成寸土寸金的“金沙滩”的故事。----剧集官方介绍
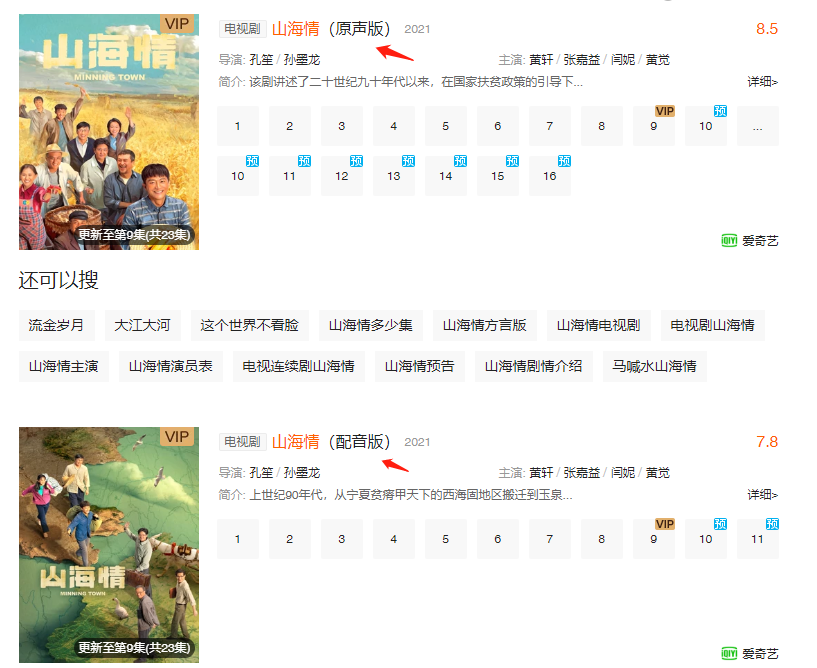
原声版就是台词是用宁夏那边的方言讲述的,配音版是普通话版的,推荐原声版的,会更有那种打动人心的感觉。《山海情》讲最动人的扶贫故事。
2021年是“十四五”开局之年,也是全面建设社会主义现代化国家新征程开启之年,还是建党100周年。《大江大河》、《山海情》作为献礼片,这么受欢迎,可见拍的质量有多高。同样题材的还有《跨过鸭绿江》《江山如此多娇》等。

孔笙导演,正午阳光出品......都是精品,演员每一个都是老戏骨,一点注水的那种演员都没有。
目前更新到第九集,爬下第一集的弹幕,看看大家都在说什么。
1.找弹幕在哪?
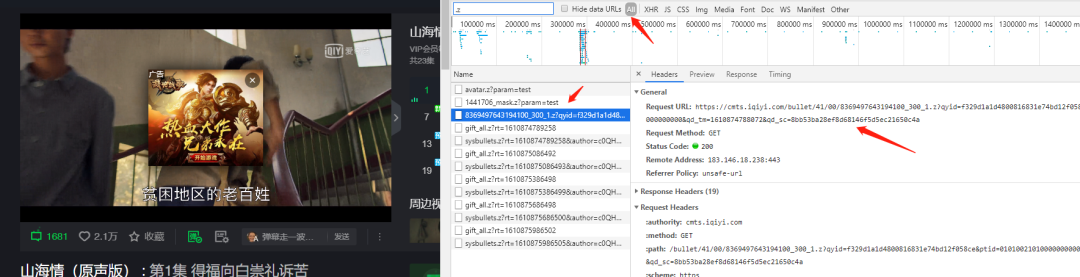
重点是搜索【.z】,不一样的是找到的“Request URL”打开是个压缩包,里面含有弹幕内容,所以程序里面会有解压这一步。
2.程序
import requests import pandas as pd import zlib import re import time def get_aiqiyi_danmu(tvid): """ 功能:给定tvid,获取爱奇艺一集的弹幕评论信息 """ # 建立空df df_all = pd.DataFrame() # 初始page_num page_num = 1 while True: # 打印进度 print(f'正在获取第{page_num}页的弹幕数据') try: # 获取URL url = f'https://cmts.iqiyi.com/bullet/{str(tvid)[-4:-2]}/{str(tvid)[-2:]}/{str(tvid)}_300_{page_num}.z' # 添加headers headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36' } # 发起请求 try: r = requests.get(url, headers=headers, timeout=3) except Exception as e: print(e) r = requests.get(url, headers=headers, timeout=3) # 转换为arrry zarray = bytearray(r.content) # 解压字符串 xml = zlib.decompress(zarray, 15+32).decode('utf-8') # 用户名 name = re.findall('<name>(.*?)</name>', xml) # 评论ID contentId = re.findall('<contentId>(.*?)</contentId>', xml) # 评论信息 content = re.findall('<content>(.*?)</content>', xml) # 展示时间 showTime = re.findall('<showTime>(.*?)</showTime>', xml) # 点赞次数 likeCount = re.findall('<likeCount>(.*?)</likeCount>', xml) # 保存数据 df_one = pd.DataFrame({ 'name': name, 'contentId': contentId, 'content': content, 'showTime': showTime, 'likeCount': likeCount }) # 循环追加 df_all = df_all.append(df_one, ignore_index=True) # 休眠一秒 time.sleep(1) # 页数+1 page_num += 1 except Exception as e: print(e) break return df_all # 抓包获取视频tvid tvid_list = [8369497643194100] episodes_list = ['第一集 ' ] # 循环获取所有集数据 for tvid, episodes in zip(tvid_list, episodes_list): print(tvid, episodes) # 获取数据 df = get_aiqiyi_danmu(tvid=tvid) # 插入列 df.insert(0, 'episodes', episodes) # 导出数据 df.to_csv(f'df_{episodes}.csv')
只爬取单集输入tvid就可以了,连续获取集数需要再获取url,再从返回的结果中
获取tvid3.结果

遮住的是用户名称。
简单的画下词云

总之就是推荐,看完之后觉得现在的生活真美好,没有什么比以前更苦的年代了。